



Introduction
Several papers have come out recently showing how to run large language models with much less memory so they can be and infer on smaller devices such as LLM.int8() and QLoRA. I wanted to better understand how they work and also apply them to transformer vision models. In this blog post I’ll go through the different types of quantization schemes presented in LLM.int8() along with simple numpy implementations and at the end I also show how to use int8 and 4-bit quantization on the Segment-Anything-Model (SAM) backbone to improve the memory consumption. If you haven’t already I also highly recommend checking out Tim Dettmer’s blog on 8-bit matrix multiplication and 4-bit quantization which served as the basis for writing this blog.
Quantization
Quantization in machine learning is a way to reduce latency and memory by representing numbers with fewer bits. I’m going to assume you are familiar with how floating point numbers are represented and get right into int8 quantization techniques. The main objective is to figure out how best to quantize numbers such that you loose the least amount of information. We’ll cover three ways to do this, the first being absmax quantization.
Absmax
Absmax quantization is fairly simple, you just scale the input into the range [-127, 127] by dividing by the maximum value and then multiplying by 127. Here’s a small python script to compute it:
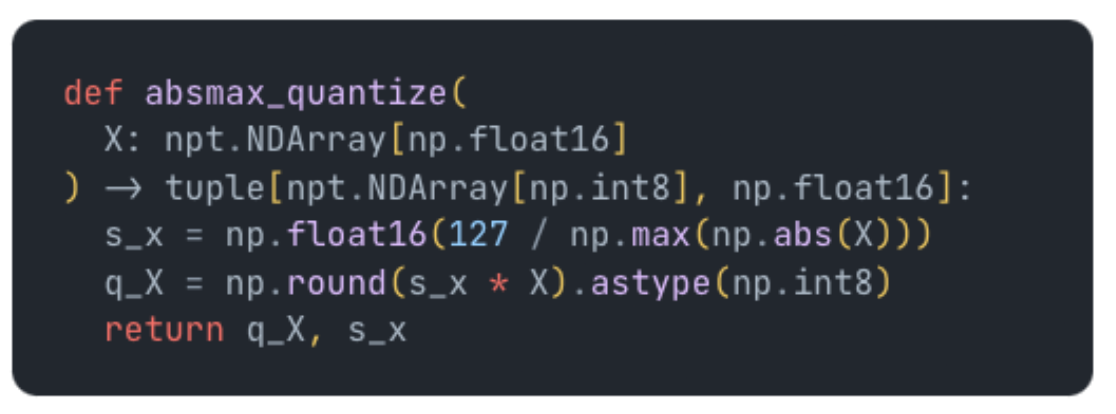
Here s_x si the scaling factor, so the 127 / max(|X|), which we multiply by X to move it to the range of -127 to 127. For example:

You can see above the largest number, 4, went to 127 and the scaling factor used was 31.75 where 4 * 31.75 = 127. You can dequantize this with the following python code:
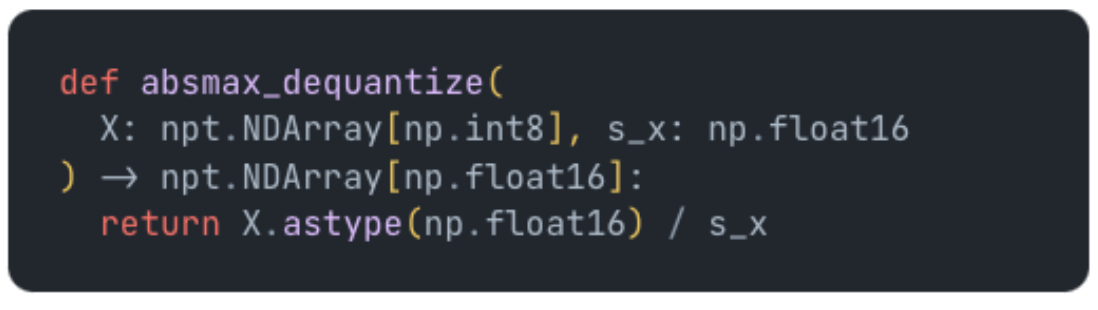
Dequantizing the above array we get:

But what happens if we only have positive values? We end up only using half of the quantization range:

This can lead to quantization errors. This leads us to zeropoint quantization.
Zeropoint Quantization
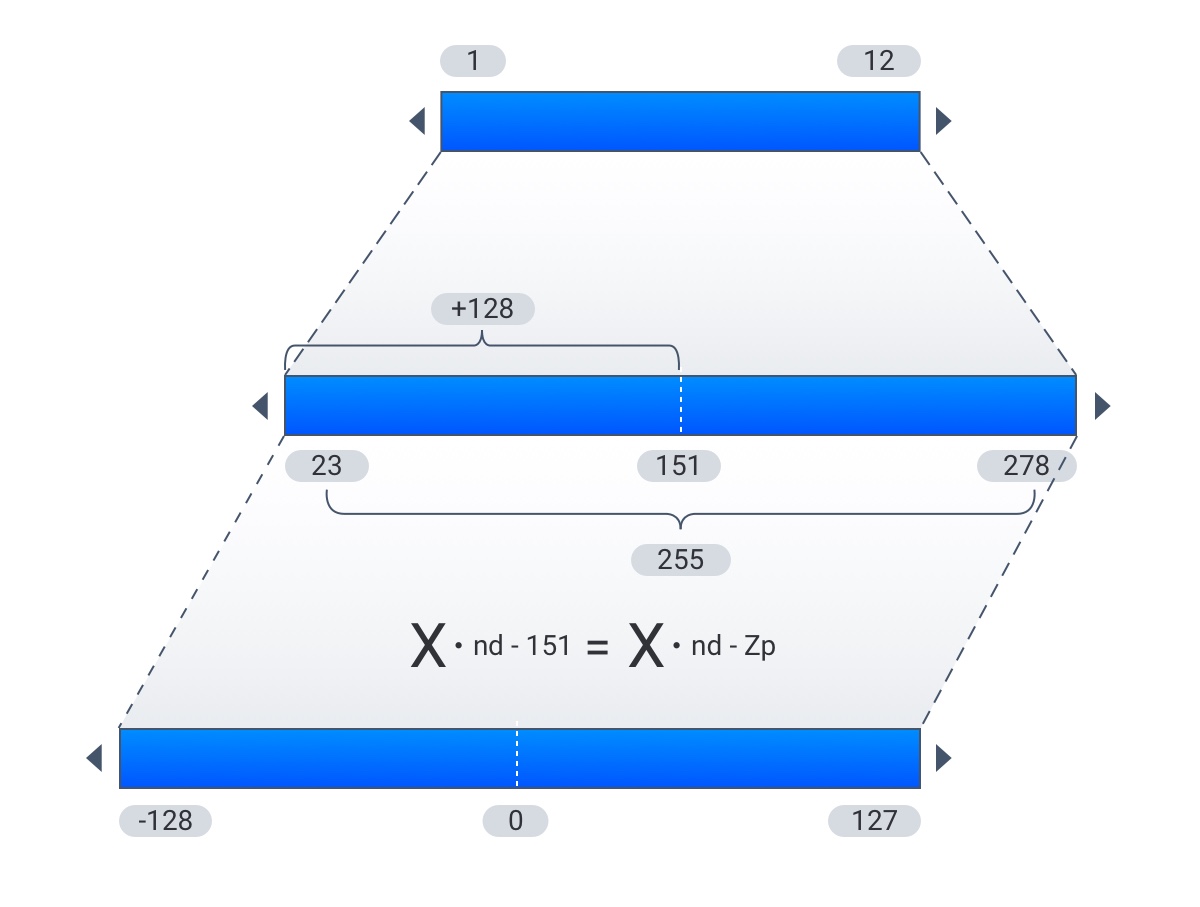
Zeropoint quantization solves this issue by scaling then shifting the numbers. First we scale the input by the normalized dynamic range nd:

Then we shift by the zeropoint zp

So we are rescaling to a new range, the size of which is 255:

And then moving the minimum value into this new range, offsetting it by 128, which is half the size of our new range, and using that to shift the range over 0:
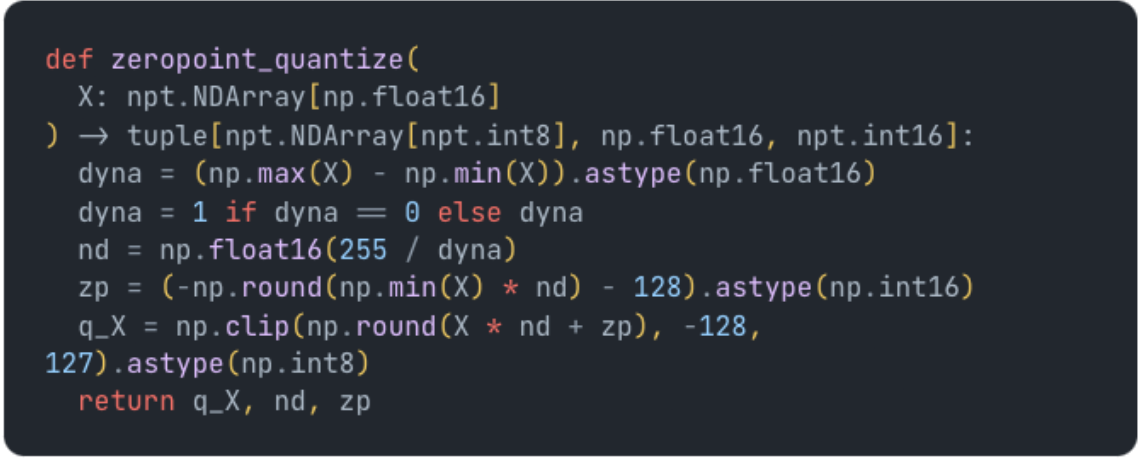
Putting it all together in python with a few other checks we have:
And to dequantize we simply subtract the zero point and divide by the scale:
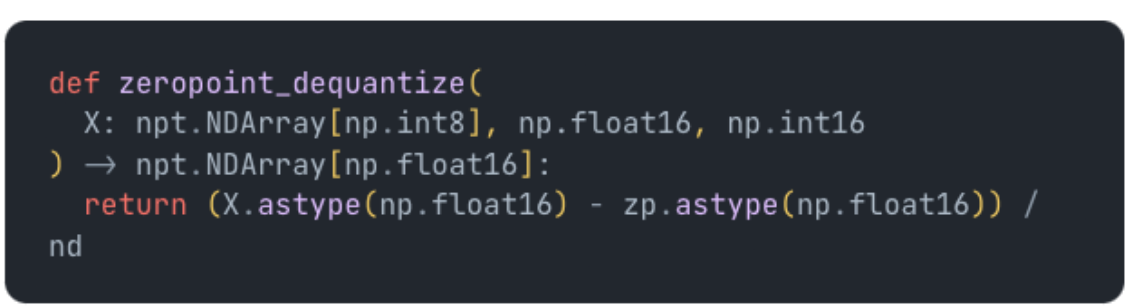
To get even better quantization results, you can also apply either absmax or zeropoint quantization per row or column of a matrix. This helps deal with more variability in the input. You can find a good overview of zeropoint quantization (also called affine quantization) here in secction 3.1.1. It turns out this still isn’t enough to get quantization to work well for larger models as important outlier features can lead to quantization errors.
LLM.int8() Quantization
Tim Dettmers was able to solve this issue in his LLM.int8() paper by introducing a hybrid approach. In the paper he notes that outlier features with large magnitudes start to emerge with larger transformers and have a strong affect on attention and prediction performance. To preserve these features we simply extract outlier features from the input X and multiply those in float16 while we quantize the rest to int8. Here we assume outlier features have magnitude 2 or more:
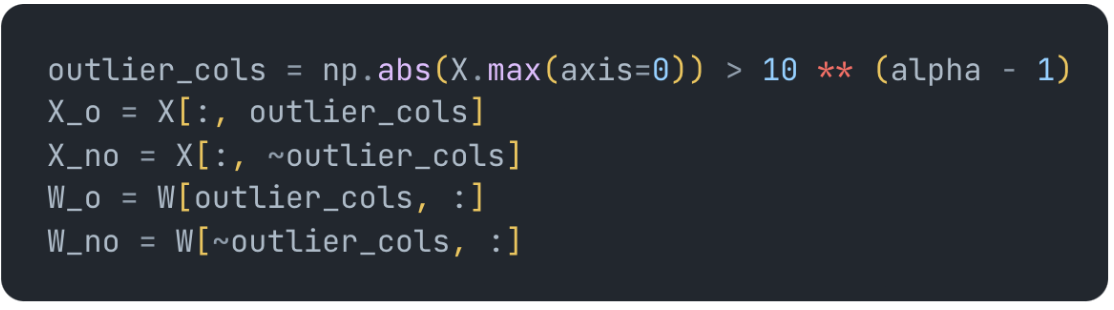
Once you have to two separate sets of matrices, you can use whatever int8 implementation you want, absmax or zeropoint, the outlier matrices will be multiplied in fp16 and both results added together:

Where row_wise and col_wise quantize functions can be either absmax or zeropoint but applied per row or per column as described above. I also recommend checking out Tim Dettmers’s blog which has a great animation of the above computation. You can find all the code for the above implementations here
Using INT8/NF4 For Vision Models
While the blog shows how easy it is to apply int8 quantization to language models from huggingface, I found it difficult to apply it to other models such as the SAM backbone. To run the following code you’ll first want to install bitsandbytes following the instructions from their github page. Then make sure you install the latest versions of these libraries from github
pip install --upgrade git+https://github.com/huggingface/transformer
pip install --upgrade git+https://github.com/huggingface/accelerate.
You’ll need to build the model in fp16 as the int8 module only works with fp16 input for now. Then call replace_with_bnb_layer which will replace all linear layers with the 8 bit linear layer (or 4 bit if you choose to use that layer). You can see before calling, we have typical Linear layers:
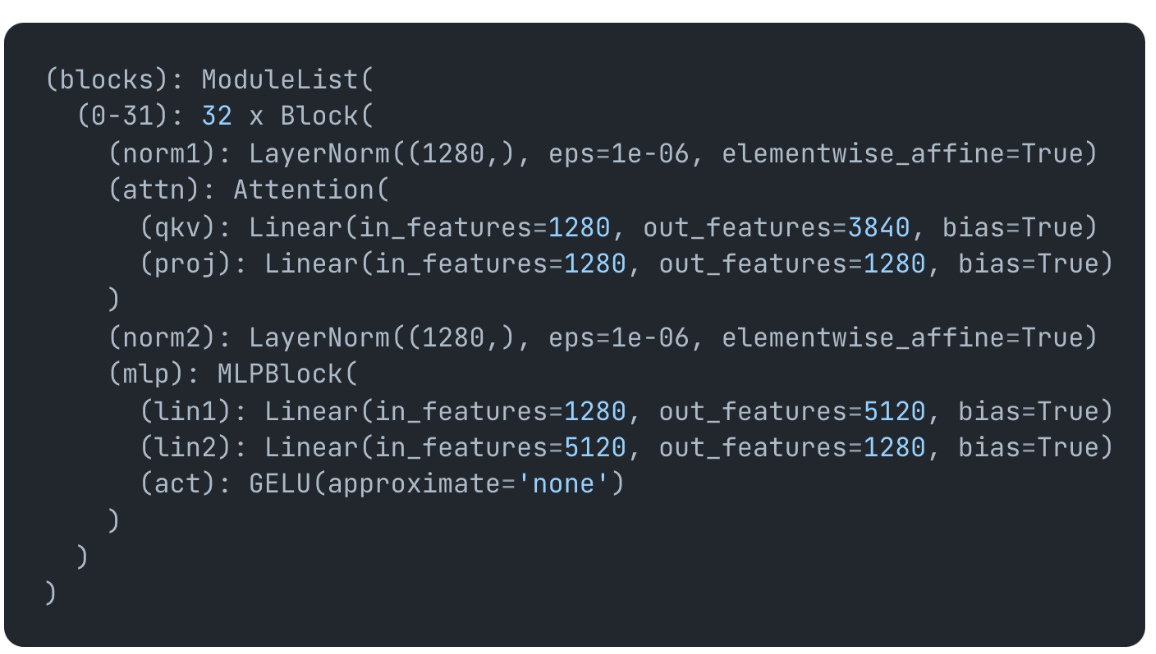
and after calling they turn into Linear8BitLt layers:
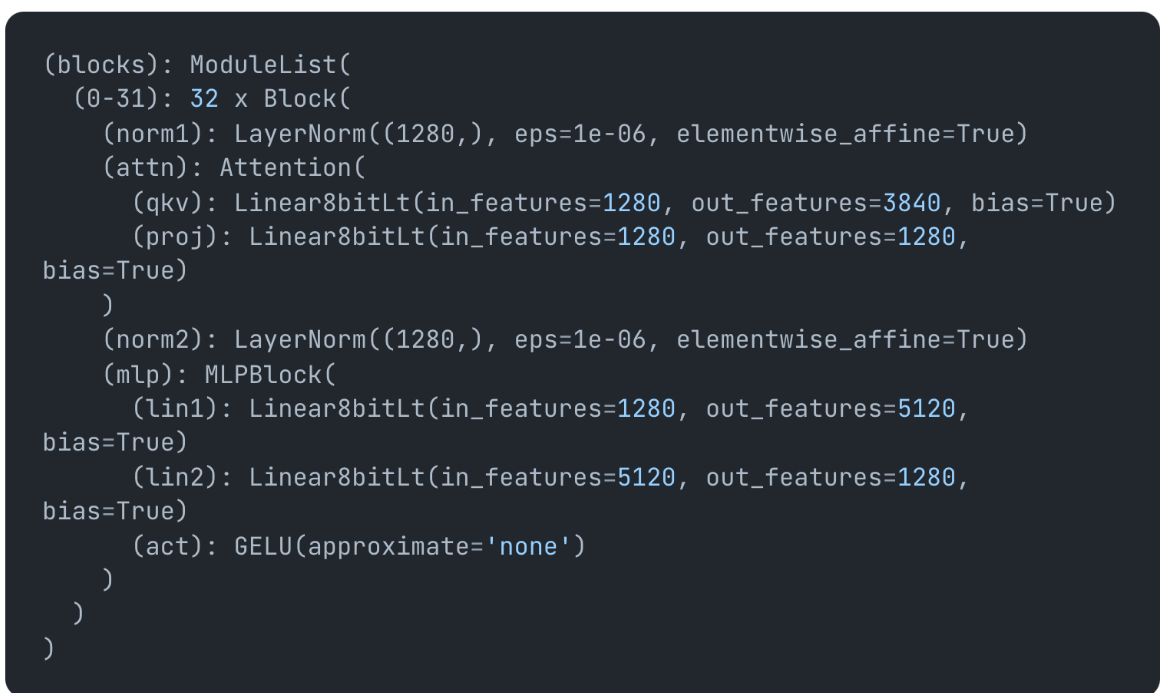
If we print out one of the layers model.blacks[0].attn.qkv it prints
Parameter (Int8Params(..., device='meta', size=(3840,1280))) which is the int8 parameters. But it’s still emtpy and set to the meta device. To fill in the weights we need to call set_module_quantized_tensor_to_device, which now allows us to see the quantized weights by printing the layer again:

Finally we can call the model by passing it a half precision input, all the steps together look like this:
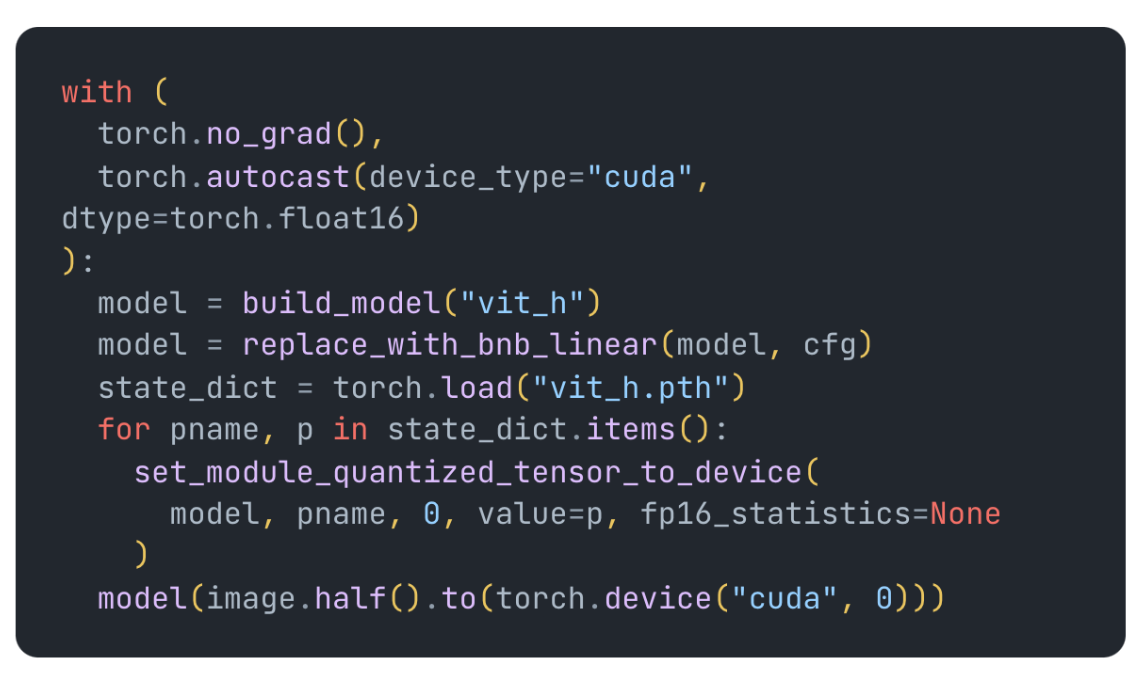
To get this working with the SAM model you must insure the Linear layers it replaces are doing matrix multiplication on 2d matrices. I’ve done this in the repository here as well as added all the quantization functions above so you can play around with it. Below are some latency and memory numbers on an RTX A5000 (you can find the 4bit conversion in the repository code):
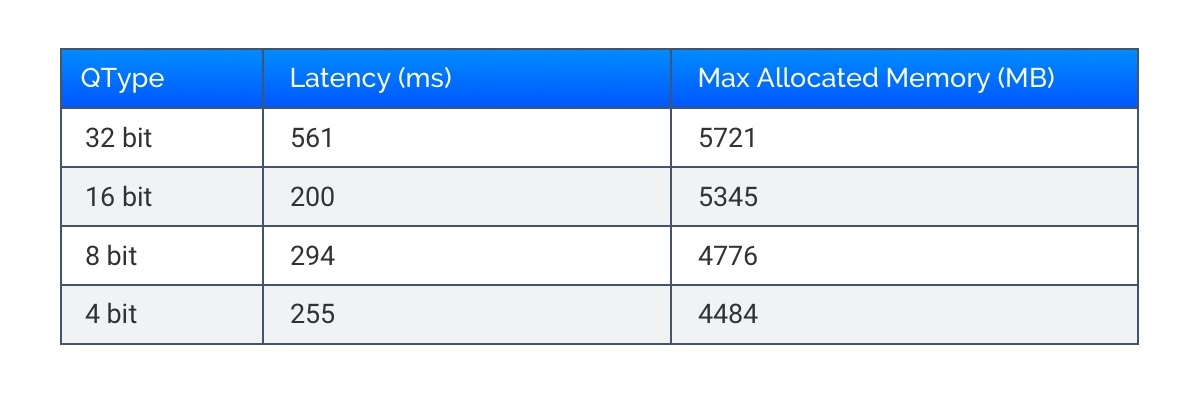
You can see the max allocated memory reduces by about ~1GB from 32bit to 8bit and you get a little half the latency. The latency times are about ~1.5x slower on 8bit than 16bit but the authors are working to decrease that time. The relative decrease in max allocated memory is not that much compared to 32 or 16 bit but if we calculate the actual model size we get a more clear picture:
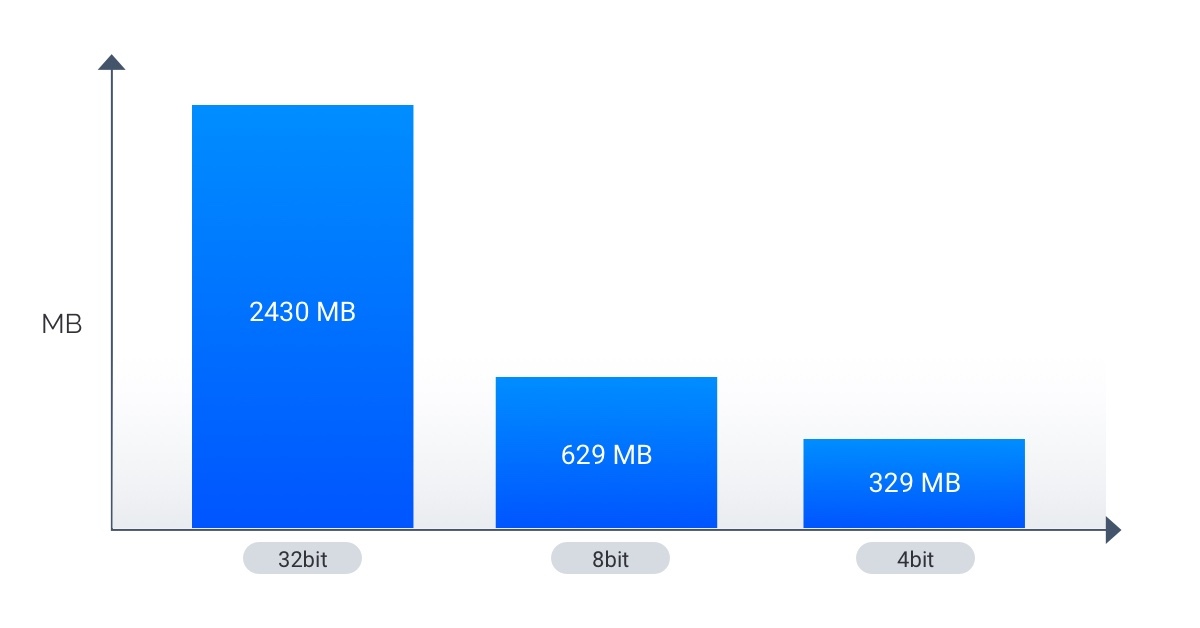
This shows about a 75% reduction from 32bit to 8bit and then halving it again when we go to 4 bit!
Conclusion
To recap we’ve covered two basic types of quantization, absmax and zeropoint quantization. We’ve also shown how to quantize a vision transformer model, SAM, using the bitsandbytes library giving us up to an 86% reduction in model size! All the quantization example code as well as code for quantizing and running the SAM backbone are available here



