Intelligent Document Processing in Retail Banking

TL;DR
Retail banking involves a wide range of document-heavy processes, including loan applications, credit card approvals, customer onboarding, and compliance checks. Traditional OCR and rule-based systems often fall short when processing these documents due to inconsistent formats, handwritten inputs, and layout variations. Agentic Document Extraction (ADE) by LandingAI brings structure and reasoning to this complexity by interpreting documents visually and contextually. By preserving layout and spatial context, ADE ensures that every field is extracted with precision and presented in a clean, structured JSON format, enabling faster processing, fewer errors, and scalable automation across banking operations.
Introduction
Retail banking spans many lines of business: mortgages and home loans, vehicle and personal loans, credit cards, insurance add-ons, customer onboarding and KYC, transaction disputes, and regulatory reporting. Each of these areas relies heavily on documents including identity proofs, application forms, income statements, bank records, and compliance reports, all of which must be reviewed, verified, and processed accurately.
Manual review, legacy OCR tools, and rule-based systems continue to dominate these operations in many banks. But they are brittle and slow when faced with real-world complexity such as scanned PDFs, handwritten fields, mismatched layouts, or overlapping content. As a result, teams spend hours per document cycle, and errors slip through. Loan approvals get delayed, KYC checks pile up, and compliance reporting becomes a costly bottleneck.
Agentic Document Extraction (ADE) by LandingAI is designed for this kind of complexity. ADE is Visual AI-First. It treats documents as visual and spatial entities, not just blocks of text. It identifies chunks like tables, text regions, and signatures, and understands how they relate on the page. By preserving layout and spatial context, ADE extracts structured fields with clarity and consistency, even when formats vary across documents.
According to a recent study published in the International Journal of Management & Entrepreneurship Research, banks using AI-driven document processing reported up to 70 percent faster loan approvals, onboarding time reduced from weeks to as little as 3 to 4 days, and up to 40 percent lower compliance costs due to reduced manual handling and fewer errors.
In this blog, we will explore how ADE enables accurate, layout-aware extraction across key retail banking processes, from multi-page loan documents and credit card applications to onboarding records, dispute forms, and regulatory reports.
ADE in Retail Banking
Mortgage and Home Loan Processing
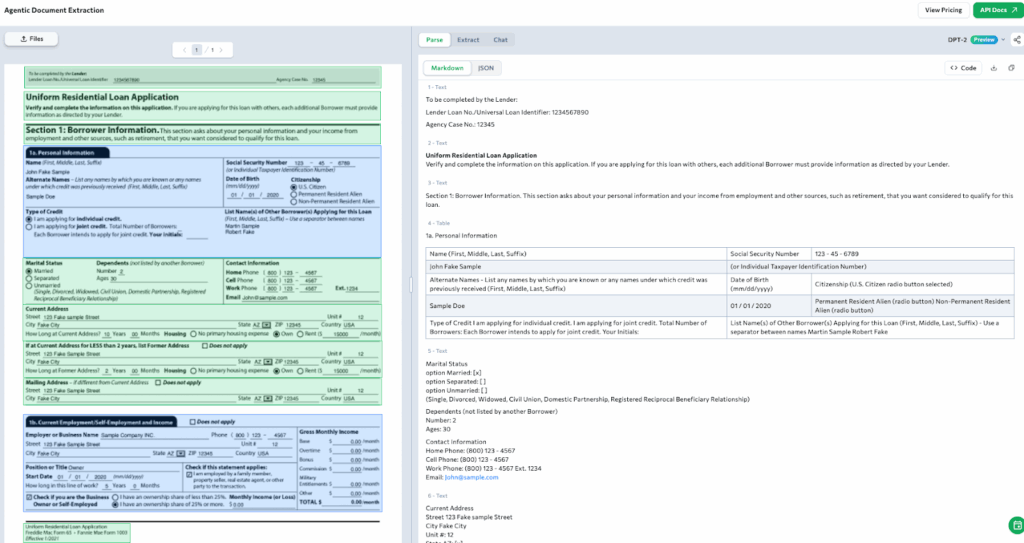
Mortgage documents are long, dense, and structured differently across lenders. A single application may include overlapping sections, repeating fields, handwritten annotations, and complex layouts that combine tables with text. One example is the Uniform Residential Loan Application, a multi-section form that gathers borrower identity, employment history, co-applicant data, and address history on a single page.
In the example below, ADE processes this form and organizes it into structured chunks. It identifies distinct sections such as borrower details, credit type, contact information, and current address. It also parses checkbox selections (such as marital status), formatted fields (such as Social Security Number), and multi-line text blocks with clarity and context.
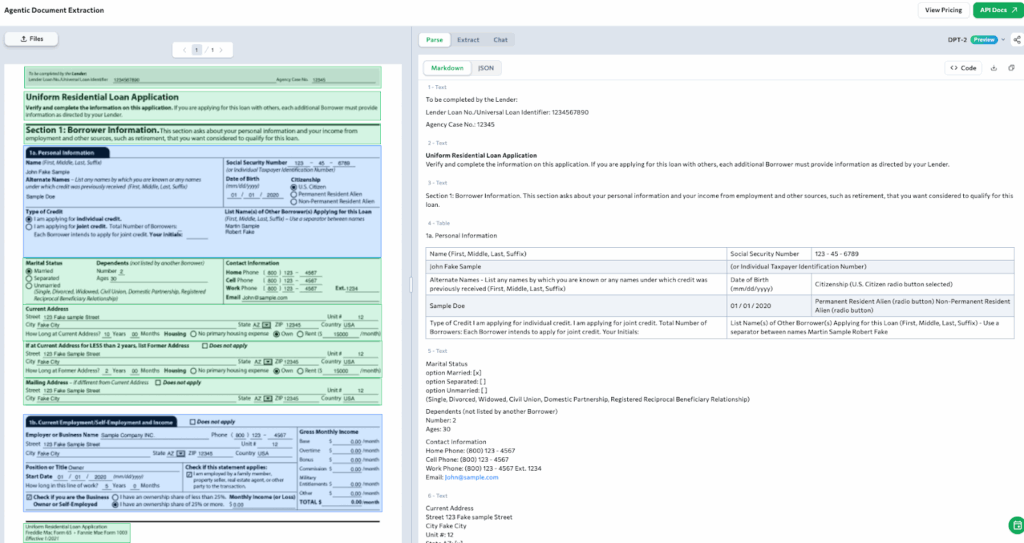
Each section is represented in a structured JSON output. Tables, typed responses, and radio-button selections are grounded spatially and grouped by semantic meaning, preserving the layout while returning clean, readable structure.
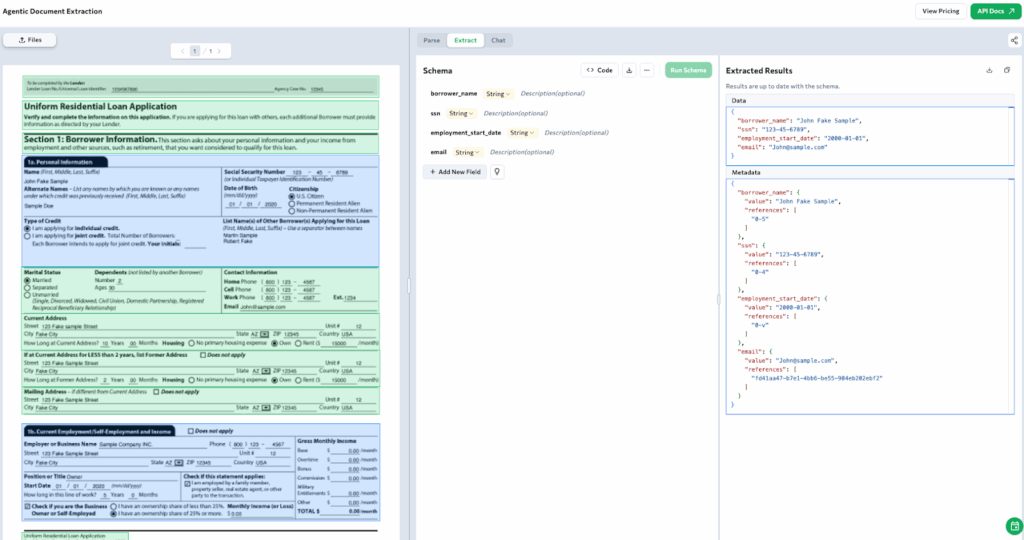
Beyond parsing, ADE also enables schema-based field extraction. In this case, a predefined schema targets specific fields such as borrower_name, ssn, employment_start_date, and email. ADE maps these fields to their corresponding locations on the page and extracts them with precision, even when the layout is complex or spans multiple sections.
Every extracted field is layout-aware, traceable, and audit-ready.
Credit Card Application and Verification
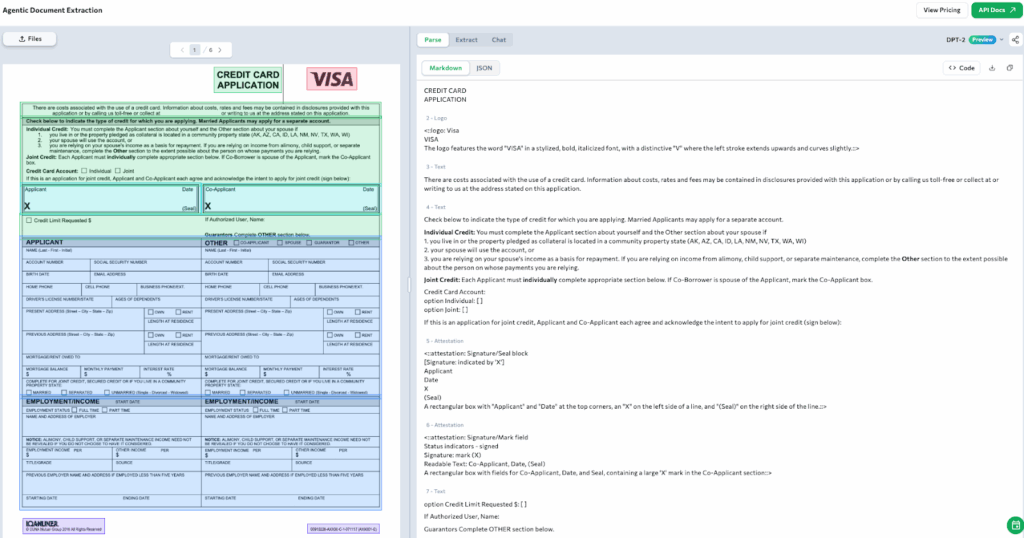
Credit card applications often combine dense tables, overlapping sections, attestation blocks, and long marginal disclaimers into a single form. These documents collect a wide range of information: applicant identity, income details, credit type, employment history, and co-applicant data. Traditional OCR pipelines struggle to extract this content accurately, especially when fields are tightly packed or formatted inconsistently.
In the example below, ADE parses a six-page credit card application and structures it into clean, readable output. It detects logos like the VISA emblem, marks each table region with semantic meaning, and accurately extracts sections like Applicant and Guarantor information. ADE also captures marginal notes, checkbox selections, and attestation blocks with spatial awareness, preserving their placement and relationship to the surrounding content.
Customer Onboarding and KYC Compliance
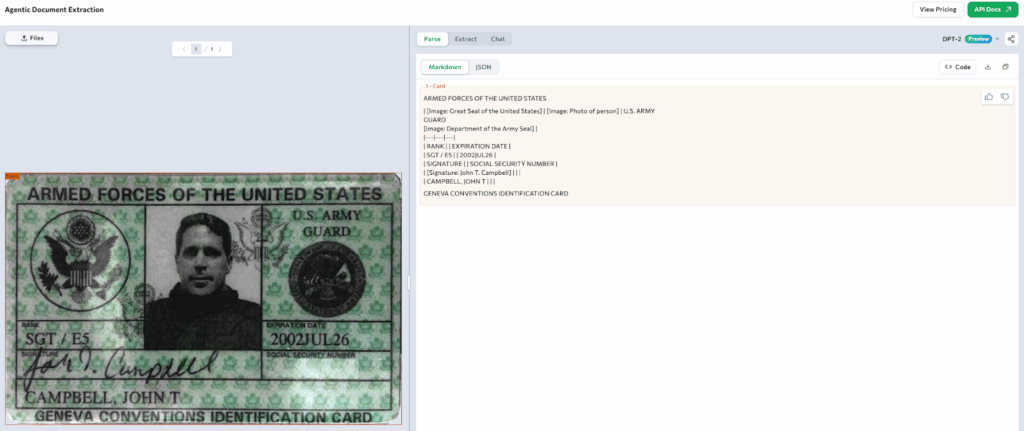
Customer onboarding in retail banking starts with identity verification. Banks typically require a government-issued ID such as a driver’s license, passport, or military identification card to confirm name, date of birth, and social security number. These documents are visually dense and vary significantly in format. They often include photos, seals, barcodes, signatures, and stamped text, all compacted into a single layout.
In the example below, ADE processes a military ID and automatically classifies it as a distinct card chunk type. This chunk type is purpose-built for identity documents and allows ADE to treat the entire card as a unified visual object. It accurately detects and structures key fields such as name, rank, expiration date, signature, and ID number, while preserving layout and spatial relationships on the card.
KYC verification doesn’t end with identity. Banks often request a recent utility bill or bank statement to validate a customer’s address. These documents introduce their own structural complexity, including transaction tables and billing summaries.
Transaction Dispute and Payment Operations
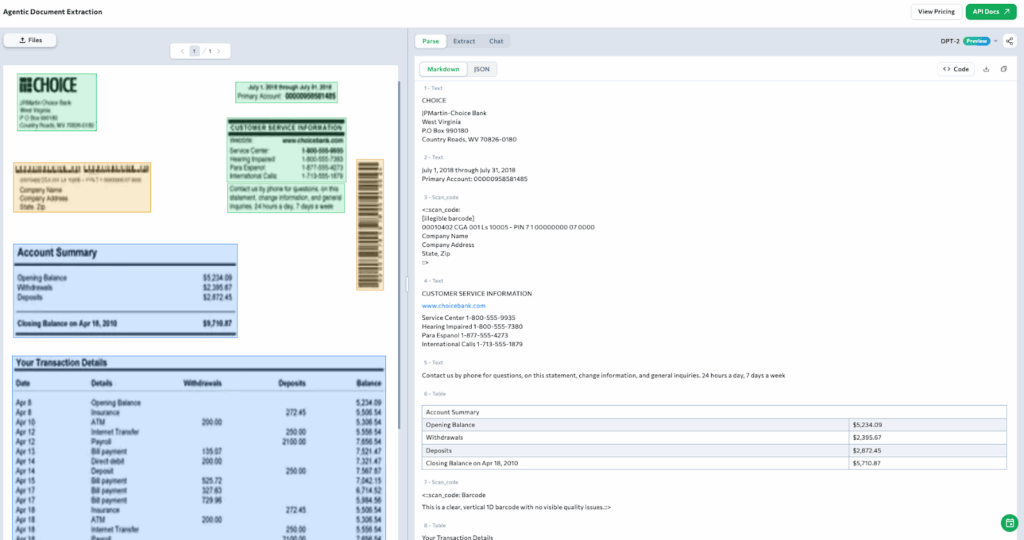
Resolving a transaction dispute often starts with reviewing a bank statement. Operations teams need to verify amounts, match dates, confirm vendor details, and locate any irregularities across pages of transactions. When scanned copies are low-quality or visually cluttered, traditional OCR tools tend to skip over fields or extract data inconsistently.
In the example below, ADE processes a scanned bank statement that includes marginal blur and slight compression artifacts. Despite the quality issues, ADE successfully identifies key sections such as the account summary, contact blocks, barcode, and full transaction history. It extracts labeled values like opening and closing balances, as well as line-by-line details of withdrawals and deposits.
Tables are recognized and structured with clear headers and row groupings, making downstream comparison with dispute forms faster and more reliable. Even visually offset sections like barcodes, contact info, or disclaimers are preserved and correctly categorized.
Regulatory and Compliance Reporting
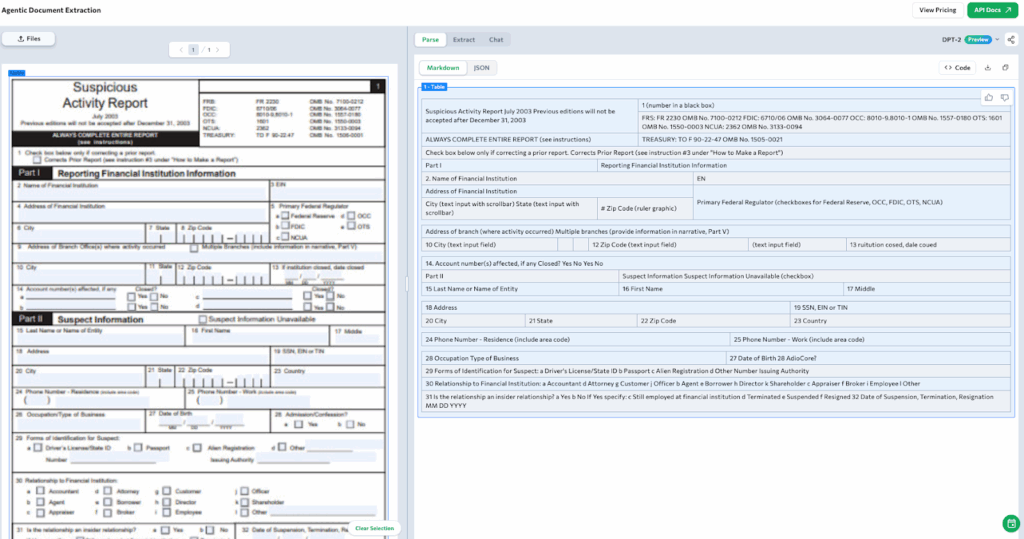
In retail banking, compliance reporting is a constant obligation. Whether triggered by suspicious transactions, audit trails, or regulatory investigations, banks are required to produce detailed reports that consolidate data from multiple sources. Forms like the Suspicious Activity Report (SAR) are especially common in anti-money laundering (AML) workflows and are submitted routinely to regulators based on specific risk triggers or thresholds.
These reports are often long and structurally dense. They combine freeform text, tightly packed tables, and dozens of small input fields that must be extracted with precision. Accuracy is essential, but layout variation and document complexity make automation difficult.
In the example below, ADE processes a SAR form and extracts the entire document as a single structured table. It identifies each section such as institution details, suspect identity, identification types, relationship disclosures, and account numbers, and organizes them in a way that preserves field boundaries and label relationships.
Despite the visual density of the form, ADE cleanly maps each input to its context. Even complex groupings like checkbox arrays and multi-column structures are parsed without manual configuration.
**Access ADE via API **
You can also integrate ADE into your own applications using the Python SDK or API. With just a few lines of code, you can parse documents and get structured outputs.
Here’s a quick example using the ade-python library:
# pip install landingai-ade
import os
from pathlib import Path
from landingai_ade import LandingAIADE
client = LandingAIADE(
apikey=os.environ.get("VISION_AGENT_API_KEY"),
)
parse_response = client.parse(
document=Path("YOUR_PATH/TO/YOUR_PDF.pdf"),
model="dpt-2",
)
print(parse_response)Conclusion
From mortgage documents and credit card applications to onboarding forms and compliance reports, retail banking runs on complex, high-volume paperwork. These documents vary in format, structure, and quality, making them difficult to process accurately with traditional OCR, rule-based tools, or even LLM-based systems.
ADE changes that. It understands documents as visual and spatial layouts, not just lines of text. By preserving structure and context, ADE extracts key information with precision and clarity across even the most inconsistent documents.
The result is faster decisions, fewer manual errors, and dependable automation across retail banking processes. Whether it’s extracting data from a loan document or parsing a regulatory report, ADE adapts to the structure of each document and returns clean, structured output ready for use.
Ready to get started?
Test ADE live with your documents in the Visual Playground.