TL;DR Healthcare teams process thousands of radiology reports every day, each packed with important diagnostic information in the form of images and text. When you can automate analyzing these documents reliably in real-time, it opens up possibilities for much faster...
TL;DR LandingAI’s latest Document Pre‑trained Transformer (DPT‑2) parses large, complex tables without hallucinations or misalignment. Complexities such as merged cells, multi‑level headers, and nested structures are handled by predicting the table’s layout and then...
TL;DR We ran on the DocVQA validation split and got 5,286 correct out of 5,331 (99.16%). Of those 45 wrong answers, only 18 are true parsing shortcomings. DocVQA is usually used to evaluate vision-language models, but we are pioneering the use of this popular dataset...
Agentic Document Extraction (ADE) pioneers a new paradigm shift by introducing a truly agentic document understanding system that is visual ai-first and built on data-centric practices. Accuracy, scale, speed, cost of ownership, and developer-friendliness for...
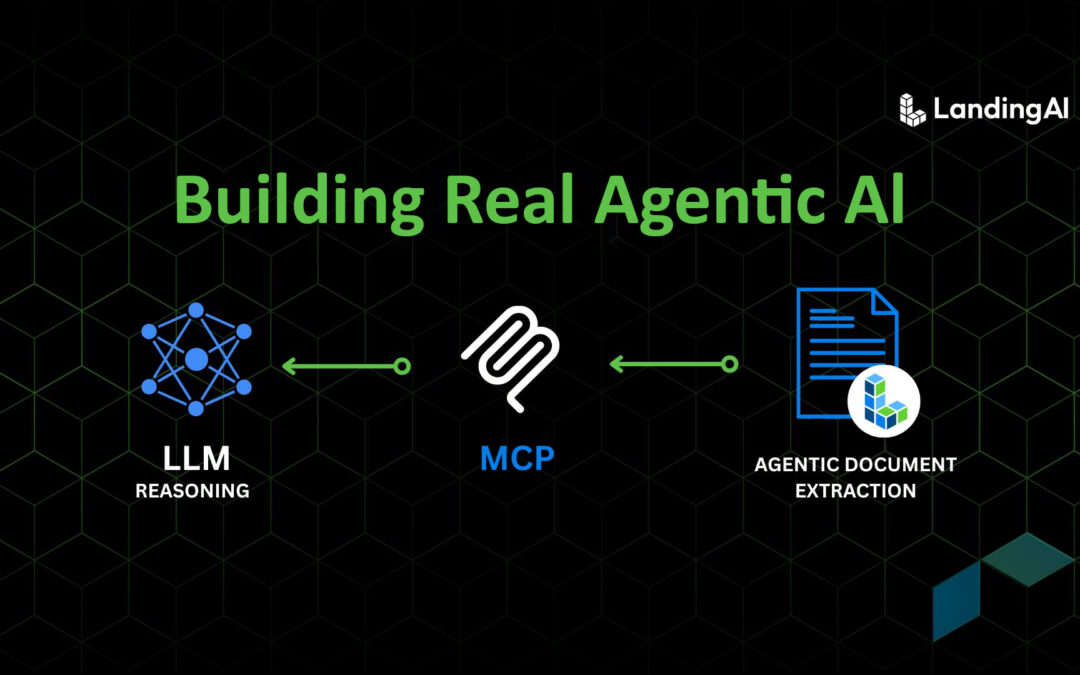
Reasoning models are good at thinking over text but documents aren’t just text. PDFs are visual artifacts—tables, columns, captions, footnotes—and flattening them erases structure and invites errors. This post shows how Model Context Protocol (MCP) lets an agent...