
Accuracy you can prove, not guess
Agentic Document Extraction (ADE) delivers high accuracy with confidence score and audit-ready traceability.
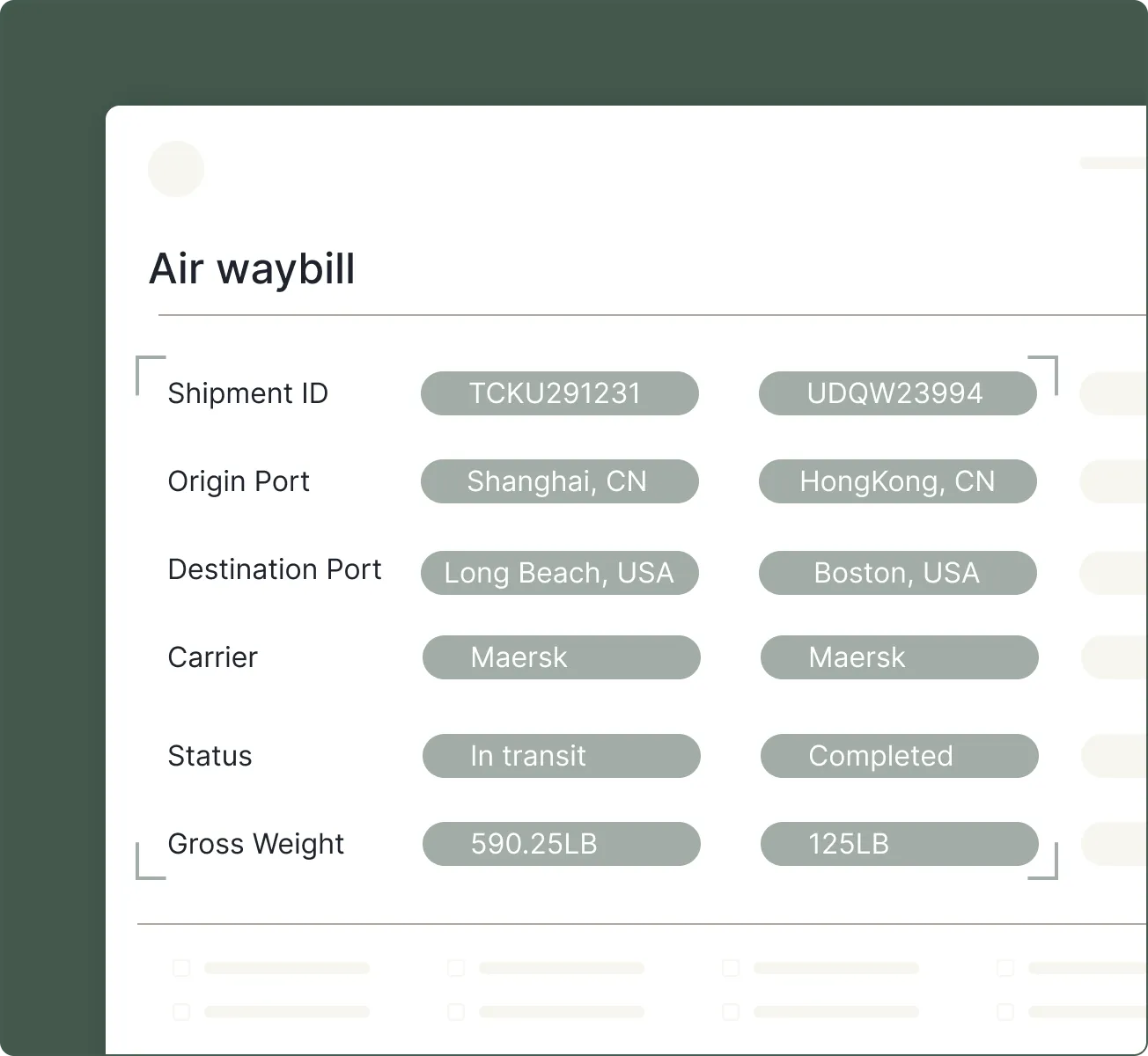
Accuracy on complex docs
Proven on real-world layouts, complex tables, and multi-page documents delivering consistent results in production, not just in benchmarks.
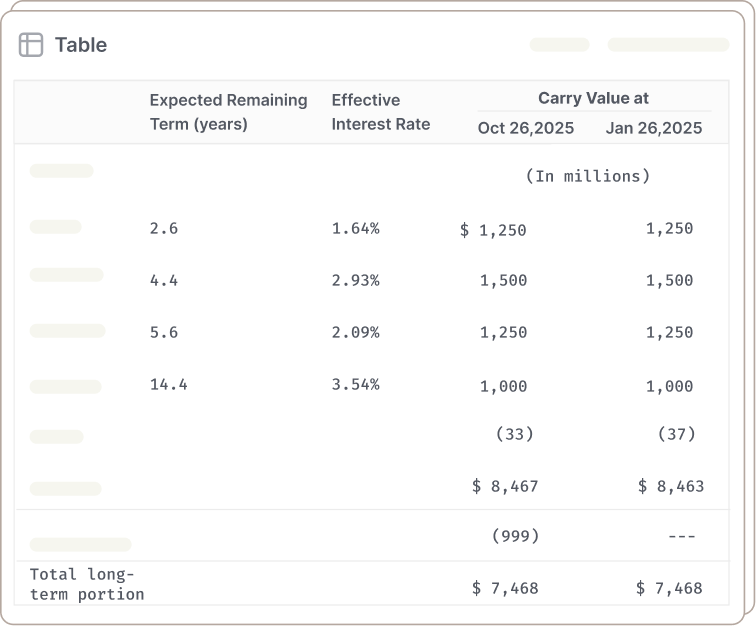
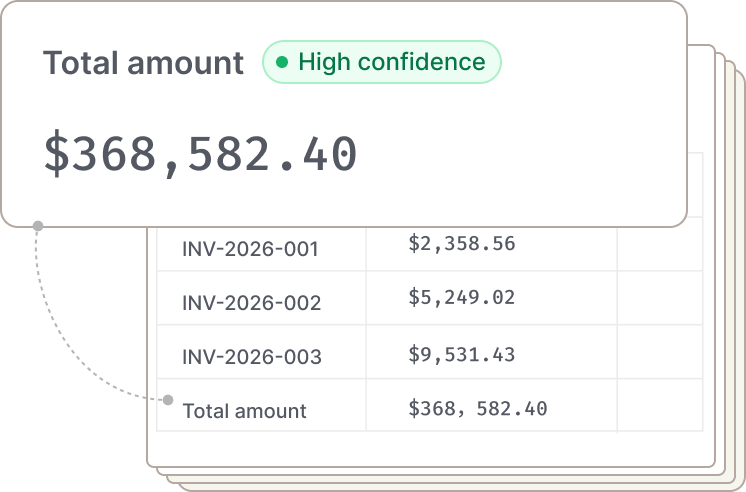
Results come with proof
Verify parsed results with page numbers and precise coordinates for each chunk. Confidence scoring surfaces results that may need human review.
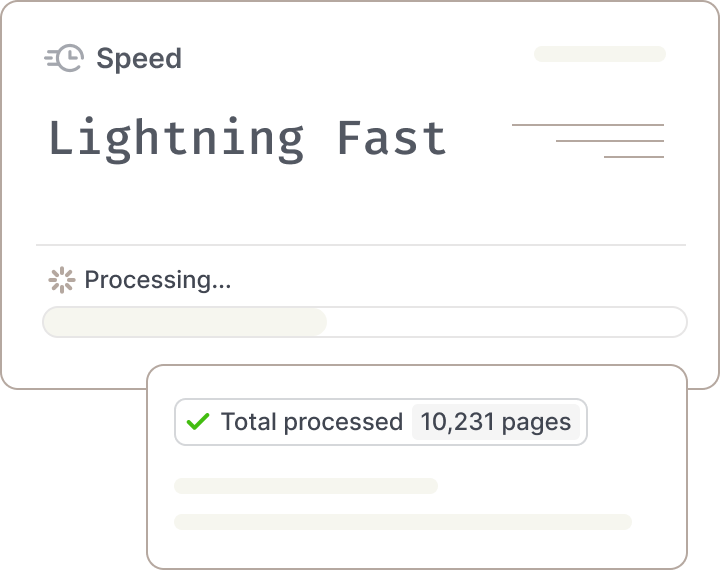
Unmatched speed & scale
Eliminate processing bottlenecks and scale effortlessly. ADE handles thousands of pages per minute.
APIs designed for real workflows
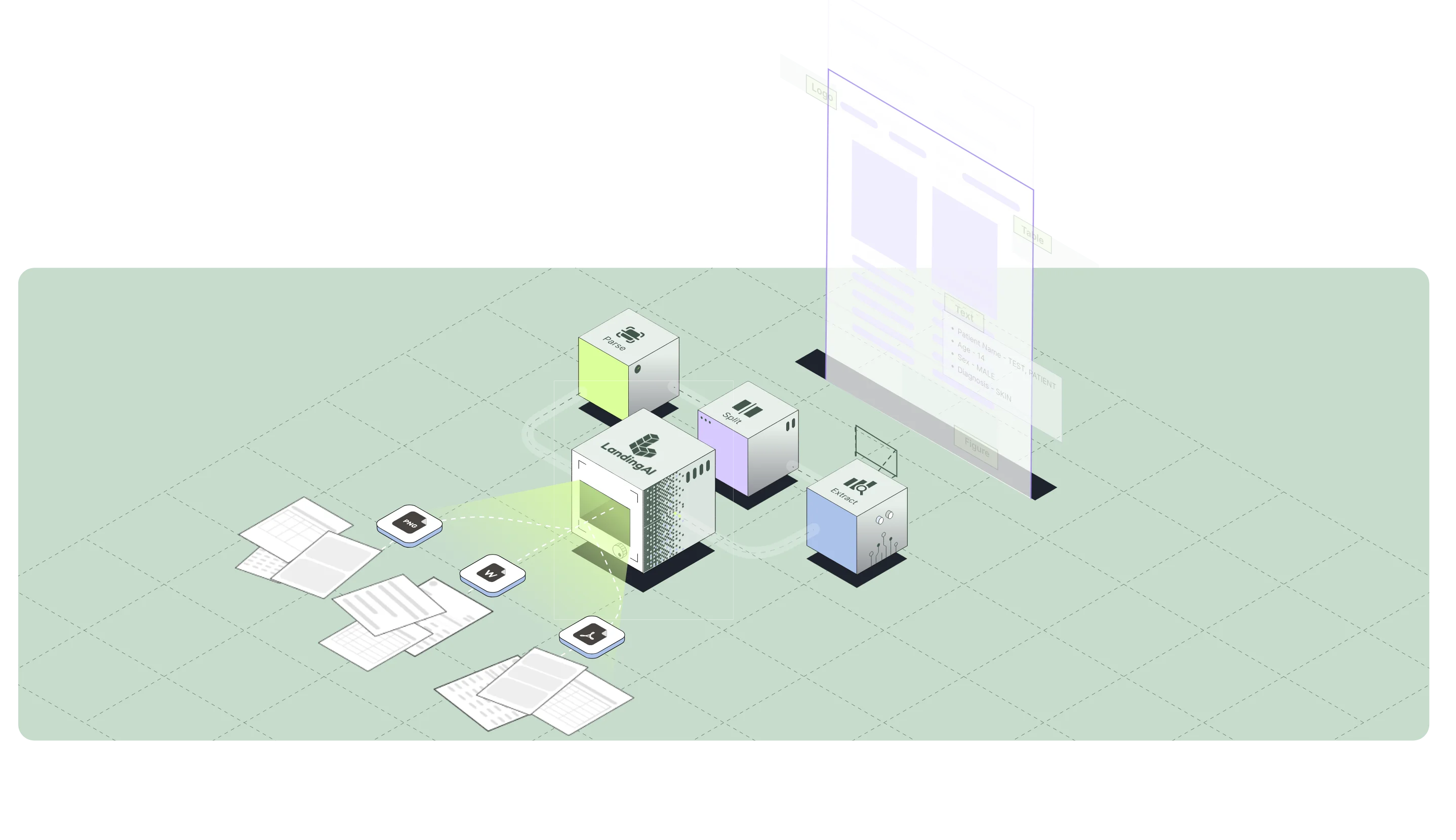
An end-to-end API to parse, split, and extract structured data from any document.
Convert variable documents into accurate, auditable structured data.
- LLM-ready Markdown with layout-aware structure
- Structured content blocks including text, tables, and figures, with hierarchy preserved
- Precise citations for every block (page, coordinates, and table-cell grounding)
- Handles layout variability across scans, dense tables, forms, and multi-format documents

Automatically segment multi-document files into clean, classified sub-documents.
- Large-file splitting for long, multi-hundred-page batches
- Classification across mixed document types within a single PDF
- Instance detection using repeated identifiers (e.g., invoice number, date, order ID)

Extract specific fields using schema you define.
- Schema-first extraction (flat or nested, arrays, multi-table)
- Large table extraction (thousands of rows across many pages)
- Auditability by default with bounding-box citations per value

Build what comes next
Power downstream workflows with structured, traceable outputs. Integrate easily via modular REST APIs and Python or TypeScript libraries.
Retrieval-augmented generation (RAG)
Accurate retrieval powered by semantic chunking for deeper context.
Automation and downstream workflows
Reconciliation, compliance checks, reporting, and approvals—without manual reviews.
Search and analytics
Turn document archives into queryable, structured datasets.
One platform, endless applications
Specialized APIs across industries and use cases—without rebuilding pipelines for every new document format.
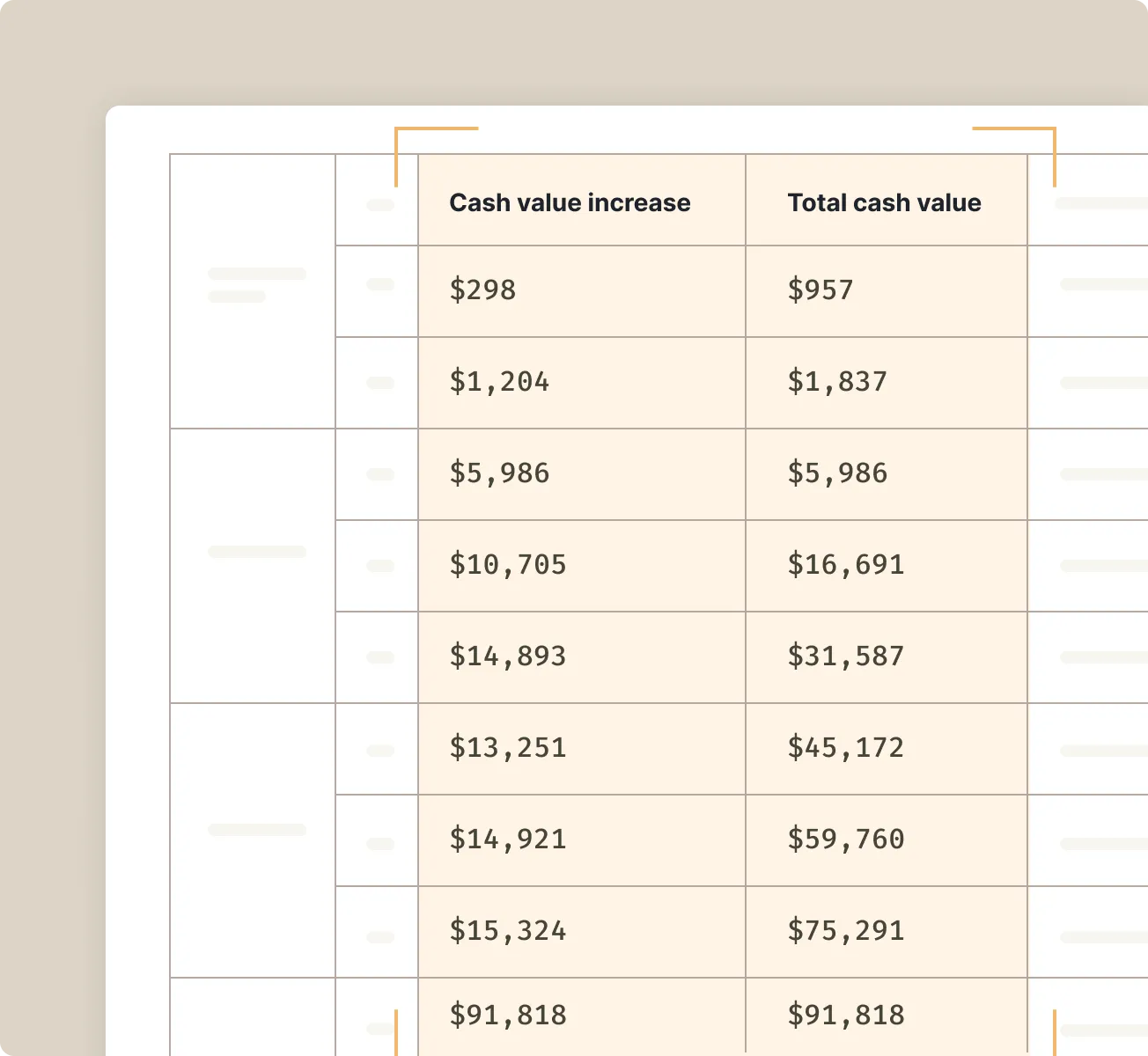
Financial services
Accurately capture key figures, risk indicators, and transaction details, even from complex tables and multi-page documents.

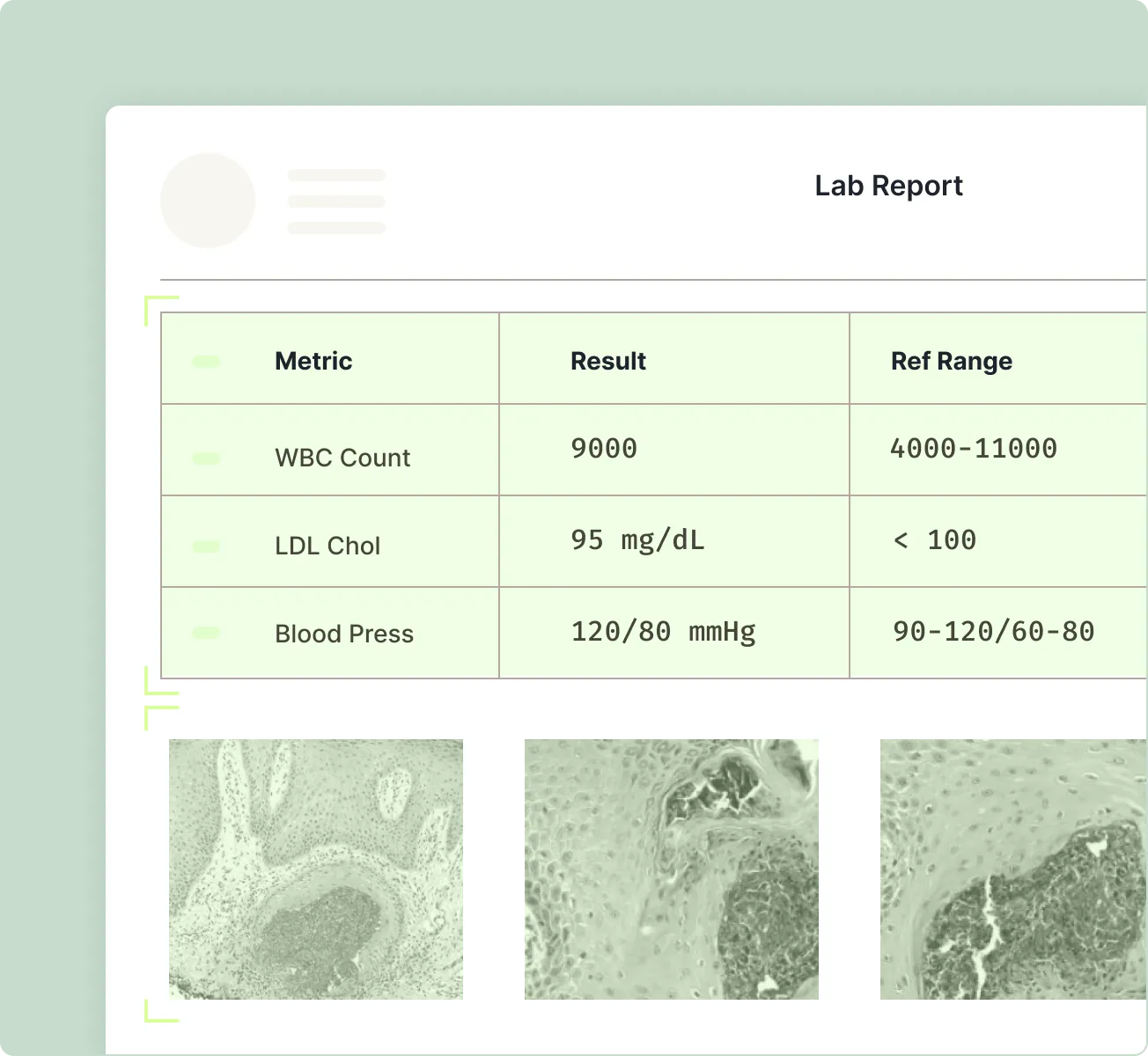
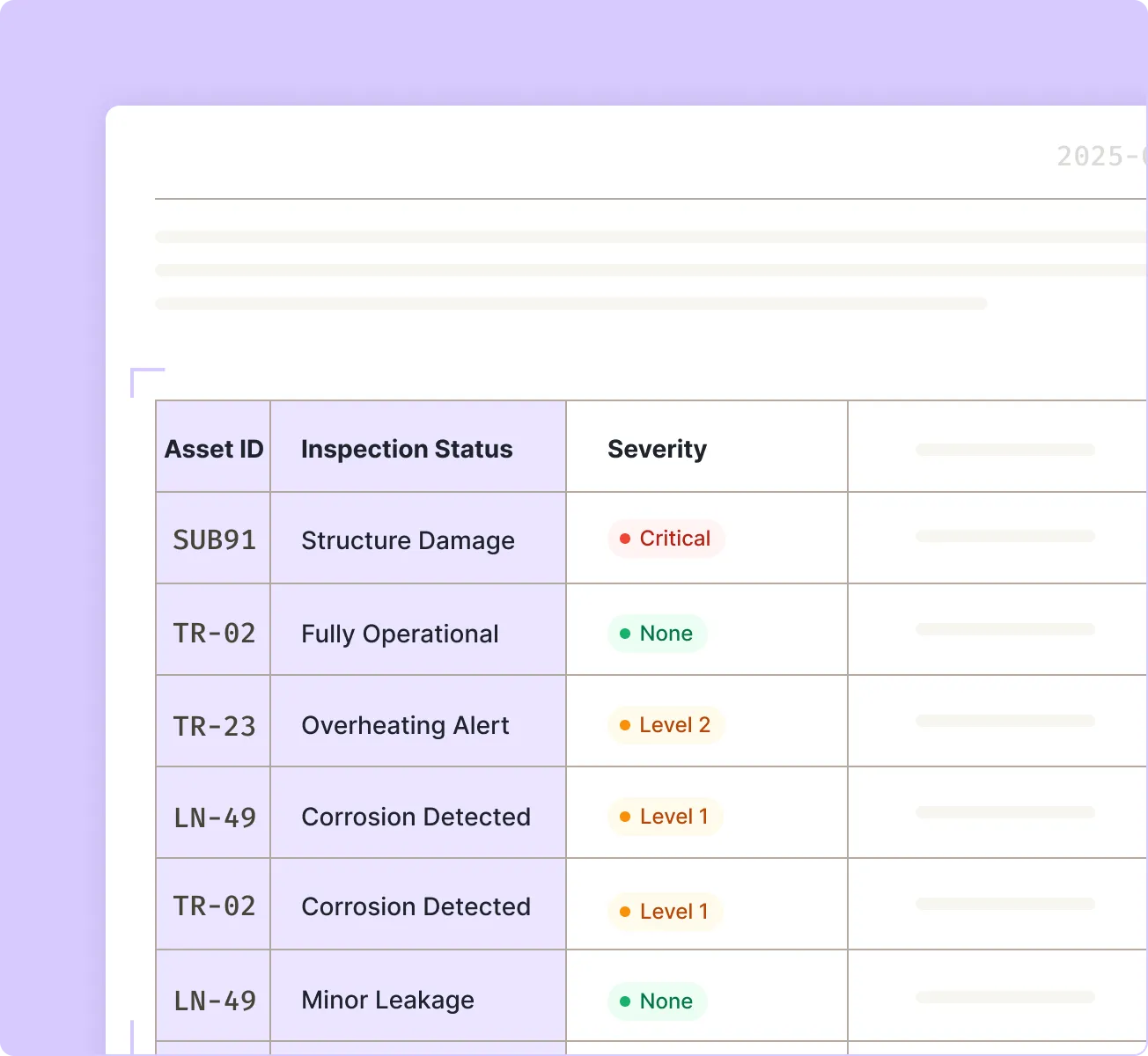

Trusted autonomous document processing
Built for regulated, high-variance documents where accuracy, traceability, and governance matter.
Vision-first
Our proprietary vision models reliably extract data from complex tables, dense layouts, and multi-page documents. Our system improves accuracy faster through built-in feedback and control.
Data-centric
Accuracy improves through better, curated data, while failure cases are captured, audited, and systematically fed back to reduce errors and rework.
Agentic by design
One size doesn’t fit all. Agentic orchestration adapts to each document. Planning, deciding, and verifying until quality thresholds are met.
Enterprise security, startup speed
Designed for regulated environments without slowing down teams.
SOC 2 Type II
Certified secure
GDPR & HIPAA
Compliant by design
Flexible Deployment
Cloud, on-premises, or virtual private deployment options
Data Privacy
Zero data retention option
Trusted by teams who move fast
Over 50+ enterprise customers trust LandingAI to stay ahead of document processing. We beat the industry with <2 second processing time.
Very often a loan officer who gets a borrower a solid preapproval fastest earns the deal and the real estate agent’s referrals. Reconstructing income is the hardest part, and Agentic Document Extraction is the cornerstone to getting it right and traceable. Accurate data upfront means we can get a cleaner loan file to the underwriter and get to CTC faster. Get it wrong and everything downstream gets affected.”
View case study →
Agentic Document Extraction has proven to be both accurate and easy to use. We are building on that foundation to deliver reliable, transparent, and scalable automation that our customers can validate and trust.”
View case study →
Trust is the product. Accuracy alone isn’t enough at enterprise scale—what matters is provenance, traceability, and control. LandingAI gives us confidence that every extracted value can be traced back to its source, audited, and defended. That’s what makes it deployable in regulated, real-world environments.”
View case study →Our Plan Review Agent has a lot of complicated components under the hood: traversing building code knowledge graphs, reasoning across disciplines and sheets, assessing issues informed by historical projects. None of it works if we can’t trust what came off the page. ADE gave us a reliable foundation, so our team could focus on incorporating our team’s expertise into our compliance reasoning system.”
View case study →
ADE has significantly outperformed other document extractors we’ve used. It has helped us build an Agentic RAG answer engine, based on unique healthcare institutional content, to offer instant, validated support to medical professionals at the point of care.”
View case study →
I appreciate its reliability and the fact that they're constantly innovating with new models, which helps us work smarter. The service is essential for handling heavy workloads in financial institutions as it provides the necessary infrastructure for high accuracy and fast throughput. I also find it adaptable to specific use cases because they're always working on new models.”

We use LandingAI's Agentic Document Extraction to build pipelines that turn unstructured text into structured data. First, the NER (Named Entity Recognition) detection has amazing accuracy. Second, the OCR capability is excellent — earlier I had to run a separate PDF extractor for text plus a separate LLM with OCR to summarize images, and now it's one step. Third, the image boundary detection is a standout.”

We ran a structured bake-off: the same five PDFs (ranging from a 12-page slide deck to a 400-page machinery manual) processed through other products and Landing AI's Agentic Document Extraction (ADE). We scored each tool on four criteria: Table fidelity, Figure extraction, Chunk typing, Scale. Landing AI ADE was the only tool that scored well on all four.”

Very often a loan officer who gets a borrower a solid preapproval fastest earns the deal and the real estate agent’s referrals. Reconstructing income is the hardest part, and Agentic Document Extraction is the cornerstone to getting it right and traceable. Accurate data upfront means we can get a cleaner loan file to the underwriter and get to CTC faster. Get it wrong and everything downstream gets affected.”
View case study →Agentic Document Extraction has proven to be both accurate and easy to use. We are building on that foundation to deliver reliable, transparent, and scalable automation that our customers can validate and trust.”
View case study →Trust is the product. Accuracy alone isn’t enough at enterprise scale—what matters is provenance, traceability, and control. LandingAI gives us confidence that every extracted value can be traced back to its source, audited, and defended. That’s what makes it deployable in regulated, real-world environments.”
View case study →Our Plan Review Agent has a lot of complicated components under the hood: traversing building code knowledge graphs, reasoning across disciplines and sheets, assessing issues informed by historical projects. None of it works if we can’t trust what came off the page. ADE gave us a reliable foundation, so our team could focus on incorporating our team’s expertise into our compliance reasoning system.”
View case study →ADE has significantly outperformed other document extractors we’ve used. It has helped us build an Agentic RAG answer engine, based on unique healthcare institutional content, to offer instant, validated support to medical professionals at the point of care.”
View case study →I appreciate its reliability and the fact that they're constantly innovating with new models, which helps us work smarter. The service is essential for handling heavy workloads in financial institutions as it provides the necessary infrastructure for high accuracy and fast throughput. I also find it adaptable to specific use cases because they're always working on new models.”
We use LandingAI's Agentic Document Extraction to build pipelines that turn unstructured text into structured data. First, the NER (Named Entity Recognition) detection has amazing accuracy. Second, the OCR capability is excellent — earlier I had to run a separate PDF extractor for text plus a separate LLM with OCR to summarize images, and now it's one step. Third, the image boundary detection is a standout.”
We ran a structured bake-off: the same five PDFs (ranging from a 12-page slide deck to a 400-page machinery manual) processed through other products and Landing AI's Agentic Document Extraction (ADE). We scored each tool on four criteria: Table fidelity, Figure extraction, Chunk typing, Scale. Landing AI ADE was the only tool that scored well on all four.”
