In the era of large language models, a silent barrier has emerged for non-English speakers. Despite the revolutionary capabilities of modern AI, there’s an uncomfortable truth: most mainstream models are trained predominantly on English corpora, creating an implicit performance gap that affects text parsing, information extraction, and document processing across languages.
For organizations processing Chinese documents—from medical records to financial certificates—this “English-first” paradigm presents a frustrating dilemma: either accept information loss through translation pipelines, or force teams to work in a non-native language, compromising both efficiency and accuracy.
LandingAI Agentic Document Extraction (ADE) breaks this constraint entirely.
The Translation Tax: Why Cross-Language Processing Fails
Traditional document extraction tools impose what we call a “translation tax”—the hidden cost of converting between languages. Consider a typical workflow:
Chinese text must be translated to English for processing
Extraction rules must be written in English
Results must be translated back to Chinese
At each step, information degrades. A Chinese medical term like “肝内胆管结石” (intrahepatic bile duct stones) might be vaguely translated, leading to misclassification as “intrahepatic calcification” upon reverse parsing. In healthcare, finance, or legal contexts, such errors aren’t merely inconvenient—they’re potentially catastrophic.
Beyond accuracy, there’s an efficiency barrier. HR teams and administrative staff shouldn’t need English proficiency to extract structured data from Chinese documents. Yet traditional tools demand exactly that, forcing non-technical users to navigate unfamiliar syntax and foreign-language rule systems.
LandingAI ADE’s Solution: Native-Language Processing Without Compromise
ADE implements a fundamentally different approach: complete native-language processing from input to output, with no translation layer. Notice these three capabilities:
1. Direct Chinese Text Processing
ADE’s multilingual training enables semantic understanding of Chinese text at parity with English. Whether processing standard PDFs or scanned documents with handwritten notes and official seals, the system directly parses Chinese content without intermediate translation.
2. Chinese Schema Definition
The breakthrough lies in schema design. Instead of forcing users to write extraction rules in English, ADE accepts natural Chinese descriptions:
Extract the following fields:*
– “裸眼视力(左眼)”: Naked eye vision value for left eye**
– “耳鼻喉检查结论**“: ENT examination conclusion**
– “听力测试结果“: Hearing test result clearly stating “normal” or “mild decline”*
No technical syntax. No English requirement. Just plain business language describing what needs to be extracted.
3. Structured Chinese Output
Results output directly as structured Chinese data in JSON or Markdown format, ready for integration with enterprise systems or manual review—no post-processing required.
Real-World Applications: Where Native Processing Matters
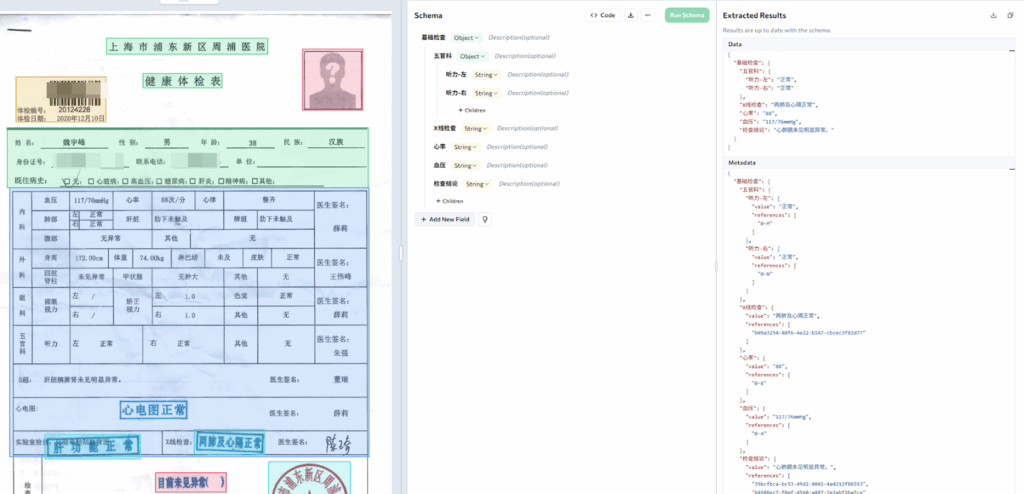
Employee Health Screening for Specialized Positions
Companies with specialized roles—drivers, precision operators, high-altitude workers—must screen employee health records for specific criteria. A traditional workflow involves HR staff manually reviewing dozens of pages per report, searching for scattered vision, ENT, and hearing indicators across varying hospital formats.
With ADE, organizations define extraction schemas in Chinese targeting only relevant fields:

Processing time drops from 10-15 minutes per report to under 30 seconds—while eliminating transcription errors entirely.
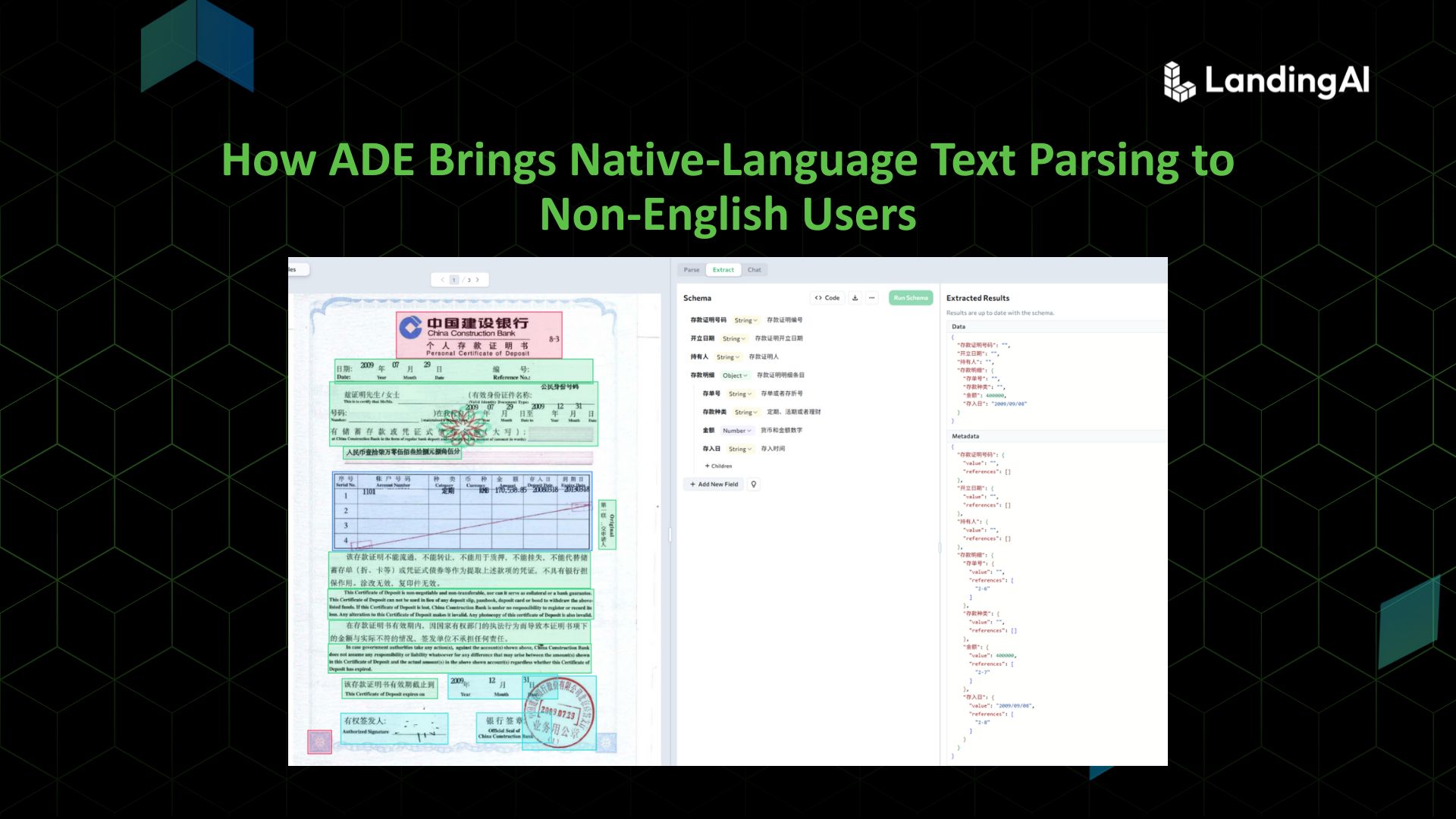
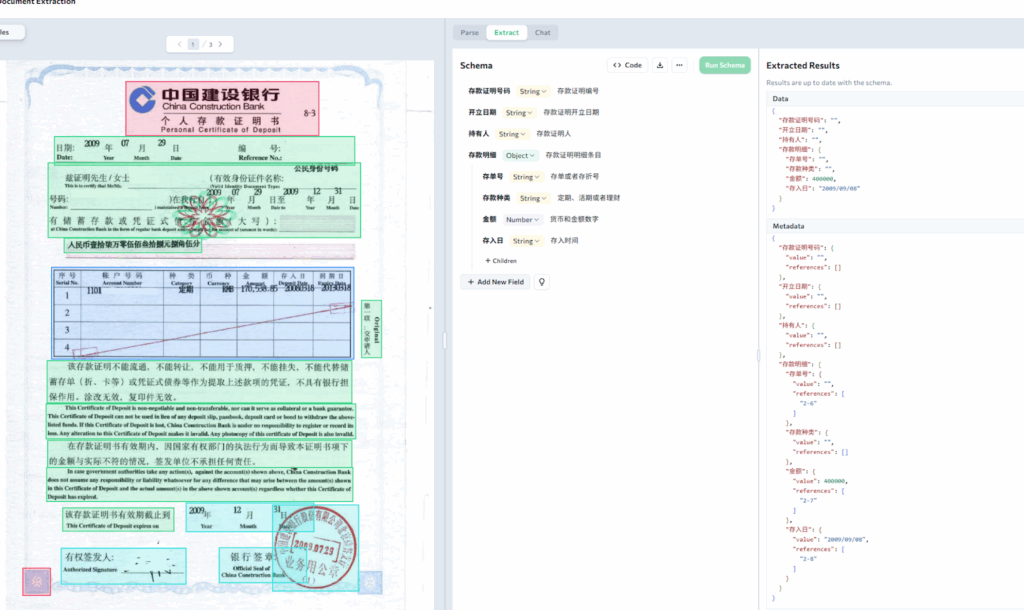
Financial Document Verification
Organizations processing deposit certificates from multiple banks face format variability and multilingual content. ADE extracts verification-critical fields directly from Chinese documents:
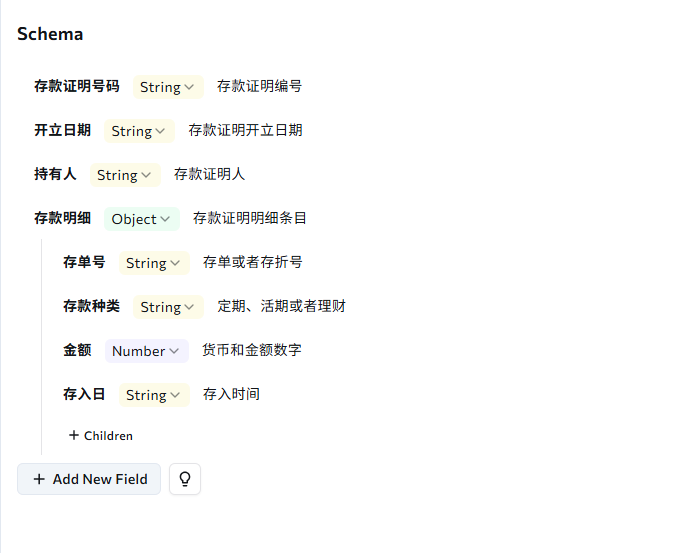
The scheme in this screenshot contains the following fields:
Account holder name (for applicant verification)
Deposit amount and currency
Issuing bank and validity period
Certificate number and official seal information
The system handles both standard bank PDFs and scanned copies with handwritten annotations, automatically filtering irrelevant content to output only verification-essential data.
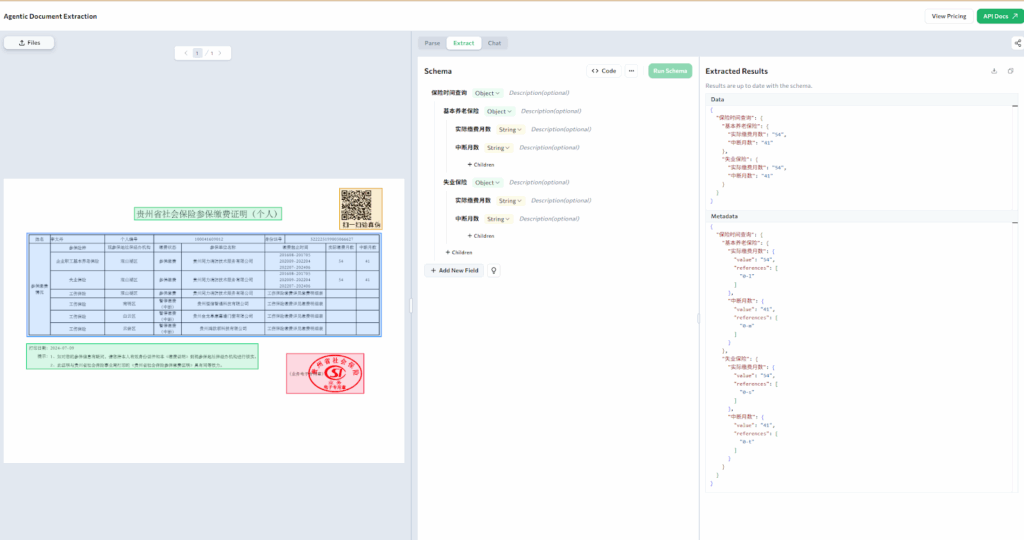
Social Insurance Continuity Auditing
When onboarding employees, HR must verify continuous social insurance payment history. ADE extracts:
Payment start and end dates
Actual payment months (excluding gaps)
Insurance types (pension, medical, unemployment)
Interruption details (if any)
Average monthly contribution amounts

This structured output enables immediate assessment of coverage continuity and seamless integration with payroll systems—all processed in native Chinese without translation overhead.
Technical Advantages: Beyond Simple Translation Avoidance
ADE’s native processing delivers benefits that extend beyond eliminating translation:
Semantic Precision
Chinese medical terminology, legal phrases, and administrative language carry nuances that resist translation. By processing natively, ADE maintains semantic fidelity—distinguishing between “轻度脂肪肝” and “脂肪肝(轻度)” or recognizing synonymous expressions like “社保缴费中断” and “社保断缴” as equivalent.
Format Agnostic Processing
Whether documents are:
Standard PDFs with tables and structured layouts
Scanned copies with handwritten annotations
Documents with official seals partially obscuring text
Mixed-language reports (Chinese with English terminology)
ADE applies the same Chinese schema consistently, using semantic understanding to navigate format variations that confound traditional OCR tools.
Zero Learning Curve
Business teams define schemas in the same language they use for daily operations. No training on English syntax, no translation of business requirements, no specialized technical knowledge required.
The Broader Implication: AI That Adapts to Users
ADE represents a shift in AI tool design philosophy. Rather than forcing users to adapt to technology constraints, it adapts to user needs—accepting instructions in native languages and processing documents as they exist in the real world.
For non-English markets, this isn’t a convenience feature—it’s a fundamental requirement for AI adoption. Organizations shouldn’t choose between accuracy and accessibility. They shouldn’t require technical teams to bridge language gaps for basic document processing. And they shouldn’t accept degraded results because their documents aren’t in English.
Conclusion: From Translation Compromise to Native Efficiency
The “English dependency” of AI systems has been an accepted limitation—a trade-off users endured to access advanced capabilities. ADE demonstrates this compromise is unnecessary.
By enabling complete native-language workflows—from schema definition through text parsing to structured output—ADE delivers both the convenience of working in one’s native language and the accuracy of eliminating translation-induced errors.
For organizations processing Chinese documents at scale, whether in healthcare, finance, HR, or regulatory compliance, this represents more than incremental improvement. It’s a fundamental shift from adapting business processes to tools, to having tools that adapt to business needs.
The result: faster processing, higher accuracy, and AI capabilities accessible to users regardless of English proficiency. In short, document extraction as it should be—native, precise, and efficient.