
TL;DR
Enterprise RAG pipelines process long documents like 10-Ks, legal contracts, and technical manuals by slicing them using standard chunking strategies that strip away the underlying structure. A chunk reading "Revenue is down 10%" lands in the index with zero signal of whether it came from Risk Factors or Global Operations, forcing downstream models to synthesize answers from isolated fragments. Accurate retrieval needs an intact document hierarchy. The ADE Section API evaluates the parsed document and returns a hierarchical table of contents (TOC), so each chunk carries its context into the index. Retrieval pipelines become section-aware, and agents can navigate the document using its real structural map.
The Challenge: The Shredder Effect
Standard RAG (Retrieval-Augmented Generation) pipelines process massive documents by slicing them into small, digestible "chunks." It’s like taking a highly structured document and running it through a paper shredder. While the LLMs can now read the individual fragments easier, the shredding process destroys the very thing that gives the data its actual meaning: its structural context.
Here is what that looks like in practice. NVIDIA's Fiscal 2026 10-K runs around 100 pages. “Item 1A. Risk Factors” details U.S. government export restrictions on high-end GPUs. However, the quantitative picture—Data Center segment revenue and its geographic breakdown—lives elsewhere in Item 7 and Item 8.
An analyst asks a retrieval system, "What is the Data Center revenue exposure if export controls tighten?" The analyst needs both sides of the answer. Neither section answers the question on its own. The LLM can only produce a faithful response if retrieval hands it both sections, with the context that links them preserved.
The Solution: Context-Aware Retrieval
To build reliable retrieval systems, we need to preserve the anatomy of the original document. Every chunk should be labelled with its parent chapter and section. This ensures every chunk carries its own structural "GPS coordinate" mapping it back to its exact context.
The ADE Section API acts as the intelligent mapper that links structural lineage directly into the vector embeddings. Here is how the context-aware RAG pipeline looks like with ADE Parse API:
- Parse: The ADE Parse API turns the messy PDF into chunks of Markdown. Crucially, every chunk is assigned a unique anchor ID (chunk.id).
- Structural Mapping: The ADE Section API scans the Markdown and builds a structured Table of Contents (TOC). It links the semantic hierarchy to the exact chunk.id where that section begins.
- Chunk Lineage: The pipeline walks through the chunks, using the TOC to figure out the exact "ancestor path" of every piece of text.
- Context Injection: Right before embedding, the pipeline physically prepends the breadcrumb path to the text chunk and saves it as metadata.
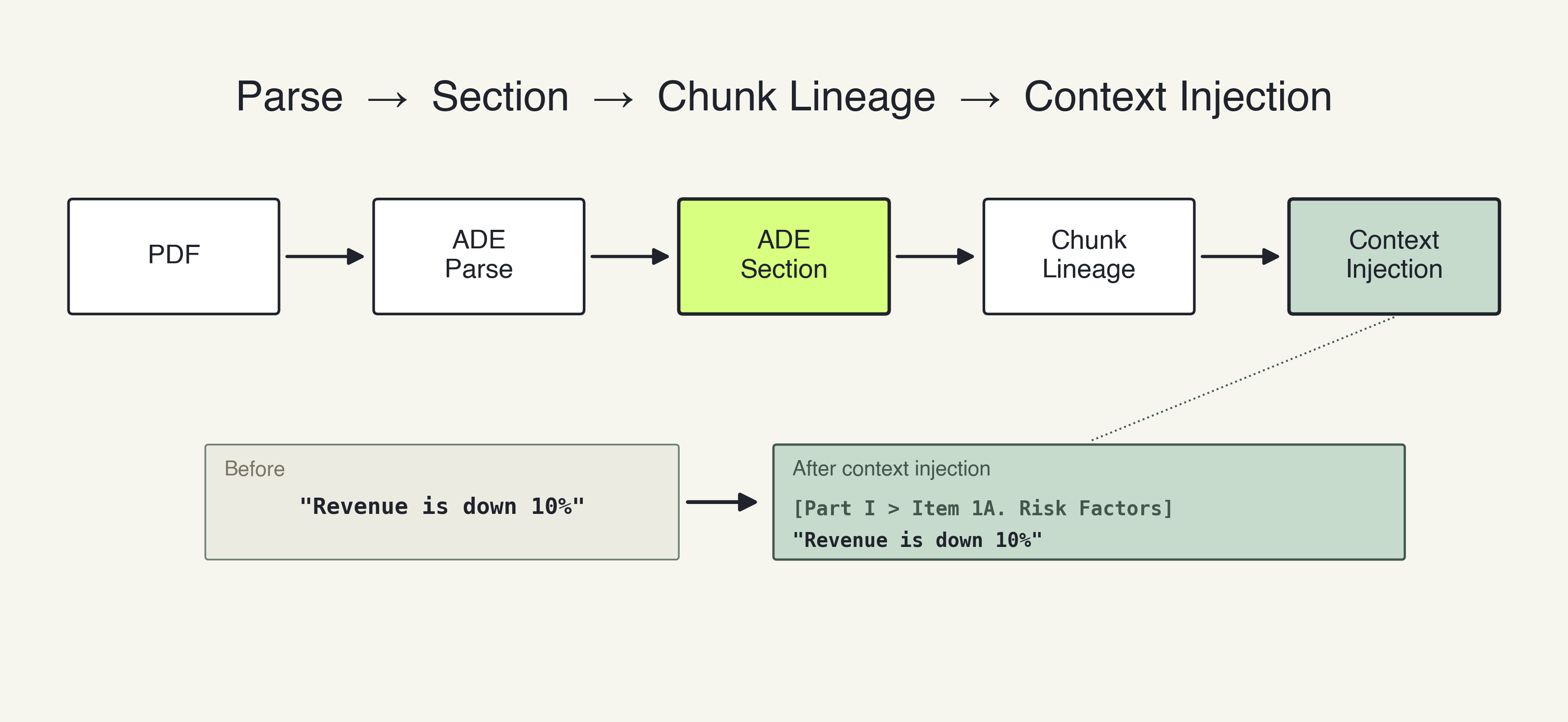
A raw string that previously just said "Revenue is down 10%" is transformed into: [Part I > Item 1A. Risk Factors] Revenue is down 10%.By the time the text reaches the database, the section title is baked directly into the vector, ensuring the document's structure is permanently attached to the data.
The 3 Core Capabilities of Section Hierarchy
Injecting hierarchical awareness directly into the pipeline enables three advanced retrieval behaviors that flat chunk indexes simply cannot support.
1. Hierarchical Query Routing
Enterprise queries vary wildly in scope.
- Broad Queries: If a user asks, "Tell me about Acme's risk factors," the system can route directly to the top-level section and retrieve the H1 chunk or a generated summary of that specific section.
- Specific Queries: If the user asks, "What does Acme say about interest rate risk?" the system routes to the granular sub-chunks nested within that section.
Without section detection, both queries compete for the exact same flat pool of chunks, resulting in noisy, diluted context windows.
2. Precision Section Filtering
Because the ancestor path is saved as metadata, applications can proactively scope their retrieval to highly specific parts of a document.
A legal analyst searching for indemnification clauses does not need the retrieval engine evaluating marketing copy or table indices. By using the metadata, the vector search can be strictly filtered to only evaluate chunks located within sections tagged "Terms and Conditions." This targeted approach dramatically reduces noise, minimizes token consumption, and improves overall retrieval precision.
3. Context-Aware Generation and Citations
When a chunk is retrieved and passed to LLM for generation, the full breadcrumb path tells the model exactly where in the document this information lives. The LLM knows the section, the parent section, and the page. This spatial context is the key to forcing LLMs to generate accurate citations, scope answers appropriately, and avoid conflating data from conflicting chapters of a report.
Shaping the Hierarchy with Guidelines
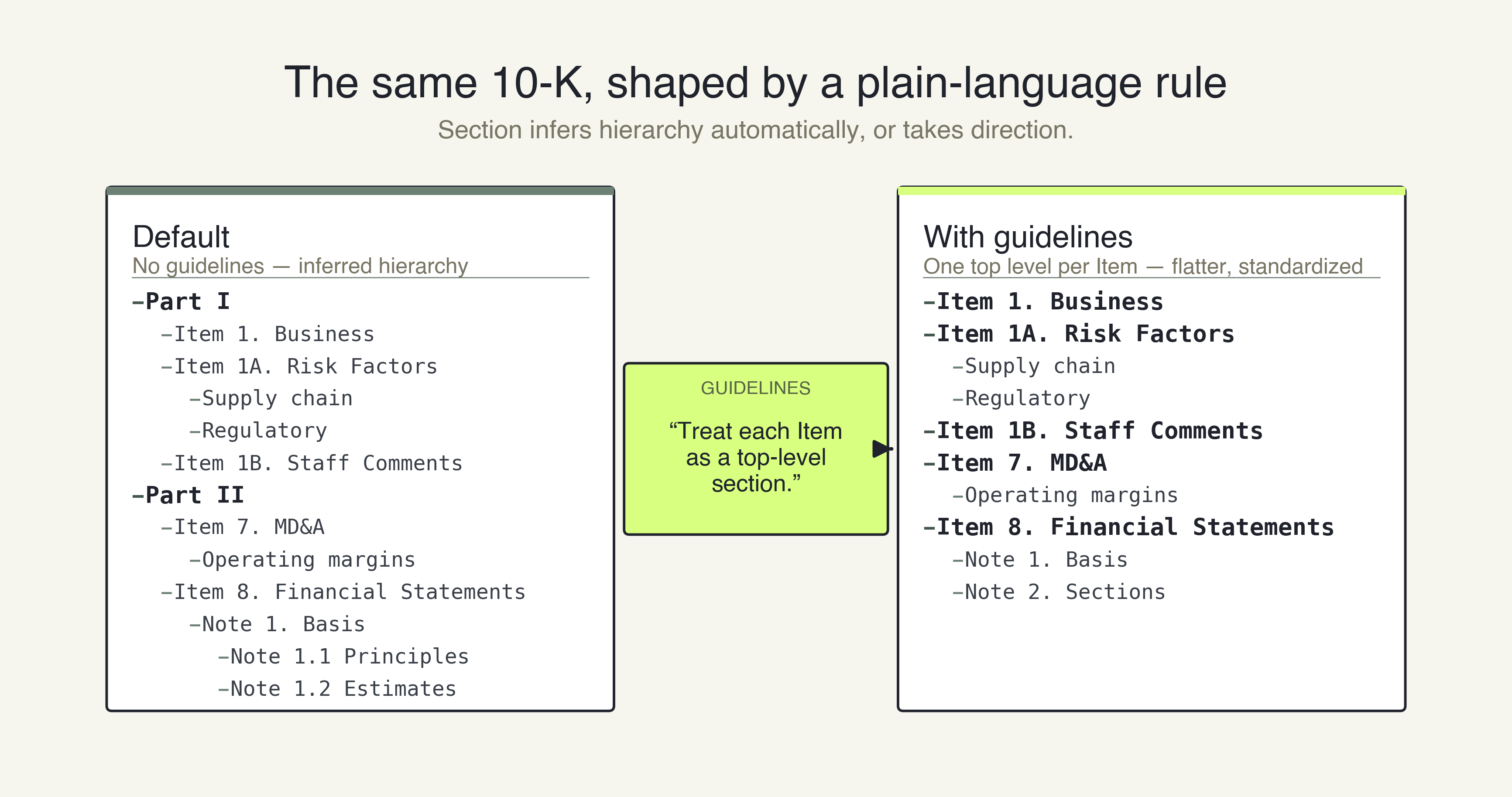
By default, the ADE Section API infers the structure. When you need the structure to follow a specific convention, you pass guidelines as a prompt in your API call.
curl -X POST 'https://api.va.landing.ai/v1/ade/section' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-F 'markdown=@parsed_10k.md' \
-F 'guidelines=Treat each Item as a top-level section.'For financial filings, you might pass:
- "Treat each Item as a top-level section."
- "Keep each consolidated financial statement as one section, tables intact."
- "Flatten notes to financial statements to two levels."
How to start
Run ADE Parse, then run ADE Section. Inspect the TOC it generates. If the hierarchy does not match how a human analyst would outline the file, add a guideline prompt. Once the structure aligns, feed those section paths into your vector database to evaluate the impact on your retrieval accuracy.
- Try out your document on va.landing.ai for quick validation and testing.
- Try the API: Process a long document and inspect the TOC it produces.
Read the Documentation: Full reference for the ADE Section API.