What Is Agentic Object Detection?

Agentic Object Detection (OD) is one of the tools available to developers within VisionAgent. It achieves highly competent zero-shot object detection on complex tasks by reasoning agentically about images. By applying agentic patterns such as planning, code generation, and tool use, Agentic OD can reliably detect everyday objects (e.g. “person”, “motorcycle”) as well as more complex objects (e.g. “worker not wearing a helmet”, “rotten pepper”, “red shoes”). On LandingAI’s internal OD benchmark, Agentic OD achieved 79.7% F1, surpassing Large Multimodal Models (LMMs) such as Qwen2.5-VL-7B-Instruct and GPT-4o, as well as open set OD models such as Florence-2 and OWLv2.
How to Use Agentic Object Detection
Agentic OD is available as a web app, allowing users to test various prompts on sample images as well as images that they upload.
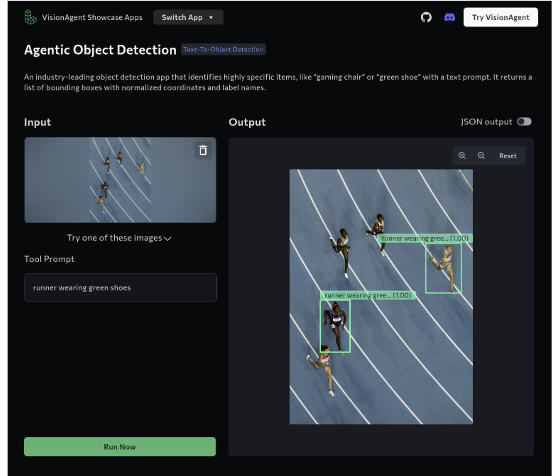
Developers looking to include OD functionality in their applications can use the Agentic OD API:
Inputs: A short
**prompt**describing the objects of interestOutputs: A list of boxes in [Xmin, Ymin, Xmax, Ymax] format corresponding to each detected instance of the
**prompt**
Use Cases
In the current version, Agentic OD excels at detecting two broad categories of objects.
The first category, which we term Everyday Objects, consists of common objects like those found in ImageNet and COCO. These are nouns which do not have additional qualifiers, such as “pepperoni”, “puzzle piece”, and “number”. Below are some examples of Agentic OD running on Everyday Objects:
| Prompt | pepperoni | puzzle piece | number |
|---|---|---|---|
| Image | 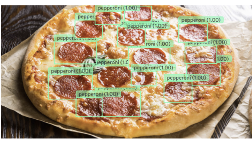 |  |  |
The second category, which we term Everyday Objects with Attributes, extends the previous category by allowing additional qualifiers, such as “yellow vehicle” (color), “cell phone with antenna” (possession), “horizontal pen” (orientation), etc. Below are some examples of Agentic OD running on Everyday Objects with Attributes:
| Prompt | yellow vehicle | cell phone with antenna | horizontal pen |
|---|---|---|---|
| Image |  |  |  |
Benchmark Evaluation
To ensure that any benchmark metrics are well-aligned with our targeted use cases, we have created an internal benchmark using a subset of 100 images from the PixMo-Points dataset. We have labeled these images with bounding boxes corresponding to multiple prompts. The distribution across different kinds of attributes is shown below:
| Attribute Type | Count | Example |
|---|---|---|
| Base Object Only (Find X) | 61 | strawberry |
| Part of Whole (X is within Y – find X) | 5 | empty space in egg carton |
| Containment (X contains Y – find X) | 34 | cell phone with antenna |
| State (X is currently Y – find X) | 16 | open hand |
| Color (Find <color> X) | 37 | red helmet |
| Direction (<direction> X) | 4 | horizontal pen |
| Proper Noun (Find “Mickey Mouse”) | 4 | Mickey Mouse |
| Counting (N of X – find X) | 6 | stack of two cards |
| OCR (X contains <text> – find X) | 9 | book by David Mamet |
Given this dataset, we evaluated Agentic OD and computed the F1 score. For comparison, we also evaluated Florence-2 and OWLv2 (open set OD models) in addition to directly prompting Qwen2.5-VL-7B-Instruct and GPT-4o (non-agentic LMM flow).
| Approach | Category | Recall | Precision | F1-score |
|---|---|---|---|---|
| Agentic OD (LandingAI) | Agentic | 77.0% | 82.6% | 79.7% |
| Florence-2 (Microsoft) | Open Set OD | 43.4% | 36.6% | 39.7% |
| OWLv2 (Google) | Open Set OD | 81.0% | 29.5% | 43.2% |
| Qwen2.5-VL-7B-Instruct (Alibaba) | LMM | 26.0% | 54.0% | 35.1% |
| GPT-4o (OpenAI) | LMM | 0% | 0% | 0% |
Overall, Agentic OD has the highest F1-score, at 79.7%. While OWLv2 has a higher recall, it suffers greatly in terms of precision. Qwen2.5, despite making a large improvement in OD performance for LMMs, is still significantly worse than Agentic OD – while the counts of boxes are typically correct, the locations are entirely off.
For visualization, we also present predictions on individual samples from our benchmark dataset:
| Prompt | Original image | Agentic OD | Florence-2 |
|---|---|---|---|
| runner with green shoes |  |  | 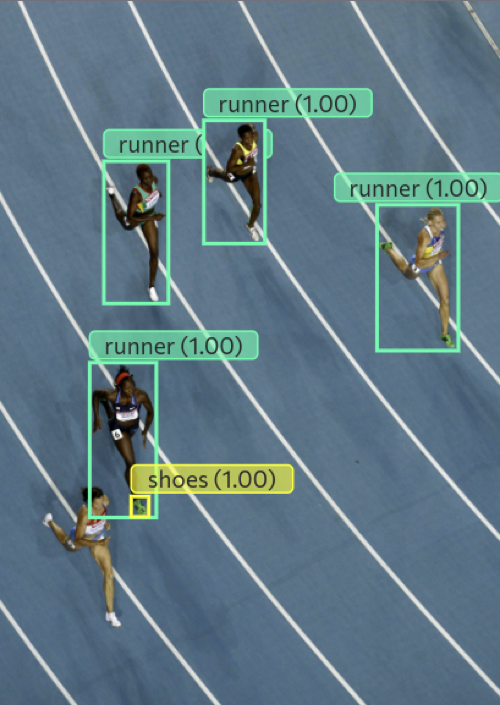 |
| Prompt | OWLv2 | Qwen2.5-VL-7B-Instruct | GPT-4o |
| runner with green shoes |  |  |  |
| Prompt | Original image | Agentic OD | Florence-2 |
|---|---|---|---|
| empty space in egg carton |  |  |  |
| Prompt | OWLv2 | Qwen2.5-VL-7B-Instruct | GPT-4o |
| empty space in egg carton |  |  |  |
| Prompt | Original image | Agentic OD | Florence-2 |
|---|---|---|---|
| horizontal pencil (note this is a negative prompt, since there are only pens and no pencils. The correct answer is to return nothing) |  |  |  |
| Prompt | OWLv2 | Qwen2.5-VL-7B-Instruct | GPT-4o |
| horizontal pencil (note this is a negative prompt, since there are only pens and no pencils. The correct answer is to return nothing) | |  |  |
Future Work
Future work will entail improving the accuracy and latency of Agentic OD. In addition, we will do more detailed probing on the performance of Agentic OD on negative prompts – these are cases where the prompted image does not exist in the image (e.g. prompting “strawberry” on an image of blueberries). Models such as Florence-2 and OWLv2 are extremely biased towards outputting something (even if it is remotely close to the prompt), and LMMs still suffer from this to some degree as well. In everyday testing, Agentic OD does not seem to have this same problem, and responds appropriately to negative prompts.