TL;DR Retail banking involves a wide range of document-heavy processes, including loan applications, credit card approvals, customer onboarding, and compliance checks. Traditional OCR and rule-based systems often fall short when processing these documents due to...
TL;DR LandingAI’s latest Document Pre‑trained Transformer (DPT‑2) parses large, complex tables without hallucinations or misalignment. Complexities such as merged cells, multi‑level headers, and nested structures are handled by predicting the table’s layout and then...
TL;DR We ran on the DocVQA validation split and got 5,286 correct out of 5,331 (99.16%). Of those 45 wrong answers, only 18 are true parsing shortcomings. DocVQA is usually used to evaluate vision-language models, but we are pioneering the use of this popular dataset...
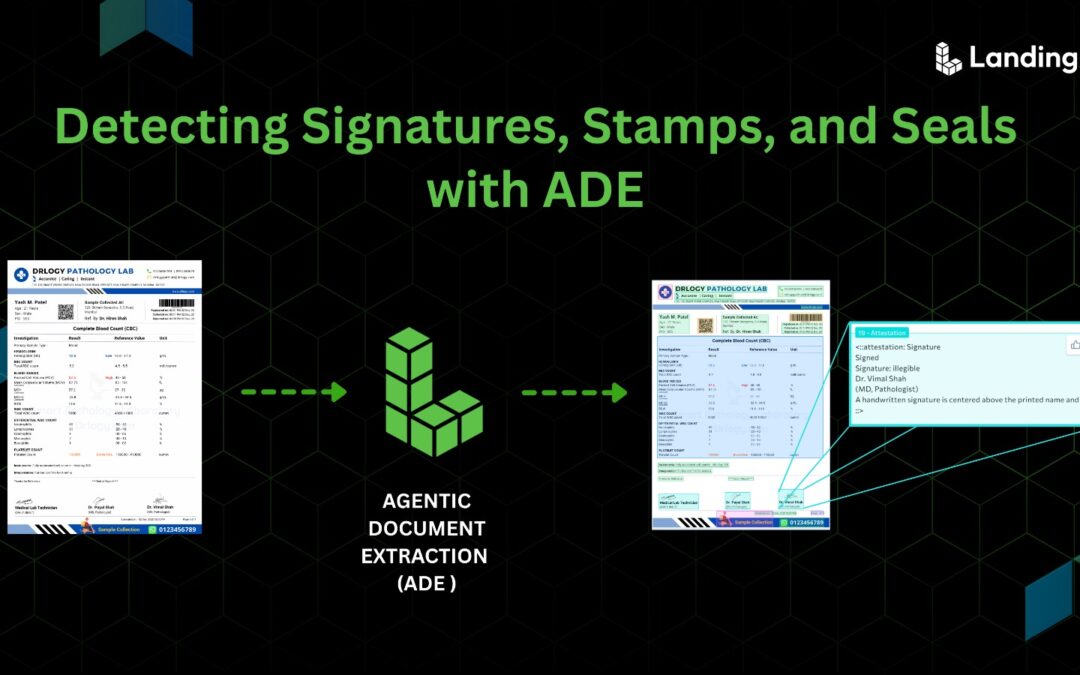
TL;DR Signatures, stamps, and seals are critical markers of authenticity in documents. Yet detecting these elements remains difficult because they vary widely in form, placement, and quality. Traditional OCR and template-based systems often fail to capture them...
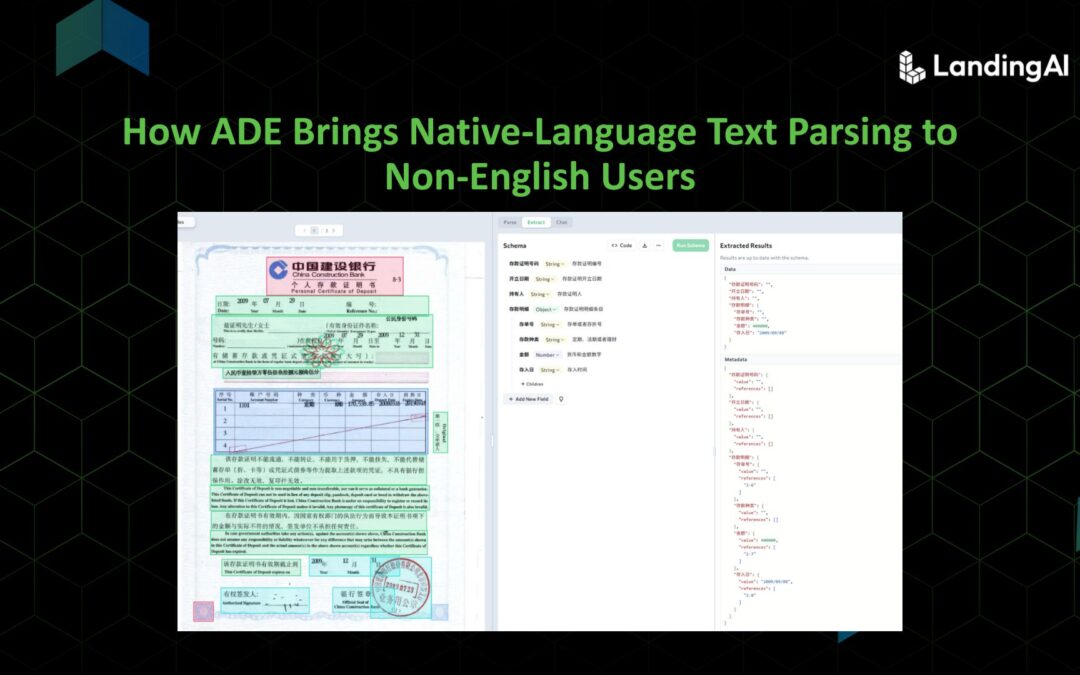
In the era of large language models, a silent barrier has emerged for non-English speakers. Despite the revolutionary capabilities of modern AI, there’s an uncomfortable truth: most mainstream models are trained predominantly on English corpora, creating an...