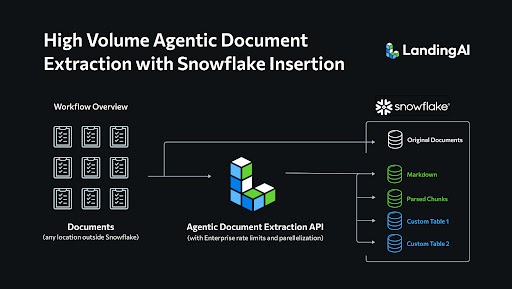
A Next Gen AI Solution powered by Agentic Document Extraction and Cortex
Nearly every enterprise runs on documents. Legal agreements, claims packets, forms, loan applications, contracts, just to name a few. These documents can be long, messy, complex, and multimodal including scanned forms, nested tables, charts, images, signatures, and footnotes. Often business users spend hours re-keying or chasing down details embedded in these documents. Even when AI tools are involved, the quality may suffer without a solution that captures the original structure and context.
These complexities create a hidden tax on decision-making, customer experience, and compliance. But what if PDFs acted like both tables and searchable knowledge all inside Snowflake?
With LandingAI’s Agentic Document Extraction (ADE) Native App for Snowflake, you can transform documents into governed, AI-ready data, complete with visual grounding that links answers back to the source.
TL;DR
In this post, we’ll walk through an end-to-end example of transforming messy documents into AI-ready data for analytics and intelligent applications using LandingAI’s Agentic Document Extraction (ADE) and Snowflake.
You’ll see how to:
- Parse and extract multimodal documents with ADE to capture the full context—text, figures, and tables—while grounding every element back to its source
- Store and govern documents and their processed outputs directly in Snowflake for security and compliance
- Power text-to-SQL queries on structured fields with Cortex Analyst
- Enable RAG applications by retrieving parsed document chunks with Cortex Search
- Enrich insights with third-party data through Cortex Knowledge Extensions
- Build an intelligent agent that orchestrates across these tools with Cortex Agents
- Give business users direct access via Snowflake Intelligence
Here’s what the full solution looks like:
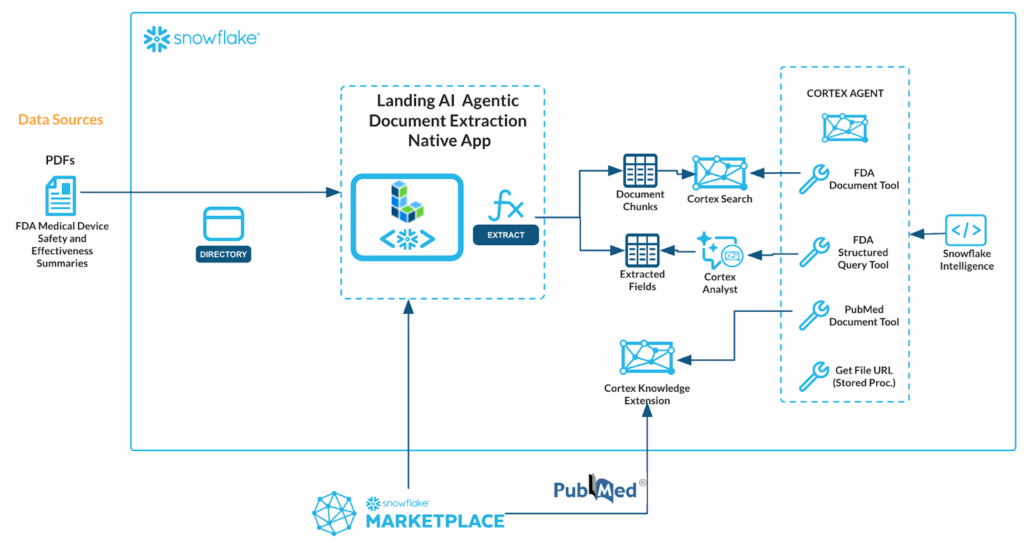
We’ll illustrate this using FDA Safety and Effectiveness documents, but the pattern generalizes across industries.
Why This Matters
Most AI document tools run outside the data platform. That creates copies, shadow pipelines, and a second security perimeter. However, with Agentic Document Extraction in Snowflake, businesses benefit from:
- Intelligent document understanding in Snowflake – LandingAI captures complex document details with zero-shot parsing, preparing your data for downstream analysis and AI applications.
- Unified governance – Security and compliance stay intact, including role-based access control, masking, and lineage.
- Analytics + AI together – Structured fields join seamlessly with enterprise data, while layout-aware chunks power retrieval and agent workflows.
- Workload automation – Parsed content drives end-to-end process automation across business functions.
- Faster iteration – No context-switching, no copies, no loss of trust.
Walkthrough: Medical Device Research Agent in Healthcare & Life Sciences
Let’s look at a real-world use case in the Life Sciences domain: parsing and extracting Food & Drug Administration (FDA) medical device safety and effectiveness summaries. These documents are an excellent stress test—packed with dense sections, complex tables, footnotes, and figures. They also include valuable content that companies may want to transform into structured fields while simultaneously making it accessible for business users and agentic workflows. In this walkthrough, we’ll demonstrate how to extract and parse these documents, and then quickly build a sophisticated agent to interact with them.
Here’s the workflow, with everything happening inside Snowflake.
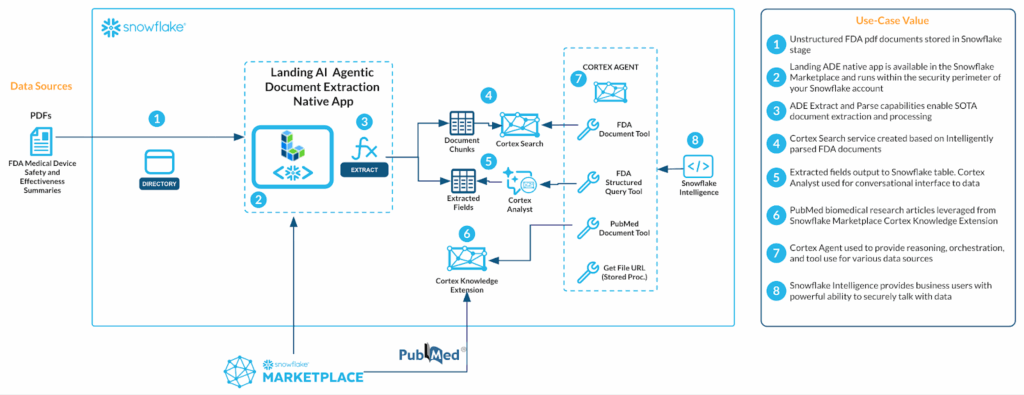
The following 8 processes are described in greater detail below. The full source code is available in this GitHub repository. This workflow supports a wide range of scenarios, including Retrieval-Augmented Generation (RAG), downstream business analytics, and text-to-SQL use cases.
1. Load Documents: Unstructured FDA pdf documents stored in Snowflake stage.
2. Install the LandingAI ADE Native Application: ADE vertex app is available in the Snowflake Marketplace and re-enables the security perimeter of your Snowflake account.
3. Parse and extract documents using ADE: ADE Extract and Parse capabilities enable SOPs, document extraction and processing.
4. Build a Cortex Search service: Cortex Search service created based on intelligently parsed FDA documents.
5. Convert extracted content for analytics / Cortex Analyst: Extracted fields output to Snowflake table. Cortex Analytic used for conversational interface to data.
6. Enrich with Cortex Knowledge Extension: PubMed biomedical research articles ingested from Snowflake Marketplace.
7. Create a Cortex Agent: Cortex Agent used to provide reasoning, orchestration, and tool use for various data sources.
8. Enable user interaction via Snowflake Intelligence: Snowflake Intelligence provides business users with powerful ability to securely talk with data.
Prerequisites
You’ll need a Snowflake account with administrative privileges (or appropriate roles) to use the LandingAI Agentic Document Extraction (ADE) Native App and the required Snowflake Cortex features.
Users will need a Snowflake account with administrative privileges or appropriate roles granted to use the LandingAI Agentic Document Extraction and necessary Snowflake Cortex features.
1. Load Documents
Upload unstructured FDA documents into a Snowflake stage. For this demo, sample files are provided in the /docs folder of the GitHub repository. You can load them with PUT commands or directly through the Snowflake UI.
2. Install the LandingAI ADE Native Application
Install the app directly from the listing page on the Snowflake Marketplace. All processing takes place inside your Snowflake account, ensuring security and governance. You may have to request the Application first and wait for the LandingAI team to approve your request.
3. Parse and extract documents using ADE
For this demo, we’ll use LandingAI’s ability to perform document parsing and extraction all within a single call. The function below processes all files in the stage in a batch.
We pass in a structured output schema to doc_extraction.snowflake_extract_doc_structure, which defines the properties we want to extract—such as device generic name, trade name, applicant details, approval dates, and key summaries.
-- Batch process from directory table to perform parsing + extraction
insert into landingai_apps_db.fda.medical_device_docs (relative_path, file_contents, stage_name, last_modified)
with stage_files as (
select *
from directory('@landingai_apps_db.fda.docs')
)
select
f.relative_path,
doc_extraction.snowflake_extract_doc_structure(
'@landingai_apps_db.fda.docs/' || f.relative_path,
'<YOUR CUSTOM JSON SCHEMA HERE>'
) as file_contents,
'landingai_apps_db.fda.docs' as stage_name,
last_modified
from stage_files f;Here is the specific custom JSON schema used. Notice that the description field provides a lot of subject matter expertise which helps the agentic system identify the correct details and return them in your desired format.
{
"title": "FDA Medical Device Stats",
"type": "object",
"properties": {
"device_generic_name": {
"type": "string",
"description": "Generic device name from the SSED/labeling"
},
"device_trade_name": {
"type": "string",
"description": "Marketed trade/brand name"
},
"applicant_name": {
"type": "string",
"description": "Manufacturer/Sponsor/Applicant"
},
"applicant_address": {
"type": "string",
"description": "Applicant mailing address as listed"
},
"premarket_approval_number": {
"type": "string",
"description": "Primary PMA (or De Novo/510(k)/HDE identifier), e.g., P200022"
},
"application_type": {
"type": "string",
"enum": [
"PMA",
"PMA_SUPPLEMENT",
"DE_NOVO",
"HDE",
"510K"
],
"description": "Submission type as stated"
},
"fda_recommendation_date": {
"type": "string",
"description": "Date of FDA review team/advisory panel recommendation, if stated and translated to YYYY-MM-DD"
},
"approval_date": {
"type": "string",
"description": "FDA approval decision date and translated to YYYY-MM-DD"
},
"indications_for_use": {
"type": "string",
"description": "Concise IFU statement (one paragraph)"
},
"key_outcomes_summary": {
"type": "string",
"description": "One-paragraph summary of pivotal effectiveness and safety (e.g., endpoint result, SAE highlights)"
},
"overall_summary": {
"type": "string",
"description": "Executive summary: what the device does, who it’s for, key results, and benefit–risk conclusion"
}
},
"required": [
"device_generic_name",
"device_trade_name",
"applicant_name",
"applicant_address",
"premarket_approval_number",
"approval_date",
"overall_summary",
"application_type",
"fda_recommendation_date",
"indications_for_use",
"key_outcomes_summary"
],
"additionalProperties": false
}
This step returns more than raw text. ADE outputs text chunks that preserve document structure, structured field values aligned to your schema, and summarized figures and tables. Each field is linked back to its exact location in the source through visual grounding, with metadata and page references to ensure traceability and trust.
Here is a picture of the first chunk in the response for one document.

4. Build a Cortex Search service
Once parsed, the results can be flattened into a chunked table (see landingai_apps_db.fda.medical_device_chunks) that preserves the text segments and their metadata. Index this table in a Cortex Search service to enable fast, high-quality retrieval. With this in place, you can run Retrieval-Augmented Generation (RAG) directly in Snowflake, letting agents and business users query the FDA documents with semantic search, grounded answers, and citations back to the original text.
5. Convert extracted contents for analytics / Cortex Analyst service
Next, parse the extracted objects from Step 3 into a structured table (see landingai_apps_db.fda.medical_device_extracted). It contains the following:
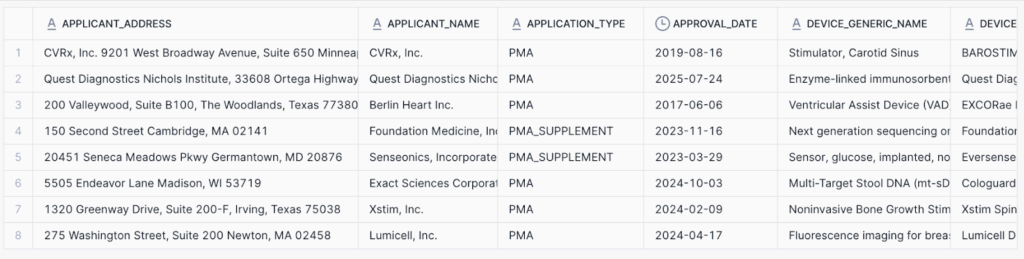
This table can be used directly for analytics or extended with a semantic model.
A semantic model defines the business meaning of your data (e.g., dimensions, measures, and relationships), while a semantic view is the Snowflake object that exposes this model so tools like Cortex Analyst can translate natural language questions into SQL queries.
For example, you can create a semantic view (LANDINGAI_APPS_DB.FDA.MEDICAL_DEVICES) on top of the extracted table. This allows users to query FDA device data with plain language through Cortex Analyst, without needing to write SQL. Semantic views can be built in the Snowflake UI. See Cortex Analyst documentation for details.
6. [Optional] Enrich with PubMed Cortex Knowledge Extension
To further enhance the solution, you can integrate Cortex Knowledge Extensions found on the Snowflake Marketplace such as the PubMed Biomedical Research Corpus. This corpus contains millions of peer-reviewed biomedical research articles, including abstracts and metadata, which can be indexed into a Cortex Search service.
By combining your FDA medical device summaries with PubMed research, the agent will be able to answer more complex questions—for example, linking device safety and effectiveness results to broader clinical findings, or citing related research studies to provide context. This enrichment step turns your FDA document workflow into a powerful biomedical knowledge environment, ready for retrieval-augmented generation (RAG) and advanced agentic applications.
7 Create a Cortex Agent
With our search and analytics services in place, the next step is to create a Cortex Agent. The agent orchestrates across multiple tools to handle complex, multi-step questions about the documents in an agentic way. This can be configured directly in the Snowflake UI or programmatically (see source code in the repository).
When defining the agent, you provide three main components:
- Instructions – High-level guidance for how the agent should respond and interact with users. For example, you may specify that answers should always include citations, or that regulatory dates must be returned in YYYY-MM-DD format.
- Tools – The agent’s capabilities, which in this case include:
- Cortex Search over FDA device documents (landingai_apps_db.fda.medical_device_chunks)
- Cortex Analyst for natural language to SQL on structured device data (landingai_apps_db.fda.medical_device_extracted)
- Cortex Search on the PubMed Biomedical Research Corpus for scientific enrichment
- A stored procedure for downloading source documents on demand
- Cortex Search over FDA device documents (landingai_apps_db.fda.medical_device_chunks)
- Orchestration – The planning logic that directs the agent to choose the right tool (or sequence of tools) for each query. For example, a user question like “Summarize safety outcomes for stent devices, and show supporting clinical studies” would require the agent to first pull structured data from the FDA summaries, then retrieve related PubMed studies for enrichment.
You can see the Instructions and the Tools in this screenshot:

8. Enable user interaction via Snowflake Intelligence
The final step is to make the agent available to business users through Snowflake Intelligence, a conversational interface built directly into Snowflake. Users can interact with the agent in a familiar chat-style experience, asking both structured (SQL-like) and unstructured (narrative) questions. Responses are enriched with citations back to the underlying FDA document chunks and, when needed, links to download the original source files.
Access and usage are governed by Snowflake’s built-in role-based access control (RBAC), ensuring that users only see the data they are authorized to view. All interactions are logged, making it easy to monitor usage and maintain auditability.
For organizations that want to extend the solution beyond Snowflake, the Cortex Agents REST API can expose the agent to other business applications, such as compliance dashboards, workflow automation tools, or internal knowledge portals.
Interacting with the Agent
Let’s walk through an example interaction to see the power of LandingAI Agentic Document Extraction combined with Snowflake Cortex.
Example 1: Asking a question which requires understanding an embedded figure for the answer
Consider a safety and effectiveness summary from PMA P160035 for the EXCOR Pediatric Ventricular Assist Device submitted by Berlin Heart Inc. In most RAG-based applications, large portions of the document—such as Figure 12 on page 38—would be ignored by downstream AI systems. Yet, these figures contain rich context that is invaluable to medical researchers.
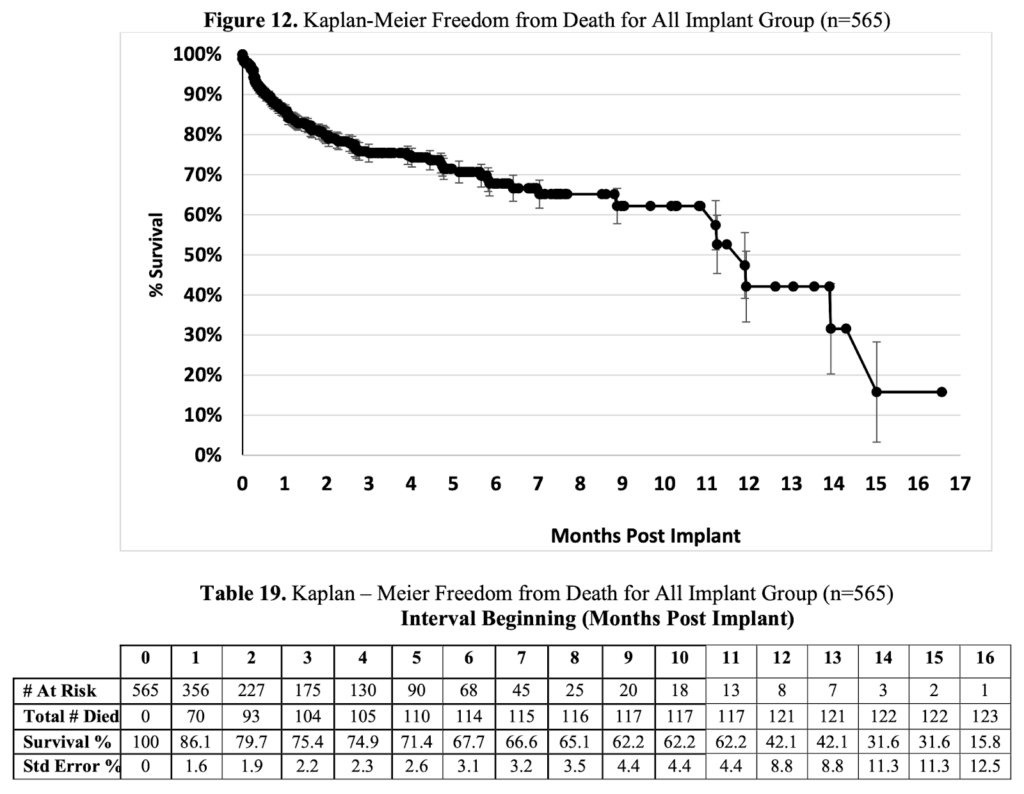
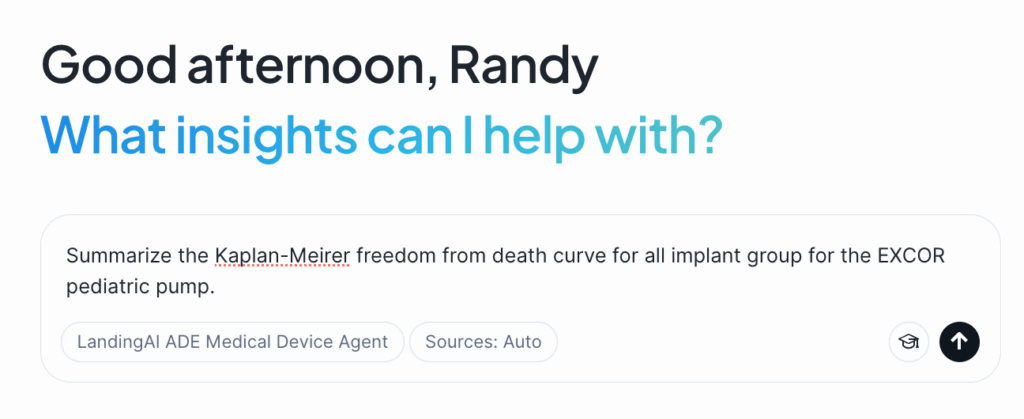
Because we used LandingAI’s Agentic Document Extraction for parsing, we can ask a question like:
“Summarize the Kaplan-Meier freedom-from-death curve for all implant groups for the EXCOR pediatric pump.”
As seen in the screenshot below, the agent can provide an accurate, grounded response by drawing from the extracted figure. It highlights insights such as where the curve flattens, the differences across implant groups, and even the statistical significance. Importantly, the solution makes it clear exactly which figure and which part of the page the answer came from—something most other approaches cannot deliver.

Example 2: Asking about the most recent document
As another example, imagine we want to know:
“What is the most recent safety and effectiveness document we have for applicants in the United States? Based on this document, provide some relevant PubMed articles.”
The agent interprets this as a two-part task:
- Use Cortex Analyst to generate SQL that queries the extracted structured fields and identifies the latest approval date.
- Once that document is found, use the PubMed Cortex Knowledge Extension to surface related biomedical studies for enrichment.
This orchestration shows how the agent can seamlessly combine structured queries, unstructured document parsing, and external research sources.
Here are screenshots of the agent planning its approach and the final output.

Wrapping It Up
Agentic Document Extraction inside Snowflake transforms unstructured, multimodal documents into governed, AI-ready assets. The result:
- Grounded answers for trust and auditability
- Structured fields for analytics and automation
- Parsed contents that power RAG and agentic solutions
- One security perimeter with unified governance
We demonstrated this with a practical example in medical sciences, but the same pattern applies across industries and business functions—from financial services to healthcare, manufacturing, and beyond.
Now it’s your turn to unlock the value of your unstructured documents. And don’t stop there: use Snowflake’s AI Observability features to measure, monitor, and prove the effectiveness of your solution.
References and Links
Agentic Document Extraction | LandingAI
Using ADE on Snowflake | LandingAI Documentation
Cortex Search | Snowflake Documentation
Cortex Analyst | Snowflake Documentation
Cortex Agents | Snowflake Documentation
Cortex Knowledge Extensions | Snowflake Documentation
Overview of Snowflake Intelligence
Sources: U.S. Food & Drug Administration (FDA) device approval packages (Summaries of Safety and Effectiveness Data). All documents are publicly available through https://www.accessdata.fda.gov/scripts/cdrh/cfdocs/cfpcd/classification.cfm
The FDA does not endorse this analysis or solution.