Today we are sharing a powerful solution for a high-volume document extraction pipeline which lands data into Snowflake. Built specifically for Snowflake Data Engineers, the GitHub repo provides an end-to-end workflow which provides performance at scale: cost‑efficient document processing in the cloud and streaming ingestion into Snowflake. This agentic document extraction workflow offers:
Layout‑aware document parsing without layout-specific training
Zero-shot, highly accurate field extraction
Validated outputs with visual grounding
Efficient loading of results into Snowflake using familiar SQL patterns
We’ll walk through the core components, highlight scalability features, and show you how to integrate the pipeline into your existing data workflows, while ensuring **security, compliance, and governance **for document extraction pipelines. If you prefer to see a demo first, check out the 3 minute accompanying YouTube video.
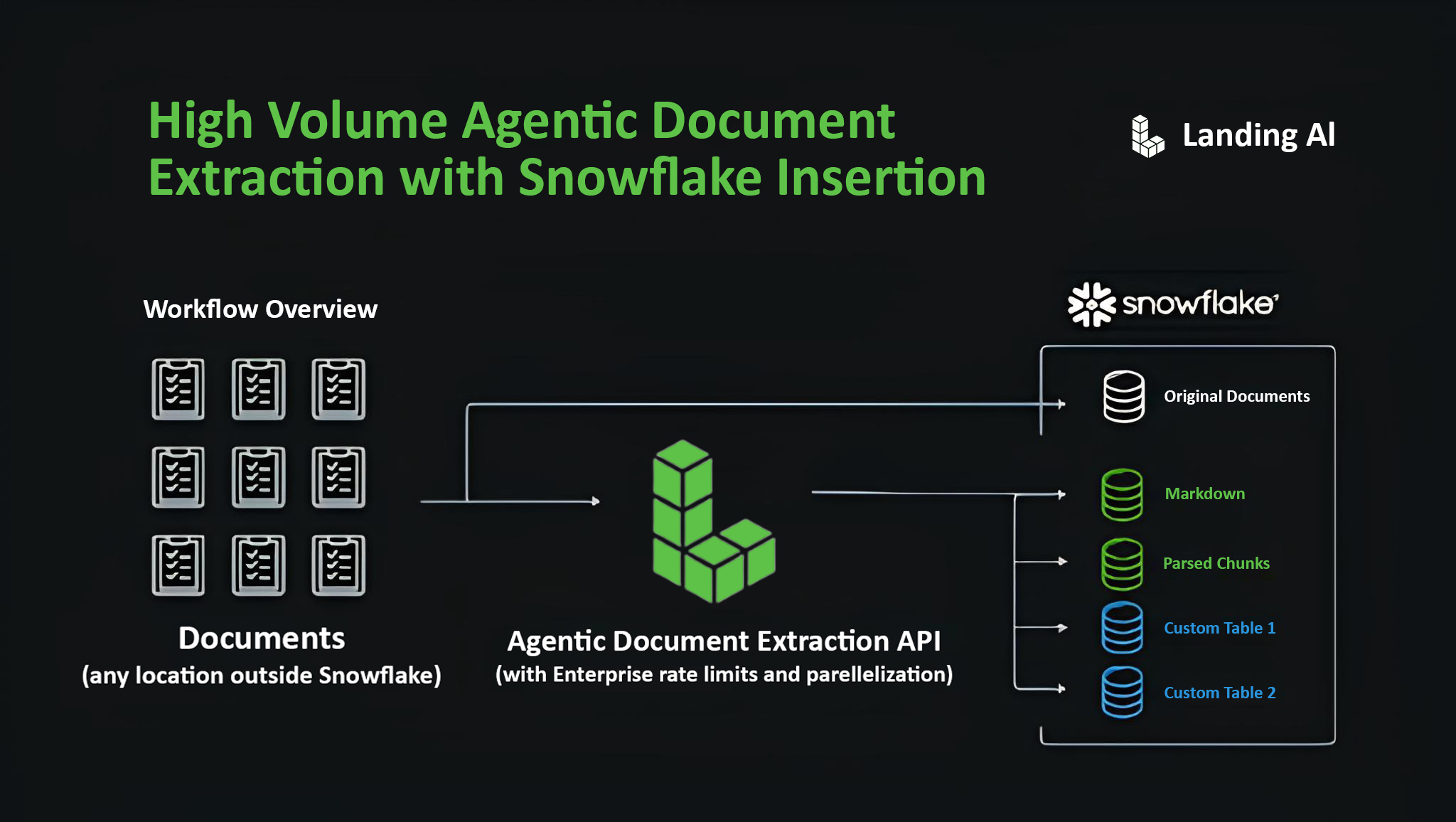
Workflow Diagram
To better understand the end-to-end flow—from document ingestion to Snowflake population—use the diagram below as a visual guide. It illustrates how documents from any location are passed through the Agentic Document Extraction API, with parallelization and enterprise-grade throughput, and result in structured tables and assets in Snowflake.
Overview Video
For a quick and clear demonstration of the full process—inputs, API calls, batch parsing, schema design, and Snowflake insertion—check out the companion video below. You’ll see how ADE’s output is visually grounded, structured, and ready for analytics within minutes.
The video is helpful for executives to understand the overall flows and for developers who are interested in using our starter code to replicate this workflow.
Starter Code
Visit the GitHub repo named High Volume ADE with Snowflake Insertion for a complete pipeline that uses LandingAI’s Agentic Document Extraction (ADE) to parse documents and insert structured data into Snowflake tables. It uses invoices as an example, but the pattern is modular and can be adapted to any document type.
Here is a preview of what you’ll find:

LandingAI provides a Visual Playground with complimentary credits for new users. Use the Visual Playground to test performance on your own documents and develop your extraction schema.
The Document Understanding Problem
In today’s enterprise environments, unstructured documents—scanned invoices, forms, certificates, and contracts—are piling up faster than teams can process them. Manually reviewing and extracting data from these files not only slows operations but also introduces human error and compliance risk. This is especially the case when extracting tables, checkboxes, and forms from PDFs. The key solution is a **hybrid of computer vision and OCR **to achieve true document understanding. Enter Agentic Document Extraction (ADE), which uses document-native vision models , and a layout-aware, visual-first approach to reading documents with precision and scale.
But extracting the data is just the first step. To unlock business value, the results must flow seamlessly into enterprise data platforms like Snowflake—where analytics, automation, and governance happen.
Here are some benefits of the joint solution:
Turnkey Pipelines for High-Volume Document Extraction in Snowflake
If your organization is wrangling thousands of documents per day—think invoices, forms, certificates, or applications—you need more than just OCR. You need a high-volume document extraction pipeline in Snowflake that’s built for performance, accuracy, and scale. This repo provides a ready-to-run workflow that connects Agentic Document Extraction (ADE) to Snowflake with minimal setup. From parallel processing to robust Snowflake insertion scripts, the repo gets you started quickly with a turnkey pipeline.
Layout-Aware Extraction with Visual Grounding for Auditability
Unlike basic OCR tools, ADE provides layout-aware document parsing that captures not just the text, but also the visual structure—tables, checkboxes, handwritten attestations, and more. Every extracted field is visually grounded with pixel coordinates and page references, enabling traceability back to the original document. This is critical for regulated industries and review workflows where auditability and traceability in document extraction isn’t optional. The provided workflow includes structured metadata handling, visual references, and bounding-box support for downstream use in Snowflake or BI dashboards.
Optimized for Scalability: Batch and Streaming at Scale
Document extraction at scale often falters when performance bottlenecks creep in. That’s why this solution is designed with streaming ingestion for high-volume document pipelines in mind. The workflow supports mini-batching, efficient file staging, and parallel Snowflake insertions to ensure that large volumes of documents don’t overwhelm your compute resources or clog your pipelines. The design assumes scale from day one, making it a strong fit for centralized document hubs, mailroom automation, or vendor invoice processing.
Built to Integrate with the Full Snowflake Ecosystem
Once ADE extracts the structured data, Snowflake becomes your playground for analytics, governance, and enrichment. This repo enables Snowflake insertion for extracted document records via well-documented SQL-compatible formats, ready for downstream joins, dashboards, and alerts. Whether you’re using Streams & Tasks, Snowpark, or native SQL, the pipeline helps you move from raw pixels to governed tables in minutes. Snowflake Data Engineers will appreciate the clean stage design, naming conventions, and schema extensibility built into the workflow. Review the implementation in the GitHub repository, and try out real-world documents in the Visual Playground.
Fully Customizable for Your Workflows
Every organization’s document workflow is different. That’s why this repo is not just a black box, but a flexible starting point for custom ADE pipelines with Snowflake integration. From schema modifications to insertion logic, retry handling to logging, you can tailor the entire flow to your document types and governance requirements. The repo follows a modular Python structure, making it easy to integrate with existing ETL frameworks or trigger via scheduled tasks. Fork it, tweak it, and run it your way.
Conclusion: From Chaos to Structure in Minutes
In a data-driven world, unstructured documents shouldn’t be a bottleneck—they should be an opportunity. With LandingAI’s Agentic Document Extraction (ADE) and the High-Volume ADE with Snowflake Insertion workflow, Snowflake Data Engineers now have a scalable, toolkit to automate document ingestion and unlock structured, queryable insights at scale.
This solution goes beyond traditional OCR. By combining layout-aware document parsing, visual grounding, and modular Snowflake insertion workflows, it enables traceable, high-fidelity extraction of data from complex documents like invoices, forms, certifications, and more. The repo is designed for scale—supporting batch or streaming ingestion—and integrates natively with the Snowflake ecosystem, allowing you to analyze and govern document data just like any other table in your warehouse.
Whether you’re dealing with thousands of incoming PDFs per day or designing pipelines for regulated environments, this workflow gives you a proven foundation to build on. It’s fully extensible, performance-conscious, and enterprise-ready—with the option to plug in validation, human-in-the-loop review, and advanced field mappings.
Ready to get started?
Explore the GitHub repo
Test ADE live in the Visual Playground
Contact Enterprise Sales to discuss deployment and pricing for large workloads