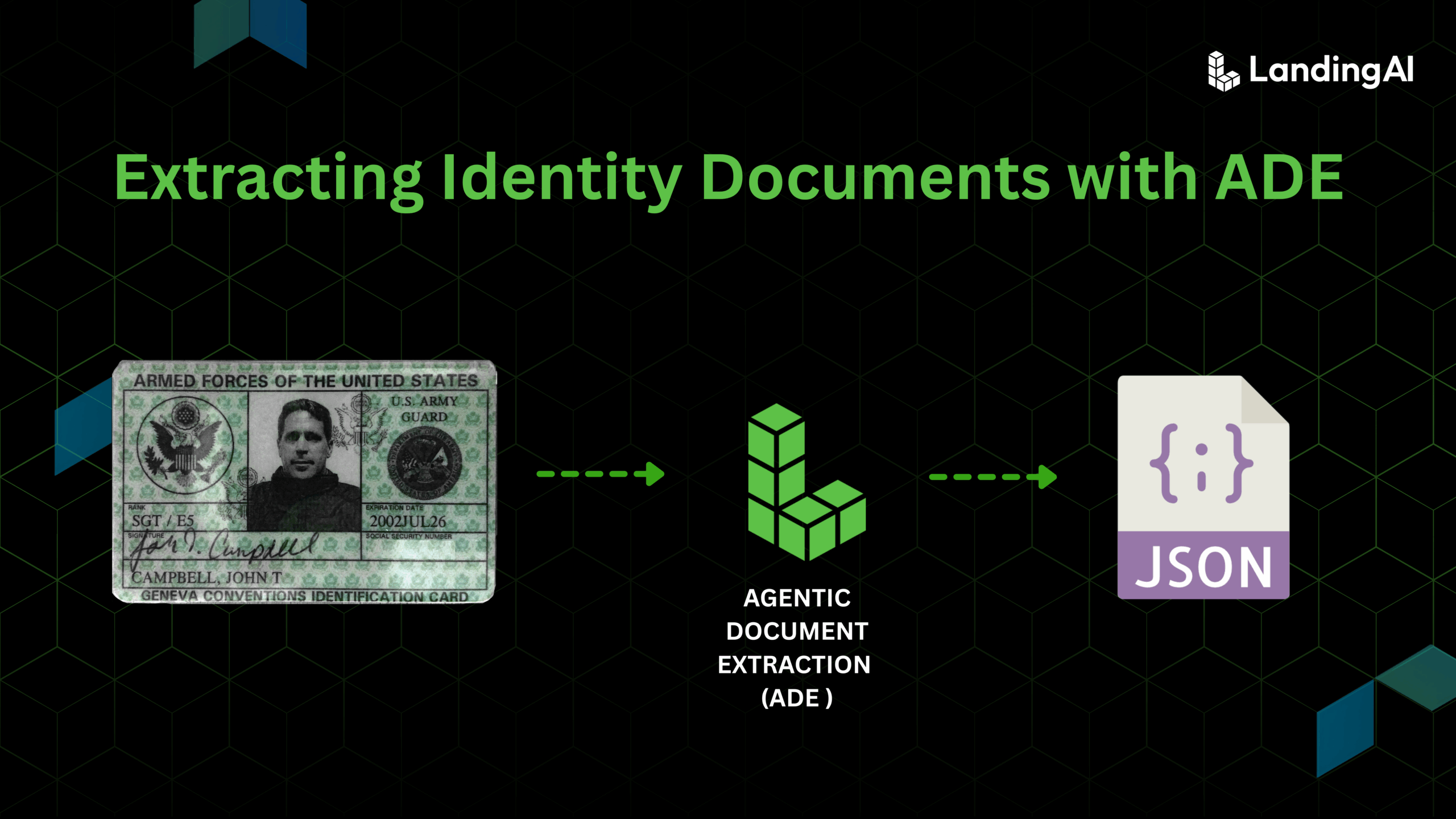
TL;DR
Parsing identity documents such as passports and driver’s licenses is notoriously difficult because of differing layouts, layered security features, and the high compliance risk of errors. Traditional OCR, templates, and even LLM-based systems fail to handle these complexities reliably. Agentic Document Extraction (ADE) solves this by treating the entire card as a single structured object and by preserving layout and spatial context in its structured JSON output. Powered by the DPT (Document Pre-Trained Transformer) model family, ADE offers a card chunk type: a unified representation that bundles text, MRZ, photos, barcodes, and security features. This layout-aware approach ensures consistent accuracy, giving ADE the ability to parse identity documents out of the box and scale reliably across diverse and complex formats.
Introduction
Parsing identity documents such as passports, driver’s licenses, and ID cards is hard. The world of Intelligent Document Processing (IDP) constantly battles with such docs. Security features, machine-readable zones (MRZ), and diverse layouts (which are subject to change) break traditional OCR, template-based systems, and even LLM-based systems, leading to errors, compliance risks, and heavy manual correction.
Here comes Agentic Document Extraction from LandingAI. ADE for short. ! Purpose-built for addressing complex spatial arrangements and layouts. ADE is Agentic and Visual AI-First. What does that mean? It simply means that it treats documents as a visual representation of information and the underlying agentic system plans, decides, and acts to extract high-confidence document data in a consistent manner.
This is the key to preserving layout, extracting fields with spatial context, and returning schema-aligned outputs with confidence scores.
In this post, together we will explore the challenges of identity-document extraction and show how ADE makes parsing these complex documents robust and reliable.
ADE: A Fundamentally Different Approach
ADE, powered by LandingAI’s proprietary DPT models, represents a new paradigm for document intelligence that rests on three fundamental pillars:
Visual AI-first: Rather than treating a document as a flat stream of text or relying on brittle templates, ADE treats it as a visual representation of information. For identity documents, this means the system can handle holograms, overlapping text, and MRZ zones while preserving spatial relationships that traditional OCR often loses.
Agentic AI: ADE can plan, decide, and act to extract high-confidence document data in a consistent manner by orchestrating parsing logic, specialized vision and ML models, and an LLM that sequences steps, calls agents and tools, and verifies outputs until the extraction meets quality thresholds. In the context of ID cards, this allows ADE to resolve conflicts (for example, distinguishing a watermark from a printed name) and validate structured outputs such as MRZ checksums.
Data-Centric AI: With established data engineering practices, LandingAI curates proprietary, high-quality datasets for document understanding. These curated datasets are improved through structured feedback loops, ensuring predictable improvements over time. Document-native visual AI models trained on this high-quality data achieve the highest levels of accuracy. For identity documents, this ensures ADE continuously adapts to evolving layouts and new security features introduced by governments and issuers.
Traditional Approaches and Their Limits
Most organizations still rely on tools that were never designed for the complexity of identity documents.
OCR systems work on clean, printed text but fail when faced with holograms, watermarks, unusual fonts, or overlapping design elements. In ID cards, this often results in misreads such as interpreting a “VOID” watermark as part of a name, or skipping text printed over a security feature.
Template-based systems depend on fixed layouts. A new version of a driver’s license, a shifted field, or even a tilted scan can break the pipeline entirely, forcing constant reconfiguration and maintenance. With thousands of ID formats across states and countries, templates quickly become unmanageable.
Rule-based systems pile on exceptions for each variation. Over time, thousands of interacting rules create fragile pipelines that are hard to scale and nearly impossible to maintain. For identity cards, even minor changes such as a font update or new background pattern can invalidate entire rule sets.
LLM-based systems add reasoning power but still operate on flattened text, losing the visual and spatial context that IDs depend on. Without grounding, LLMs may confuse labels with values, hallucinate missing fields, or misinterpret MRZs and barcodes. For regulated use cases like KYC or border control, these inconsistencies are unacceptable.
The underlying issue is the same: these approaches reduce extraction to transcription. Identity documents require intelligence: the ability to interpret context, adapt to variation, and make reliable decisions even when information is obscured, noisy, or incomplete.
Chunk Types in ADE
When ADE processes a document, it breaks the content into chunks—coherent units like text blocks, tables, figures, or marginal notes. Each chunk includes metadata describing both its content and its position in the original document, making it easier to use for downstream tasks such as search, validation, or analysis.
The most relevant chunk types for identity documents extracted with ADE are:
logo — official emblems or seals
card — identity documents packaged as a single structured object (fields, MRZ, photo, barcodes, security features)
attestation — signatures or certification statements
scan_code — QR codes and barcodes
For identity documents, these new chunk types are critical. Card unifies printed fields, MRZ, photos, barcodes, and security features; scan_code captures QR codes and barcodes; attestation represents signatures and certifications; and logo identifies official seals. Together they enable ADE to parse IDs as complete, trustworthy entities, ensuring consistent extraction and reliable validation even as formats evolve.
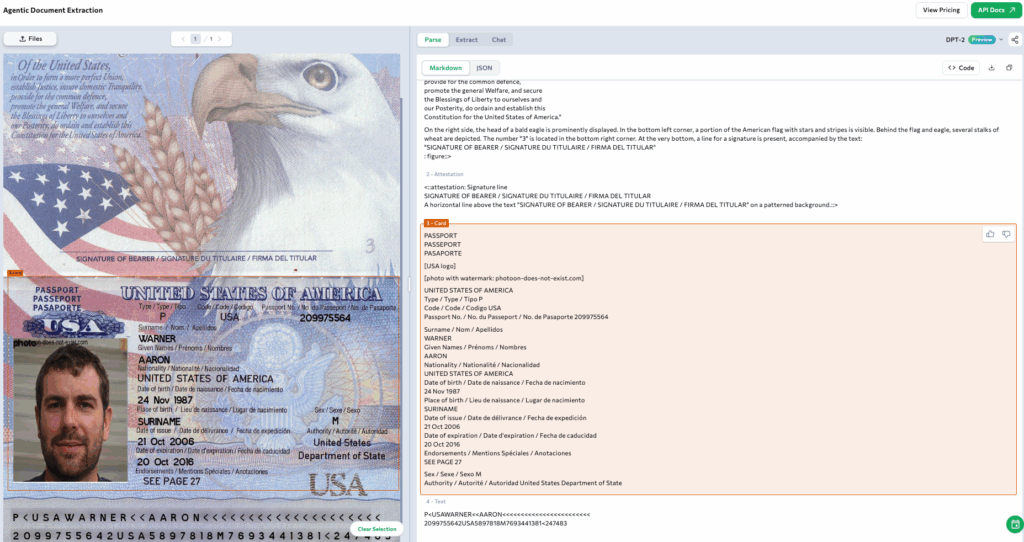
ADE Playground displaying a U.S. passport parsed with the card chunk type
Let’s see how ADE applies schema-driven extraction, layout-aware parsing, and visual grounding to the same U.S. passport example.
Schema-Driven Extraction
Extraction begins with a schema: you define the fields that matter. Suppose you only need the passport number. You specify that single field, and ADE parses the document, then performs extraction to return the value. If you extend the schema to include surname or date of birth, ADE populates those as well. This ensures outputs are consistent, structured, and aligned with your workflow—whether you extract one field or many.
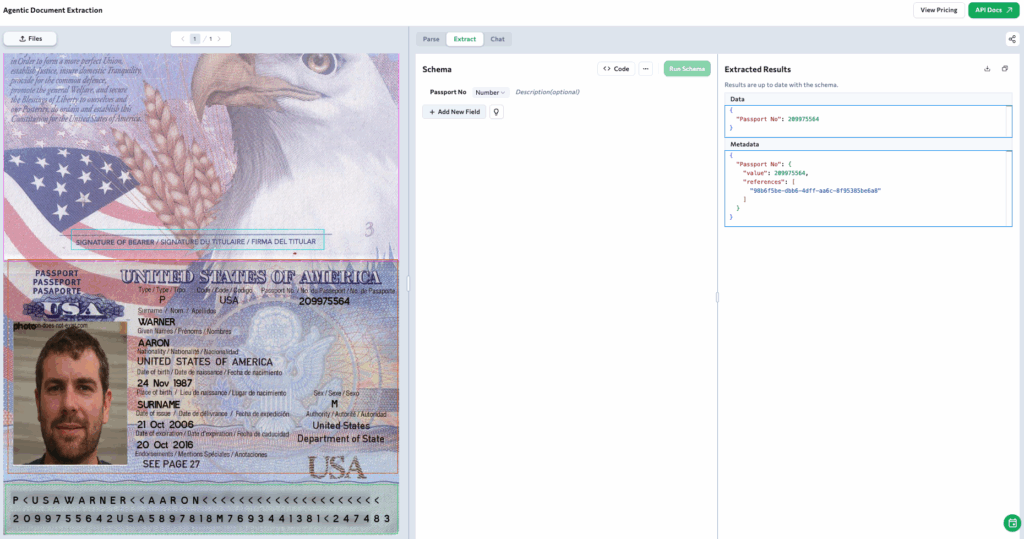
Layout-Aware Parsing
Identity documents often combine multiple elements on the same page. In the U.S. passport example, ADE identifies and separates distinct parts of the document: the figure showing the eagle and flag, the attestation box for a signature, and the card containing the personal details. By parsing each into structured chunks, ADE preserves the logical organization of the page. This ensures fields remain tied to their correct sections rather than being flattened into disconnected text.
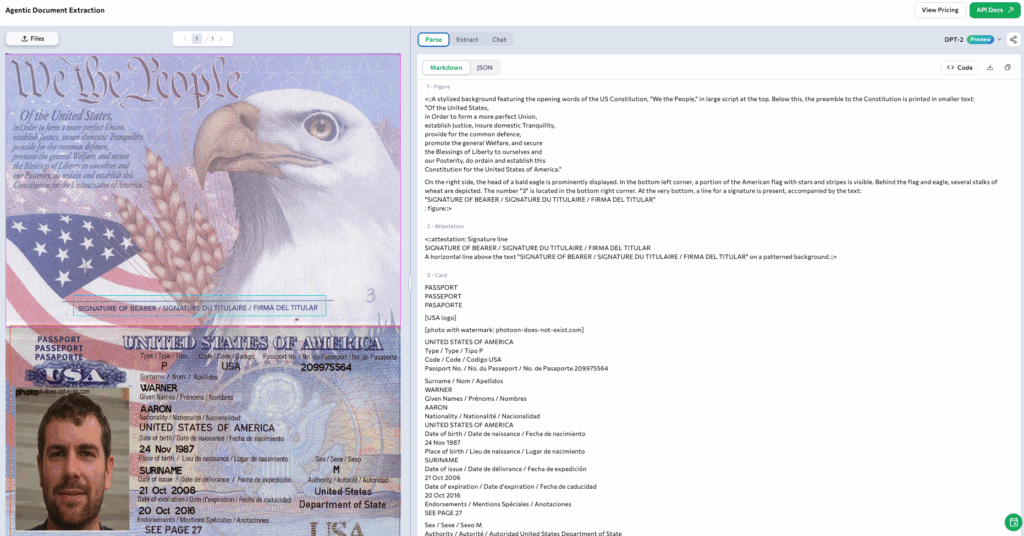
Visual Grounding
Every extracted chunk is tied back to its exact origin in the document. In this passport, ADE grounds the entire card object by recording its bounding box coordinates and the page number.
The JSON output below shows how the grounding object points to page 0 and the box object defines the precise region of the card. This creates a verifiable link between the extracted data and its source, ensuring trust and auditability.

ADE on Other Identity Documents
While the U.S. passport example shows ADE’s schema-driven and layout-aware capabilities, the same approach extends seamlessly to other identity documents with different formats, security layers, and layouts. Let’s look at a few examples.
U.S. Driver’s License
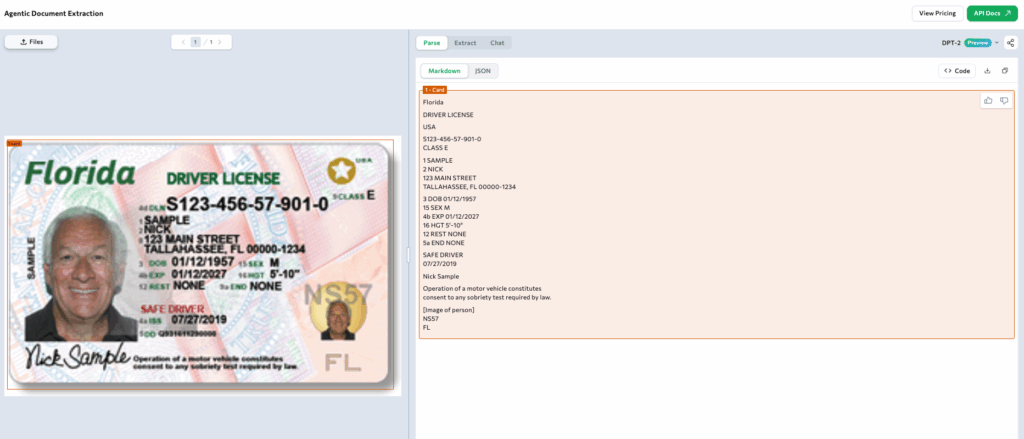
U.S. Driver’s License — parsed as a card chunk capturing all printed fields and visual layers with consistent alignment.
U.S. Green Card
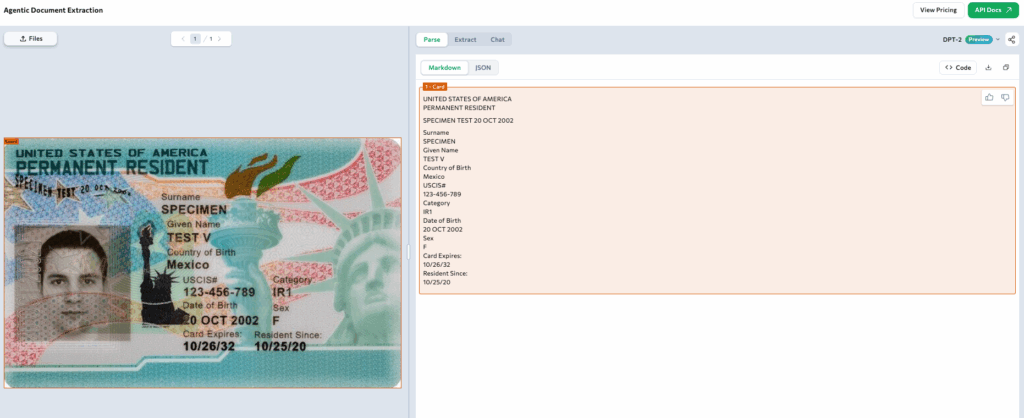
U.S. Green Card — parsed as a card chunk combining text, barcodes, and embedded graphics.
German Identity Card
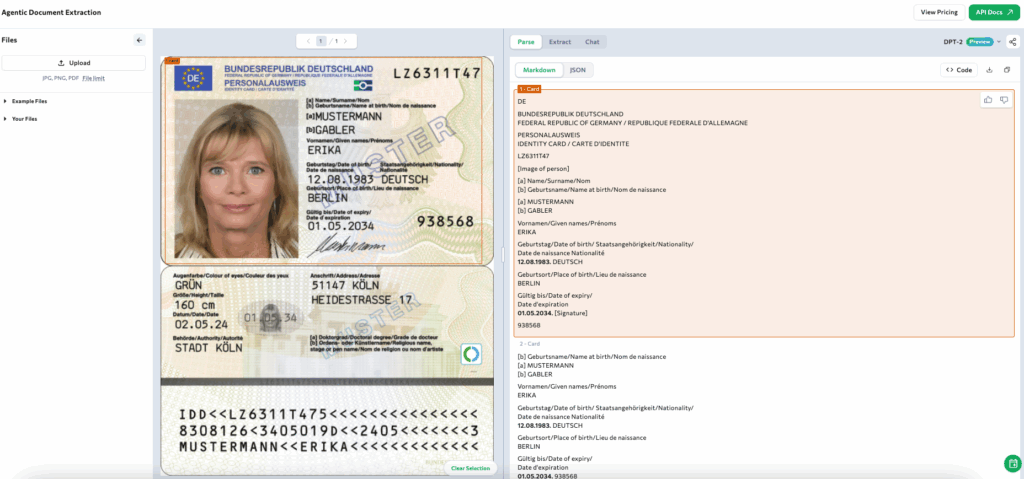
German Identity Card — parsed as a card chunk preserving multilingual fields, MRZ, and signature areas.
From licenses to green cards to national IDs, structured parsing stays consistent across formats. Try it out on your own identity document in the ADE Playground.
Revisiting Identity Documents: Importance and Complexity
Why Identity Documents Matter
Identity documents are the foundation of trust in modern systems.
Banks depend on them for Know Your Customer (KYC) and Anti-Money Laundering (AML) checks.
Healthcare providers use them to confirm patient identity and comply with privacy laws.
Passports, driver’s licenses, and national ID cards function as trusted proof of identity almost everywhere, from travel and public services to everyday transactions.
Errors in processing are not minor. A single misread digit can trigger compliance violations, financial losses, or security breaches. Accuracy is mandatory, not optional.
Built for Security, Not Automation
Identity documents are designed to resist tampering, not to simplify machine reading. Their security features are layered and deliberate:
Holograms and watermarks obscure text.
Machine-readable zones (MRZs) require checksum validation.
Barcodes and embedded chips carry additional data.
Special inks, microtext, and overlapping stamps add visual noise.Each element strengthens security for humans but makes automated extraction significantly harder.
Why They Are So Challenging
The complexity does not stop at security features. Layouts vary widely across countries, issuers, and even versions of the same document. Governments redesign licenses and passports regularly, which means a pipeline tuned to last year’s format often fails when a new background pattern or font is introduced. Additional challenges include:
Varied layouts across issuers.
Evolving designs that render templates obsolete.
Overlapping elements that confuse OCR engines.
Multi-modal content where text, photos, barcodes, and MRZs all need to be interpreted together.
Real-World Variability
Consider just one country: every U.S. state issues its own driver’s license, each with unique layouts, holograms, and security features. A California license from 2019 looks completely different from one issued in 2023, and neither resembles a license from Texas or New York. Passports include MRZ codes, evolving backgrounds, and layered watermarks. Green cards combine photos, holograms, and chips, while military IDs add barcodes and additional verification standards. Across countries, this variety multiplies into thousands of unique, evolving formats, creating a massive challenge for automated systems.
Conclusion
By now, you already know how identity documents resist automation. Their evolving layouts, layered security features, and multimodal content make them one of the most complex document types to parse. Traditional OCR, template-based systems, rule engines, and even LLM-based approaches cannot keep pace, leading to costly manual work, compliance risks, and unreliable outcomes.
Agentic Document Extraction (ADE) changes this by introducing a new paradigm. Powered by the Document Pre-Trained Transformer model family and its specialized card chunk type, ADE unifies text, MRZ, photos, barcodes, and security features into a single, trustworthy representation.
The result is consistent, schema-driven, and verifiable extraction that scales across issuers, formats, and evolving designs. For industries where accuracy is non-negotiable, such as banking, healthcare, and government, ADE provides a foundation that is both reliable and auditable.
As identity documents continue to evolve, ADE ensures organizations can meet compliance standards, reduce manual intervention, and build systems of trust that scale into the future.
Try your own identity document in the ADE Playground.