Billions of images and documents to be agentically understood, improving and speeding results PALO ALTO, September 30, 2025 — LandingAI, a pioneer in agentic vision AI technologies, today announced its significant upgraded version of Agentic Document Extraction...
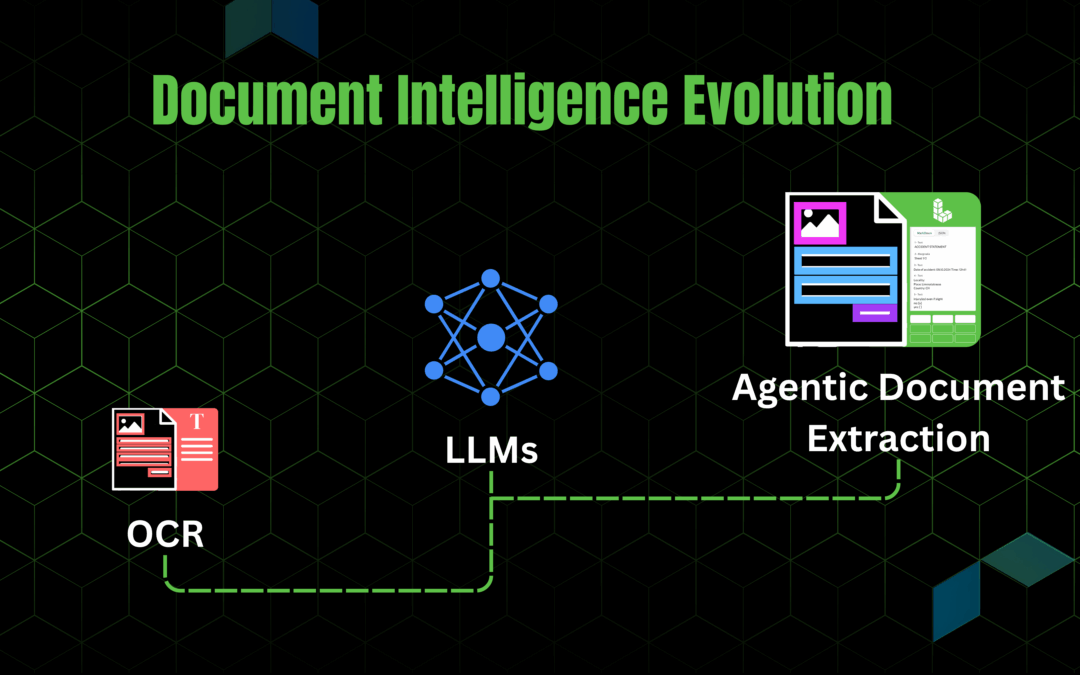
When we first launched Agentic Document Extraction (ADE), our focus was on breaking documents into agentic chunks: text, tables, figures. That was already a step forward from monolithic OCR, because it gave developers structured building blocks. But in the real world,...
Agentic Document Extraction (ADE) pioneers a new paradigm shift by introducing a truly agentic document understanding system that is visual ai-first and built on data-centric practices. Accuracy, scale, speed, cost of ownership, and developer-friendliness for...
Strategic investment secures ABB’s use of LandingAI’s vision AI capabilities, such as LandingLens™, for robot AI vision applications Pre-trained models, smart data workflows and no-code tools reduce training time by 80% and accelerate deployment in fast-moving sectors...
1. The Problem Ask an AI assistant to analyze a document, only to hear: “I can’t access external URLs or PDFs, please upload the file”? BTW, that dead-end isn’t random, it’s by design. LLMs run in a sandbox with no direct access to your filesystem or enterprise...