Introduction
Modern Large Language Models (LLMs) have revolutionized text analysis—until they encounter the complexities of PDFs. PDFs often feature intricate layouts, visual elements, flowcharts, images, and tables with interdependent contexts and relationships. This is where Agentic Document Extraction truly stands out. In Part 1, we demonstrated examples where traditional LLMs struggled, while Agentic Document Extraction excelled by delivering precise answers, providing visual grounding, and offering correct citations from complex academic and technical documents. In this post, we’ll explore how to leverage the Agentic Document Extraction API in your own applications—from understanding its JSON schema to building features like interactive, highlightable user interfaces and advanced LLM prompting.
1. Understanding the JSON Schema Returned by the API
The Agentic Document Extraction API provides both a human-friendly and machine-friendly data representation. Below is the top-level schema:
JSON
{
"$defs": {
"Chunk": {
"properties": {
"text": { "type": "string" },
"grounding": {
"type": "array",
"items": { "$ref": "#/$defs/ChunkGrounding" }
},
"chunk_type": { "$ref": "#/$defs/ChunkType" },
"chunk_id": { "type": "string" }
},
"required": ["text", "grounding", "chunk_type", "chunk_id"],
"type": "object"
},
"ChunkGrounding": {
"properties": {
"box": { "$ref": "#/$defs/ChunkGroundingBox" },
"page": { "type": "integer" }
},
"required": ["box", "page"],
"type": "object"
},
"ChunkGroundingBox": {
"properties": {
"l": { "type": "number" },
"t": { "type": "number" },
"r": { "type": "number" },
"b": { "type": "number" }
},
"required": ["l", "t", "r", "b"],
"type": "object"
},
"ChunkType": {
"enum": [
"title", "page_header", "page_footer", "page_number",
"key_value", "form", "table", "figure", "text"
],
"type": "string"
}
},
"properties": {
"markdown": { "type": "string" },
"chunks": {
"type": "array",
"items": { "$ref": "#/$defs/Chunk" }
}
},
"required": ["markdown", "chunks"],
"type": "object"
}
Key Points to Note
- Separation of Data and Presentation
markdown: A user-friendly representation of the document (ideal for quick display or for sending as context to an LLM).chunks: Each chunk contains the granular metadata, including bounding boxes and chunk types.
- Granular Location Control
- Each chunk includes one or more
groundingentries. Eachgroundingties that chunk to a page index and a bounding box in relative coordinates. - Why Relative Coordinates? Because they remain valid regardless of DPI or scaling when rendering the PDF to an image. This is especially helpful for stable highlight overlays.
- Each chunk includes one or more
- LLM-Friendly Size
- The schema is designed so that each chunk is relatively small. If you need to do Retrieval Augmented Generation (RAG), you can store these chunks in a vector database and retrieve just the relevant text.
Handy Tip: The API supports various parameters like return_chunk_crops and parse_figures. Check the official docs for more advanced uses—whether you need chunk-level images, entire pages, or specialized figure extractions.
2. Building the “Chat with PDF” Experience
Let’s look at how you might integrate the Agentic Document Extraction API into a simple Streamlit application—one that does page-by-page extraction, asks LLM questions, and visually grounds each answer.
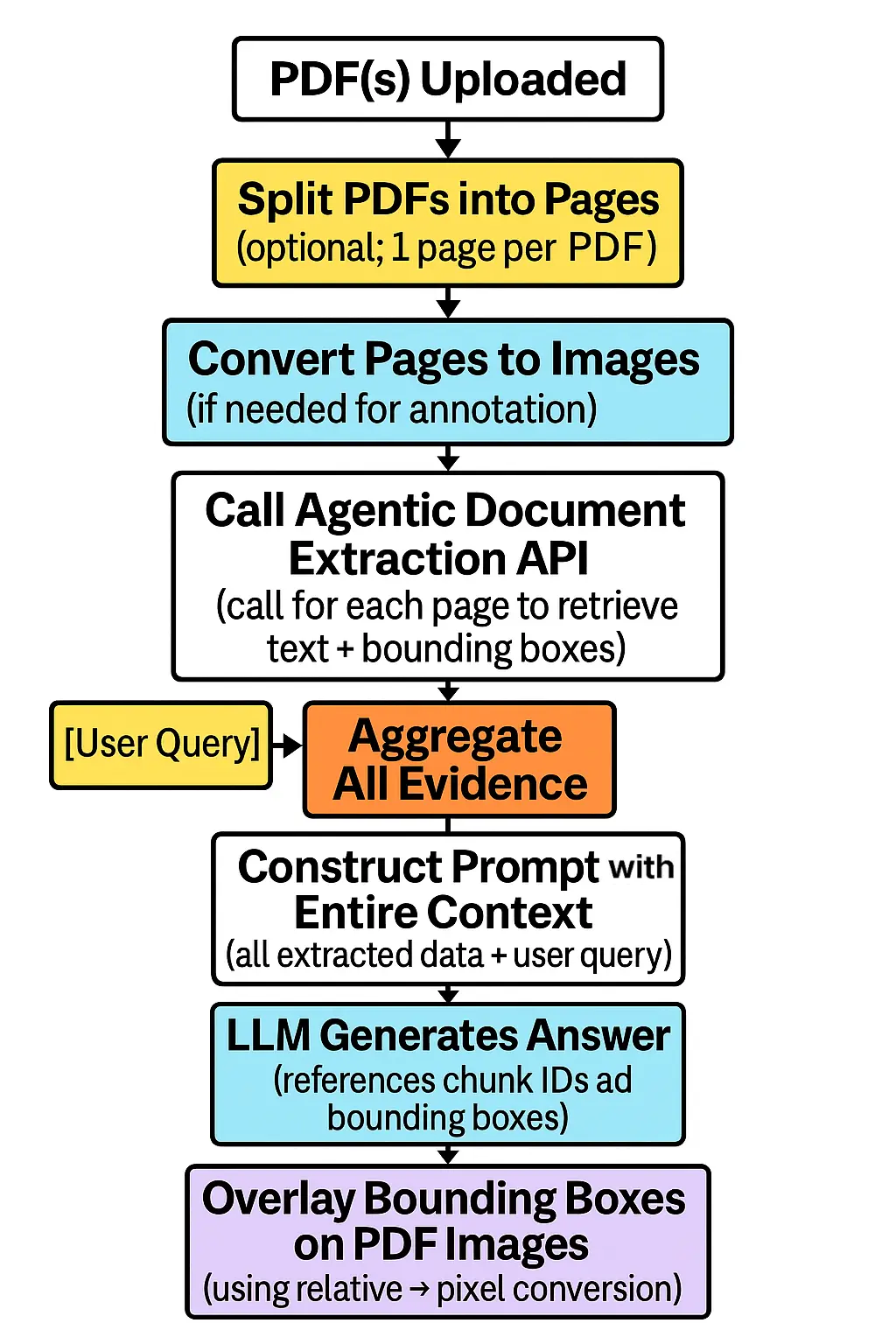
Overall flow for creating a “Chat with PDF” App using Agentic Document Extraction API
2.1 PDF Processing
Splitting PDFs into Single Pages
Splitting PDFs page by page can help keep requests lightweight. For instance:
def split_pdf_into_chunks(pdf_file):
"""Split a PDF into individual pages (1 page per chunk)."""
try:
reader = PdfReader(pdf_file)
except Exception as e:
st.error(f"Error reading PDF: {e}")
return None, 0
total_pages = len(reader.pages)
chunks = []
for i in range(total_pages):
writer = PdfWriter()
writer.add_page(reader.pages[i])
pdf_chunk_buffer = io.BytesIO()
writer.write(pdf_chunk_buffer)
pdf_chunk_buffer.seek(0)
chunks.append(pdf_chunk_buffer.getvalue())
return chunks, total_pages
Because dealing with 50-page PDFs in a single request might be overkill. By splitting, you control concurrency and scale better.
Converting PDF Pages to Images
Next, convert each page to an image. This allows you to overlay bounding boxes later:
def pdf_to_images(pdf_file):
"""
Convert each page of the PDF to an image for highlight overlays.
Returns a list of images and (width, height) dimensions per page.
"""
images = []
page_dims = []
try:
import fitz # PyMuPDF
pdf_document = fitz.open(stream=pdf_file.read(), filetype="pdf")
for page in pdf_document:
rect = page.rect
page_dims.append((rect.width, rect.height))
# We'll go with 200 DPI for a clearer image
pix = page.get_pixmap(dpi=200)
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
images.append(np.array(img))
pdf_document.close()
except Exception as e:
st.error(f"Error converting PDF to images: {e}")
return images, page_dims
Mini Humor: “200 DPI is a sweet spot—any higher and your computer might start whispering, ‘Enough with the high-res, please!’”
2.2 API Integration
Calling the Agentic Document Extraction API
def call_api(pdf_bytes, api_key):
url = "https://api.landing.ai/v1/tools/document-analysis"
files = {"pdf": ("chunk.pdf", io.BytesIO(pdf_bytes), "application/pdf")}
data = {
"parse_text": True,
"parse_tables": True,
"parse_figures": True,
"summary_verbosity": "none",
"caption_format": "json",
"response_format": "json",
"return_chunk_crops": False,
"return_page_crops": False,
}
headers = {"Authorization": f"Basic {api_key}"}
response = requests.post(
url, files=files, data=data, headers=headers,
timeout=600, verify=False
)
try:
return response.json()
except Exception as e:
return {"error": str(e), "response_text": response.text}
Notice how we set parse_tables and parse_figures to True. This ensures you capture structured elements like tables and images with bounding boxes.
Retry Logic
Network issues happen. Adding a retry mechanism helps:
def call_api_with_retry(pdf_bytes, api_key, max_retries=3, backoff_factor=2):
for attempt in range(max_retries):
try:
# Same data and headers as above
url = "https://api.landing.ai/v1/tools/document-analysis"
files = {"pdf": ("chunk.pdf", io.BytesIO(pdf_bytes), "application/pdf")}
data = {
"parse_text": True,
"parse_tables": True,
"parse_figures": True,
"summary_verbosity": "none",
"caption_format": "json",
"response_format": "json",
"return_chunk_crops": False,
"return_page_crops": False,
}
headers = {"Authorization": f"Basic {api_key}"}
response = requests.post(
url, files=files, data=data, headers=headers,
timeout=600, verify=False
)
response.raise_for_status()
return response.json()
except Exception as e:
if attempt == max_retries - 1:
return {"error": str(e), "response_text": getattr(response, 'text', str(e))}
wait_time = backoff_factor ** attempt
st.warning(f"Attempt {attempt + 1} failed. Retrying in {wait_time} seconds...")
time.sleep(wait_time)
2.3 Evidence Aggregation & Caching
After processing each PDF, gather all extracted chunks and store them in Streamlit’s session_state, for quick retrieval during queries:
st.session_state.all_evidence = all_evidence
st.session_state.all_images = all_images
st.session_state.all_page_dims = all_page_dims
st.session_state.all_total_pages = all_total_pages
st.session_state.processed_pdfs = current_pdfs
st.session_state.raw_api_responses = raw_api_responses
Leverage caching for repetitive calculations, like converting bounding boxes:
@lru_cache(maxsize=128)
def calculate_scale_factors(img_width, img_height, pdf_width, pdf_height):
"""
Calculate scale factors to map PDF space to image space.
We subtract 0.7 arbitrarily to handle minor dimension variances.
Because who doesn't love random offsets?
"""
scale_x = img_width / pdf_width - 0.7
scale_y = img_height / pdf_height - 0.7
return scale_x, scale_y
This quick caching trick ensures you’re not recalculating scale factors every time you highlight bounding boxes.
2.4 Querying the LLM
Use your extracted data to form a prompt. You can feed either the entire markdown or curated chunks into the LLM, instructing it to return a structured JSON response:
def get_answer_and_best_chunks(user_query, evidence):
"""Use the following JSON evidence extracted from the uploaded PDF files to answer the question."""
try:
client = OpenAI()
chat_response = client.chat.completions.create(
model="gpt-4o",
messages= [
{
"role": "system", "content": "You are a helpful expert that provides accurate, detailed answers."},
{
"role": "user", "content": prompt},
],
temperature=0.5,
)
raw = chat_response.choices[0].message.content.strip()
# Clean markdown fences if present
if raw.startswith("```"):
lines = raw.splitlines()
if lines[0].startswith("```"):
lines = lines[1:]
if lines and lines[-1].startswith("```"):
lines = lines[:-1]
raw = "\n".join(lines).strip()
parsed = json.loads(raw)
return parsed
except Exception as e:
st.error(f"Error getting answer from ChatGPT: {e}")
return {
"answer": "Sorry, I could not retrieve an answer.",
"reasoning": "An error occurred.",
"best_chunks": []
}
Pro Tip: If you have a large number of PDF chunks, consider storing them in a vector store first and retrieving only the relevant ones (RAG approach).
2.5 Annotating and Visualizing Evidence
Finally, highlight relevant bounding boxes on each PDF page. Convert bounding box coordinates from PDF-relative (0–1) to image pixel coordinates:
def process_chunks_parallel(chunks_list, img, scale_factors, offset_x, offset_y, invert_y):
"""Draw bounding boxes on the image based on chunk data."""
img_height, img_width = img.shape[:2]
scale_x, scale_y = scale_factors
total_boxes = sum(len(chunk.get("bboxes", []) for chunk in chunks_list)
boxes = np.zeros((total_boxes, 4), dtype=np.int32)
box_idx = 0
for chunk in chunks_list:
bboxes = chunk.get("bboxes", [])
for bbox in bboxes:
if len(bbox) == 4:
x1 = int(bbox[0] * scale_x)
x2 = int(bbox[2] * scale_x)
if invert_y:
y1 = int(img_height - (bbox[3] * scale_y))
y2 = int(img_height - (bbox[1] * scale_y))
else:
y1 = int(bbox[1] * scale_y)
y2 = int(bbox[3] * scale_y)
x1 = max(0, min(x1 + offset_x, img_width - 1))
x2 = max(0, min(x2 + offset_x, img_width - 1))
y1 = max(0, min(y1 + offset_y, img_height - 1))
y2 = max(0, min(y2 + offset_y, img_height - 1))
boxes[box_idx] = [x1, y1, x2, y2]
box_idx += 1
for box in boxes[:box_idx]:
cv2.rectangle(img, (box[0], box[1]), (box[2], box[3]), (0, 255, 0), 2)
return img
The function name process_chunks_parallel might be an overstatement if it’s not using actual parallelism, but hey, it’s punchy!
Convert and display the result as a PDF:
def image_to_pdf(image):
"""Save the annotated image as a temporary PDF.
Great if you want to show a side-by-side of original vs. highlighted evidence."""
temp_img = tempfile.NamedTemporaryFile(suffix=".png", delete=False)
Image.fromarray(image).save(temp_img.name)
temp_img.close()
pdf = FPDF(unit="mm", format="A4")
pdf.add_page()
pdf.image(temp_img.name, x=0, y=0, w=210)
temp_pdf = tempfile.NamedTemporaryFile(suffix=".pdf", delete=False)
pdf.output(temp_pdf.name)
temp_pdf.close()
return temp_pdf.name
Then embed the PDF in Streamlit:
def display_pdf(pdf_path):
with open(pdf_path, "rb") as f:
base64_pdf = base64.b64encode(f.read()).decode('utf-8')
pdf_display = f'<iframe src="data:application/pdf;base64,{base64_pdf}" width="100%" height="600px"></iframe>'
st.markdown(pdf_display, unsafe_allow_html=True)
3. Deployment, Scalability, and Security
When moving to production, keep these points in mind:
- Error Handling & Retries: You’ve already got basic retries. Also consider specialized logging and monitoring so you can track recurring issues (e.g., timeouts).
- Caching and Vector Stores: Use Python caching (as shown) for small tasks. For bigger ones, adopt a vector store (like FAISS, Pinecone, or Milvus) to handle retrieval for hundreds of pages or PDFs.
- Secure Your Keys: Don’t commit your API keys to GitHub or store them in plaintext. Use environment variables or secret managers (e.g., HashiCorp Vault, AWS Secrets Manager) in production.
- SSL and Verification: For maximum security, keep TLS verification enabled in your requests—especially if operating in regulated industries.
4. Potential Enhancements
- Retrieval Augmented Generation (RAG)
- Instead of dumping all evidence into the context window for each LLM query, store each chunk in a vector database. When the user queries, perform a semantic search to grab only the relevant chunks. This:
- Reduces token usage.
- Improves relevance and speed.
- Scales to a large corpus without memory issues.
- Instead of dumping all evidence into the context window for each LLM query, store each chunk in a vector database. When the user queries, perform a semantic search to grab only the relevant chunks. This:
- Multi-PDF & Document-Level Merging
- If you have many PDFs, unify all chunked data into a single index. Queries can then reference the entire dataset, returning the best evidence from across multiple documents.
Pro Tip: RAG not only trims costs but also drastically cuts down on nonsense or “hallucinated” references from the LLM.
5. Final Thoughts
Agentic Document Extraction enables you to create advanced, document-driven applications that not only extract meaningful data but also provide verifiable, visually grounded answers—reducing hallucinations and increasing user trust.
Happy building! If you have any questions, feel free to reach out. We can’t wait to see the creative ways you’ll harness this API in your own applications.