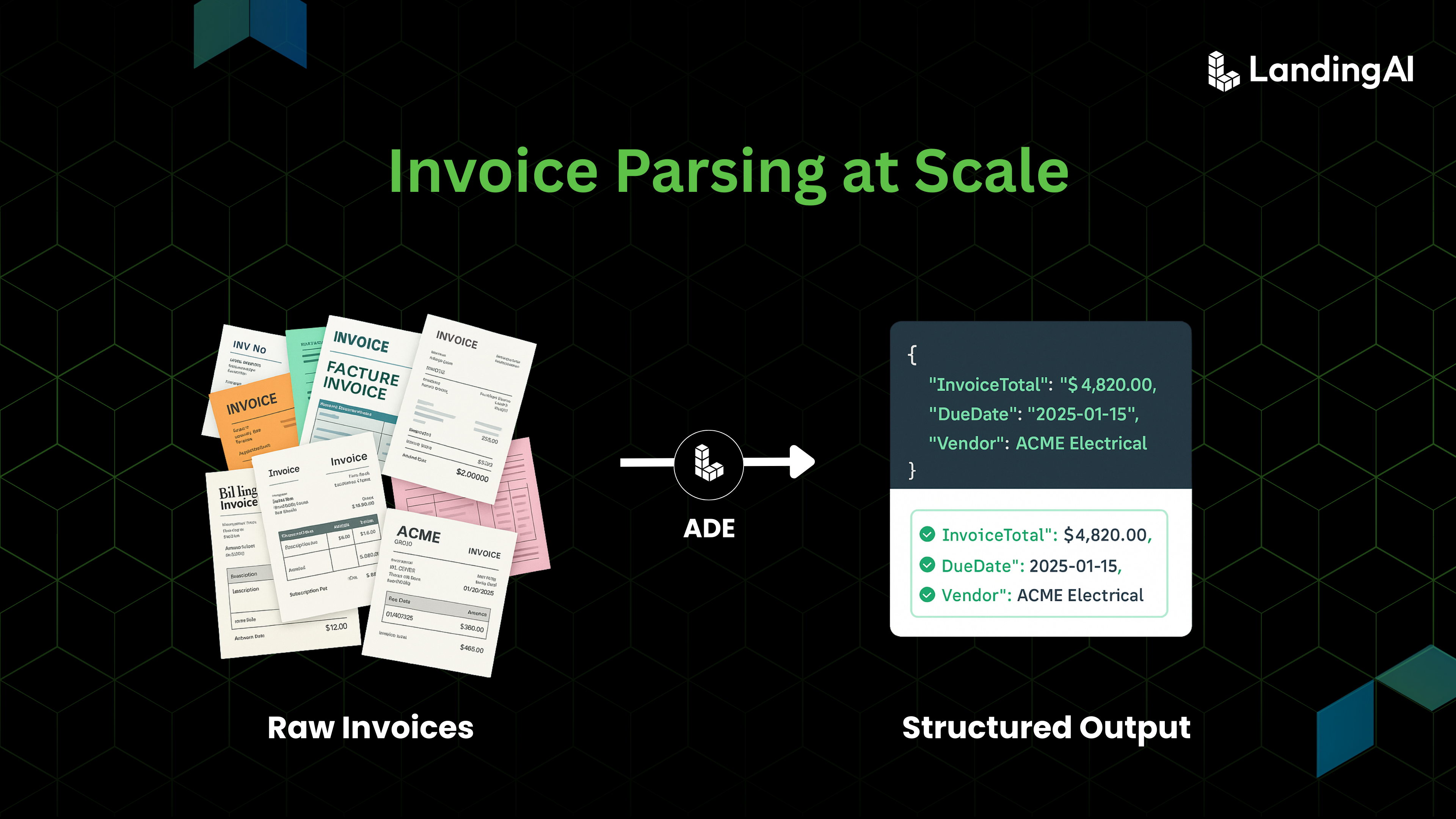
TL;DR
Manual KYC document processing remains a major bottleneck for financial institutions, costing time, money, and customers. According to a 2025 industry survey, 70% of banks worldwide report losing potential clients due to slow or inefficient onboarding linked to KYC processes, and the average time to complete an initial corporate KYC review can reach 95 days. These delays also drive high operational costs. Together, these inefficiencies demand better solutions to scale verification workflows.
Agentic Document Extraction (ADE), powered by LandingAI’s proprietary Document Pre-Trained Transformer (DPT) model family, approaches documents visually. It interprets text, tables, and figures in context and organizes them into structured chunk types such as card for IDs, table for aligned data grids, and logo or attestation for seals and signatures, enabling consistent extraction across identity proofs, address documents, and financial statements. This layout-aware parsing delivers accurate, auditable data at scale, helping teams reduce manual review, accelerate onboarding, and improve compliance readiness across high-volume KYC workflows.
Introduction
In today’s regulated financial world, KYC is essential to building trust and managing risk. Organizations must verify identities, confirm addresses, and review financial documents quickly and accurately — without slowing onboarding.
Processing KYC documents isn’t a single-document task. It’s a bundle of identity proofs, address proofs, and financial statements that all need to be read, cross-checked, and validated. A typical onboarding flow includes passports, driver’s licenses, utility bills, and bank statements, each with its own layout, language, and noise.
Manually reviewing these documents is tedious and time-consuming. Verifying names, photos, and addresses across multiple files slows onboarding and often leads to human error. As the number of applicants grows, this manual process quickly becomes unscalable and inconsistent.
Traditional OCR or template-based systems try to automate the task but often fail under this diversity. They lose layout context, struggle with new formats, and still produce outputs that need manual correction — creating more friction than relief.
That’s where ADE from LandingAI comes in. Built to handle real-world document complexity, ADE brings a vision-based approach that understands layout, context, and relationships between fields and documents, making KYC automation accurate, consistent, and scalable.
Overview of ADE
ADE, powered by LandingAI’s proprietary DPT models, introduces a new way to understand and extract information from documents. Rather than treating a document as a flat stream of text or relying on rigid templates, ADE interprets it as a visual representation of information — preserving structure, layout, and spatial context that traditional OCR systems often lose.
The DPT (Document Pre-Trained Transformer) models are trained on large, diverse sets of real-world documents. They enable ADE to recognize not only text but also layout relationships and visual elements such as tables, checkboxes, signatures, barcodes, and even complete ID cards or forms. Each of these components is represented as a structured “chunk,” allowing ADE to parse a document into semantically meaningful sections that align with how humans naturally read it.
In KYC workflows, this becomes especially powerful. A single KYC packet can contain multiple document types — from an ID card or passport to a utility bill or bank statement — each with different structures and layouts. ADE handles all of them consistently, and you can even extract specific fields like name, address, or expiration date across these documents to cross-check and validate information while maintaining spatial integrity.
The result is structured, reliable data that reflects the document’s true layout. This visual and contextual understanding makes it possible to automate the complex parsing and cross-verification steps that KYC processes depend on, ensuring both accuracy and traceability at scale.
Next, let’s see ADE in action across KYC documents.
ADE in Action
KYC workflows revolve around two key categories of documents — proof of identity and proof of address. Let’s see how ADE applies the same vision-first logic to both, understanding layout, structure, and relationships between fields, regardless of how complex the document appears.
Proof of Identity
Identity proofs like passports, national IDs, and driver’s licenses form the foundation of every KYC process. These are structured documents that combine printed text, photos, signatures, and sometimes encoded zones like MRZs or barcodes, all of which must be read accurately to confirm who the customer is.
Let’s take the U.S. Military Identification Card, a compact document that brings together text, seals, a photograph, and a signature box, all within a single layout. For most OCR or rule-based systems, this mix of fonts, overlapping graphics, and stamped patterns can cause misreads.
When parsed with ADE, the document is recognized through the card chunk type, which understands the layout as a whole.
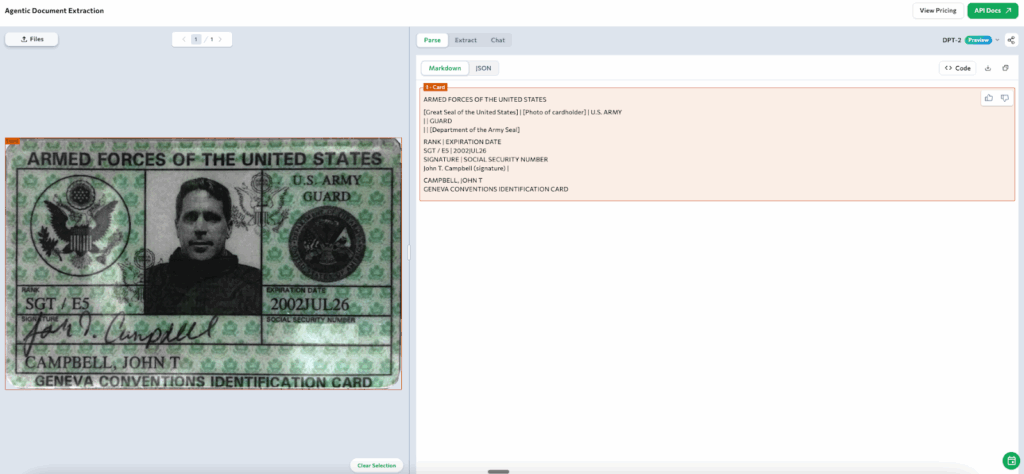
In a real KYC verification flow, this becomes practical. Suppose the process only requires checking the expiration date to confirm document validity. You define that single field in the schema and extract only what’s needed. Here, the extracted value is “2002-07-26,” which, as you can see, indicates the ID has expired — a simple yet crucial check that can be fully automated.
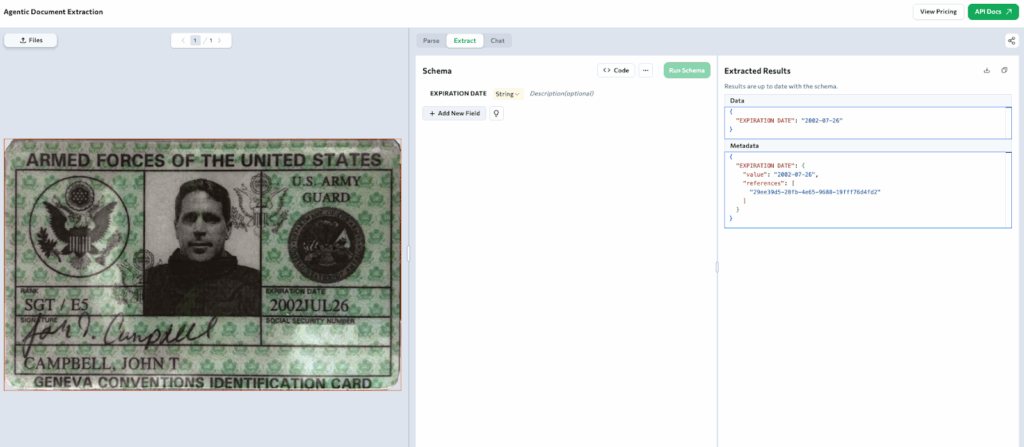
This approach keeps extraction focused, fast, and accurate, cutting down manual review and reducing the chances of human error while maintaining consistency across identity document types.
Driver’s licenses are another challenge entirely. Each issuing country and region has its own design, field placement, and data format. Instead of relying on templates, ADE identifies visual and layout cues such as photo position, table regions, logos, and attestations like signatures, and represents those elements as structured chunk types. This allows it to generalize to new or updated license designs and enables downstream extraction and verification to continue without retraining.
For a deeper look at how ADE parses different identity documents, check out our detailed blog on Extracting Data from Identity Documents.
Proof of Address
Once identity is verified, the next step in KYC is confirming where a customer lives. Proof-of-address documents are often varied and unstructured — from clean, single-page utility bills to multi-page statements with nested tables and long text blocks. Despite this variety, ADE can read them all consistently, understanding layout, visual grouping, and the data relationships on each page.
Utility Bill
Let’s start with a utility bill. ADE identifies multiple chunk types on the page — a logo region, text fields like the customer name and service address, and structured sections like Bill Summary, Account Information, and Amount Due. Each element is automatically classified and extracted while preserving its visual position on the document.

You can see how the system captures the logo, address block, and billing information as separate, organized chunks rather than flattening them into text. That spatial awareness matters because in production KYC flows, the address on a bill must often be matched with the one from a submitted ID. Here, every extracted value remains tied to its source region on the document, creating a transparent audit trail.
This layout-aware parsing ensures that nothing is lost in translation: text, structure, and placement are all retained. For compliance teams, that means address verification becomes a simple automated check that is accurate, explainable, and grounded.
Bank Statement
Bank statements push layout complexity even further. These documents blend long paragraphs with transaction tables, column headers, and summary boxes, formats that tend to break traditional OCR or coordinate-based templates. You can see ADE identifies tables visually, detecting headers like Date, Description, Debit, Credit, and Balance even when borders are faint or missing.
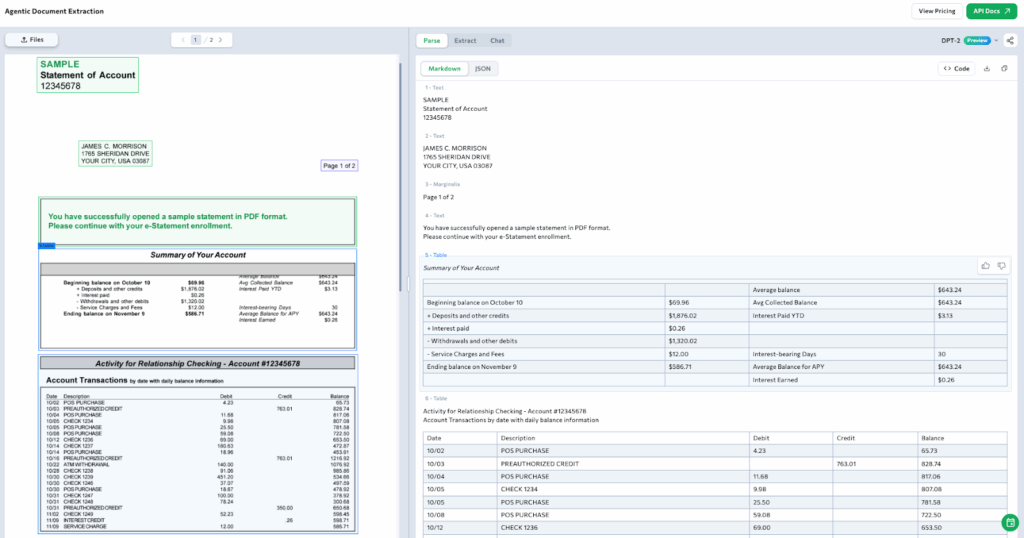
Once parsed, every row of transactions becomes structured. This allows downstream systems to compute summaries, balances, or spending patterns instantly. And if you only need specific fields, such as the account holder’s name or account number, you can define those fields in a simple extraction schema. ADE isolates them directly..
This level of precision removes the need for manual review of multi-page statements while maintaining traceability for audits and compliance checks.
Credit Card Statement
Now, consider a credit card statement, similar to a bank statement but packed with payment schedules, summary tables, and account details.
ADE recognizes these as separate visual groups: the header with customer details, the Payment Information box, and the Account Summary tables.
Using field-level schemas, verification teams can then extract only the information that matters, such as the customer’s name, address, or account number, to confirm proof of residence and maintain consistency across documents.
By treating each proof-of-address document as a visually structured layout, ADE brings clarity to what was once a manual, error-prone task. This ensures the outputs remain clean, contextual, and audit-ready — exactly what regulated KYC workflows demand.
Try your own KYC documents through the ADE Playground
What Makes KYC Documents Uniquely Hard
KYC workflows are some of the most demanding in automation. Unlike single-document scenarios, they combine multiple proofs — identity, address, and financial — each with its own layout, structure, and quirks.
A mix of document types.
Customers don’t submit one form of proof. They upload passports, driver’s licenses, utility bills, bank statements, and more. Each follows a different format and visual style. Supporting a global customer base means handling hundreds of ID designs and thousands of document templates that vary by country, issuer, or even utility provider.
Multi-modal content.
KYC documents are not just text. They mix printed and handwritten fields, tables, photos, barcodes, and security seals. A driver’s license might include an embedded barcode, while a bank statement packs dense tables and transaction grids. Extracting data accurately means understanding both visual and textual signals.
Frequent format updates.
Documents evolve. Governments roll out new ID versions every few years. Utility providers change statement layouts or add new branding. Each update can throw off static OCR or template-based pipelines. A robust system needs to adapt to these shifts without manual reconfiguration.
Cross-document consistency.
KYC verification doesn’t stop at one document. A name, address, or ID number needs to match across multiple files. A mismatch between a passport and a proof-of-address may indicate a simple typo — or a fraud attempt. Automating that correlation reliably is one of the hardest parts of KYC automation.
Imperfect inputs.
Users often upload documents taken from phone cameras under poor lighting. Blurred images, glare, or cropped edges make extraction harder. A reliable system must handle these real-world conditions without breaking downstream logic.
Compliance and data retention.
KYC doesn’t just require accurate extraction — it requires traceability. Regulators expect every field to be auditable, every decision explainable, and every document securely stored for years. Systems need to deliver accuracy and compliance together, not one at the expense of the other.
Why Traditional Approaches Struggle with KYC Documents
KYC document processing involves more than just reading text. It includes identity proofs, address proofs, and financial statements, each with its own format and structure. Traditional tools were built for simpler, static documents and often fail when faced with this variety.
- Manual review is still common in many verification workflows. Reviewers check names, match photos, and confirm addresses across multiple pages. The process takes time, is difficult to scale, and leaves plenty of room for human error.
- OCR-based extraction works well for clean, uniform text but falls apart with real-world layouts. On ID cards, it can misread text over holograms or watermarks. On utility bills and bank statements, it flattens tables and headers, making it impossible to reliably associate values like account numbers, dates, or totals.
- Template-driven systems rely on static coordinates and fixed layouts. They perform well until something changes — a new design for a driver’s license, a shifted address block on a bill, or an updated logo on a bank statement. Each variation demands maintenance and manual tuning, which quickly becomes unmanageable.
- Rule-based logic tries to compensate for document diversity by layering exceptions on top of exceptions. Over time, this turns into a brittle system where even small format tweaks or font updates can break the workflow.
- LLM-only approaches add reasoning capabilities but lack visual understanding. Without seeing the layout, they may confuse field labels with values or fabricate missing details. For regulated KYC processes, where each extracted value must link back to its source, that’s a critical limitation.
These older systems share the same weakness: they can’t see documents as structured visual data. KYC requires more than text recognition — it needs understanding of spatial layout, relationships, and validation across document types. That’s exactly where ADE’s vision-based approach makes the difference.
Real-World Needs and Expectations
Organizations that automate KYC aren’t only chasing speed; they’re managing risk, regulation, and customer trust. Their needs go well beyond extracting text correctly.
Accuracy and consistency.
Banks and financial platforms need near-perfect extraction. Even minor mismatches in identity data can trigger compliance reviews or onboarding delays. The system must catch issues early, from typos in names to mismatched addresses, with minimal human intervention.
Auditability and compliance.
Every decision in a KYC workflow must be explainable. A modern extraction system should visually link every output field to the specific region of the source document, with all steps logged and time-stamped. This audit trail isn’t optional; regulators require it for multi-year record retention.
Speed and scalability.
Onboarding often happens in bursts, with thousands of applications in a day. A KYC pipeline must scale seamlessly while maintaining consistent accuracy. Users expect results in seconds, not minutes, without compromising verification quality.
Data privacy and security.
KYC documents carry sensitive personal data. Systems must handle data securely, encrypt it in transit and at rest, and comply with local storage and retention requirements. Compliance with data localization laws is now as critical as extraction accuracy.
Smooth integration into user workflows.
For modern onboarding flows, extraction runs behind the scenes. Whether the document comes from a phone camera, a scanned PDF, or an uploaded image, the backend should process it instantly and feed clear results back to the user.
Global coverage.
A single KYC system must handle documents from multiple regions, languages, and formats without relying on rigid templates. Instead of managing a large template library, the system should generalize to new layouts automatically — something ADE’s layout-aware foundation is built for.
Conclusion
KYC workflows bring together some of the most complex documents in automation — identity proofs, address proofs, and financial records — each with its own structure and verification requirements. Traditional OCR, template-based, or text-only systems struggle to keep up with this variety, leading to errors, delays, and compliance risks.
ADE changes that equation. It brings a vision-first understanding of documents, parsing each one into structured, semantic chunks that preserve layout and meaning. From MRZ validation on passports to table extraction in bank statements, ADE handles text, images, and layout together, producing outputs that are consistent, auditable, and ready for downstream verification.
The result is faster onboarding, fewer manual checks, and a transparent audit trail for every extracted field. For teams building scalable and compliant KYC pipelines, ADE offers a practical foundation.
Ready to get started?
Test ADE live with your KYC documents in the Visual Playground.