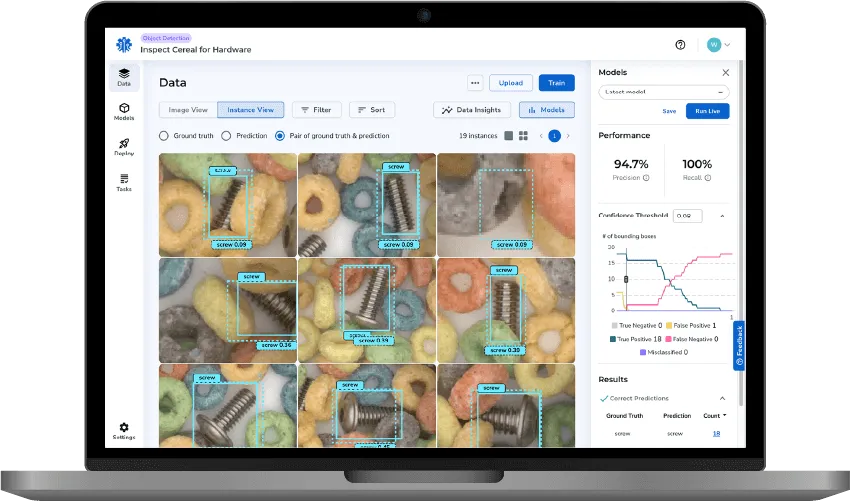
Data-Centric AI:
A Data-Driven Machine Learning Approach
“Instead of focusing on the code, companies should focus on developing systematic engineering practices for improving data in ways that are reliable, efficient, and systematic. In other words, companies need to move from a model-centric approach to a data-centric approach.”
What Is Data-Centric AI?
Data-centric AI is the discipline of systematically engineering the data used to build an AI system. Think of it as programming with a focus on data rather than code. While AI models have evolved significantly, a fundamental shift is needed to truly unlock AI's full potential. Instead of solely improving model architectures, a data-centric approach emphasizes refining and optimizing the quality of data to enhance AI performance.
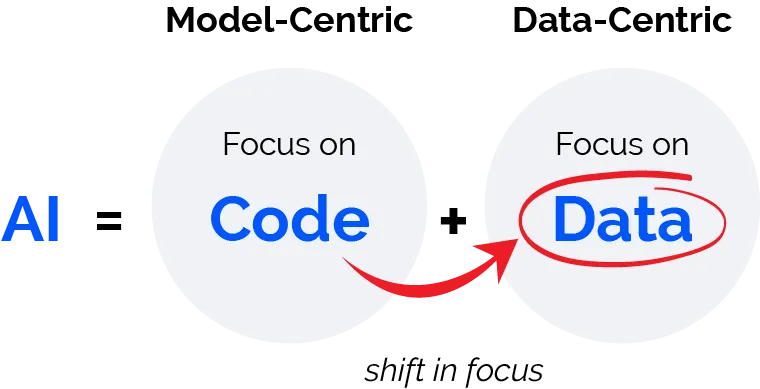
Why Does Data-Centric AI Matter?
Adopting a data-centric AI approach has helped companies across industries—including automotive, electronics, and medical device manufacturing—deploy AI and deep learning-based computer vision solutions more effectively than traditional, rules-based methods. By shifting the focus to data quality, businesses can achieve greater accuracy, scalability, and efficiency, making AI benefits more accessible to a wider range of organizations.
- Build computer vision applications 10x faster
- Reduced time to deploy application
- Improved yield and accuracy

Challenges: Rules-Based Computer Vision
Rules-based machine vision algorithms may struggle with inconsistencies that are the result of working with parts with complex features or ambiguous part defects.
Inconsistencies and High-Rejection Rates
Producing high-quality products remains a top priority for companies. Defective parts present:
- Safety issues
- Damaged customer relationships
- Lost revenue
Identifying defective parts early in the process helps mitigate these risks. Machine vision technologies offer an effective method for doing so but may come up short in certain instances. Introducing new or custom parts or working in an environment that constantly changes, such as lighting conditions in a plant with large windows, can also be problematic. In these scenarios, rules-based algorithms can produce a high rejection rate, as the technology cannot distinguish between actual defective parts and acceptable variation, which necessitates a high rate of human follow-up inspection, increasing costs and slowing down production lines.
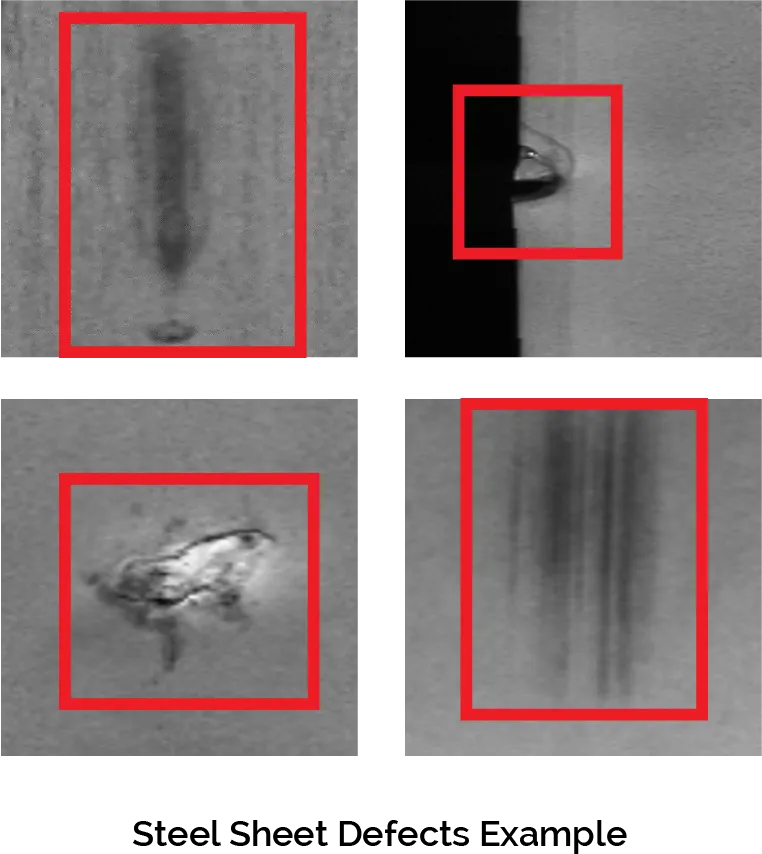
Challenges: Conventional Model-Centric AI Approach
If human experts disagree on a label, how can the AI system be expected to make such a determination? For applications with small datasets and rare defects, this becomes even more problematic.
“Is this really a scratch?”
In scenarios where rules-based algorithms will not suffice, many companies turn to AI and deep learning solutions yet still encounter challenges. Without a consistent data management approach, for instance, an AI system cannot accurately inspect products. While the system can analyze images of products on an assembly line and identify defects such as scratches and dents, this can present a challenge as well because human experts won't always agree on appropriate labels when it comes to describing the damage.

Taking Long Time to Develop and Deploy
Developers often work with subject matter experts to define defects. Maintaining models and adapting to new circumstances such as new parts or environmental changes presents challenges and delays in development and deployment. In many cases, it may take several months to create and deploy an AI model.

Challenges to Standardize Workflow and Scale Projects
Standardizing a workflow and scaling AI solutions also presents challenges. Different teams use different methods to develop AI solutions, work with quality teams, and manage data, making it difficult for teams to learn from other groups and standardize workflow. Given such circumstances, scaling even one team to develop a solution can be onerous.

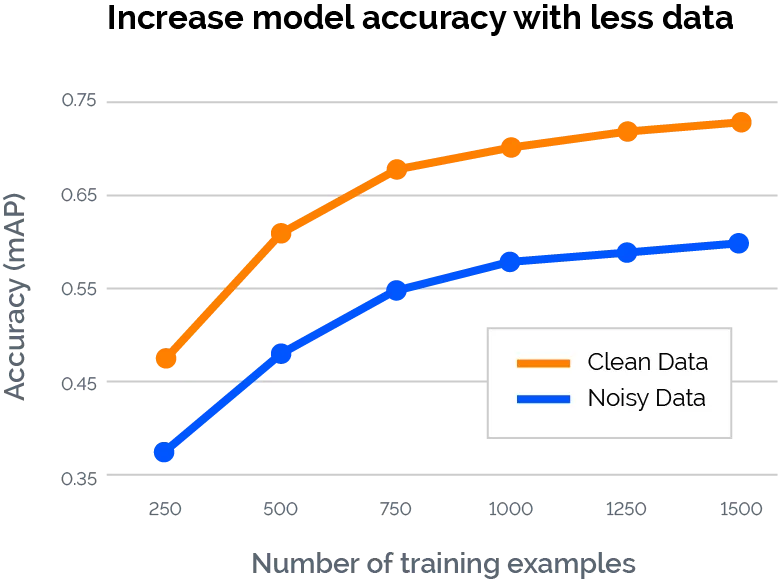
Data-Centric AI Improves Data and Model Accuracy
Data-Centric AI Impacts Performance
A data-centric AI approach involves building AI systems with high-quality, well-structured data, ensuring that the AI learns exactly what it needs. Unlike traditional model-centric methods, data-centric artificial intelligence focuses on refining data quality rather than endlessly tweaking models. This shift helps teams achieve the required performance levels while eliminating unnecessary trial-and-error when working with inconsistent data.
Data-Centric AI Promotes Collaboration
Quality managers, subject matter experts, and developers can work together during the development process to:
- Reach a consensus on defects and labels
- Build a model
- Analyze results
- Make further optimizations
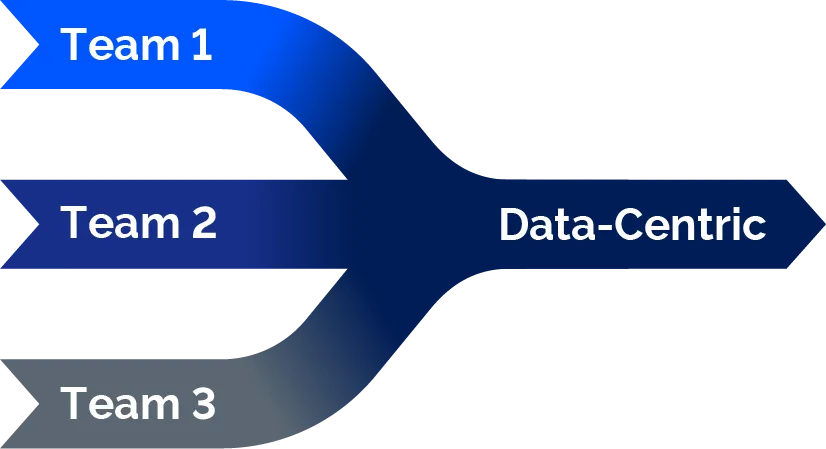
Data-Centric AI Reduces Development Time
With such an approach, teams can work in parallel and directly influence the data used for the AI system. By removing unnecessary back and forth among groups and looping in human input at the point where it's needed most, the result is reduced development time. Let's compare the data-centric approach to the model-centric approach in terms of which one is more approachable.
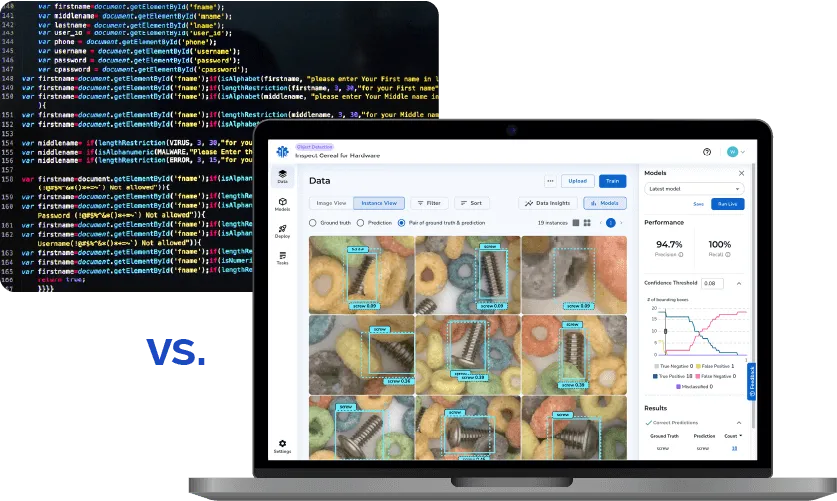
Even More Benefits of Data-Centric AI
Additional benefits of data-centric artificial intelligence include the ability for teams to develop consistent methods for collecting and labeling images and for training, optimizing, and updating the models. Teams easily learn from a past project's success and can apply that knowledge to quickly scale new projects.
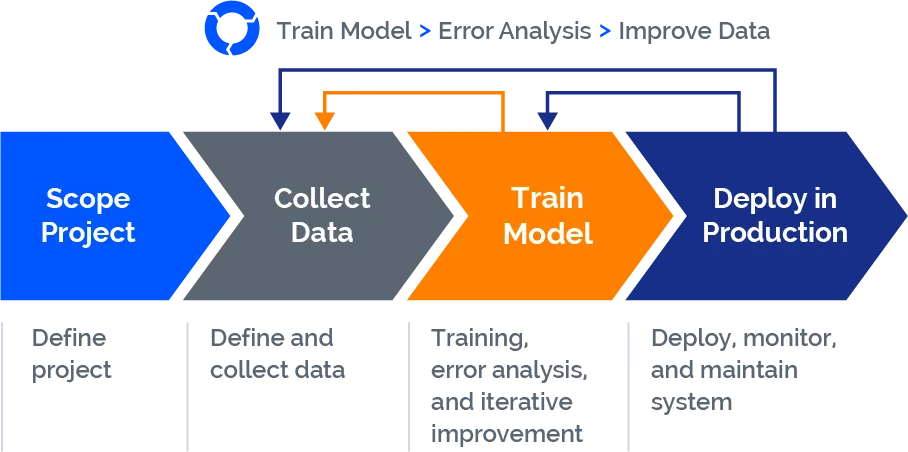
LandingLens: Data-Centric AI in Action
LandingLens, an industry-leading data-centric deep learning platform, helps ensure product quality through improved inspection accuracy and reduced false rejections. The platform standardizes developing deep learning solutions, reducing development time and scaling projects efficiently across multiple facilities. By adopting LandingLens' data-driven AI, businesses can increase throughput, maintain product quality, and drive revenue with reliable AI solutions.