
TL;DR
- Hierarchical Parsing. DPT-3 returns a document hierarchy: pages → elements → table cells → visual lines.
- Three representations. The new
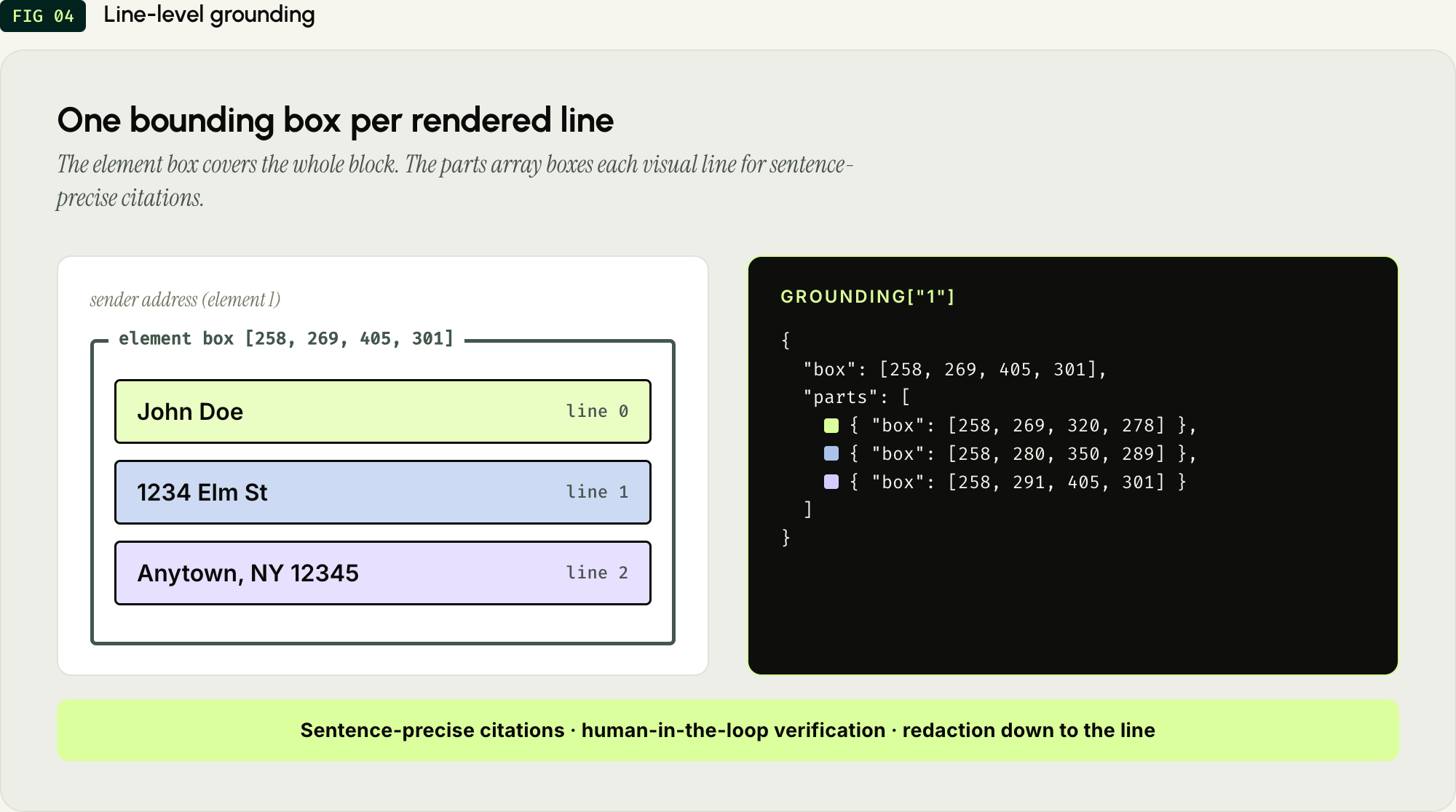
/v2/ade/parseAPI response separates cleanmarkdown, a logicalstructuretree, and a spatialgroundingmap. - Line-Level Grounding. Text elements include one bounding box per rendered line, enabling sentence-precise citations and human-in-the-loop verification.
- Tighter markdown output. Reduced token usage and configurable output format(HTML or Markdown tables, optional figure captions) directly improves downstream LLM performance.
- Cheaper Mixed Workloads. Faster and less expensive than our previous Parse models for most customers running mixed workloads.
You asked for this. So we built it.
DPT-3 is a new document-parsing architecture, paired with a new endpoint (/v2/ade/parse) and a fundamentally different way of representing what's inside a document. Users can select exactly the representation their pipeline needs: markdown for LLM context, the structure tree for routing and chunking, and/or the grounding map for visual verification.
This post covers the document model, the response shape, and the configuration options. There is new pricing too which makes this model less expensive for most customers.
A New Document Model
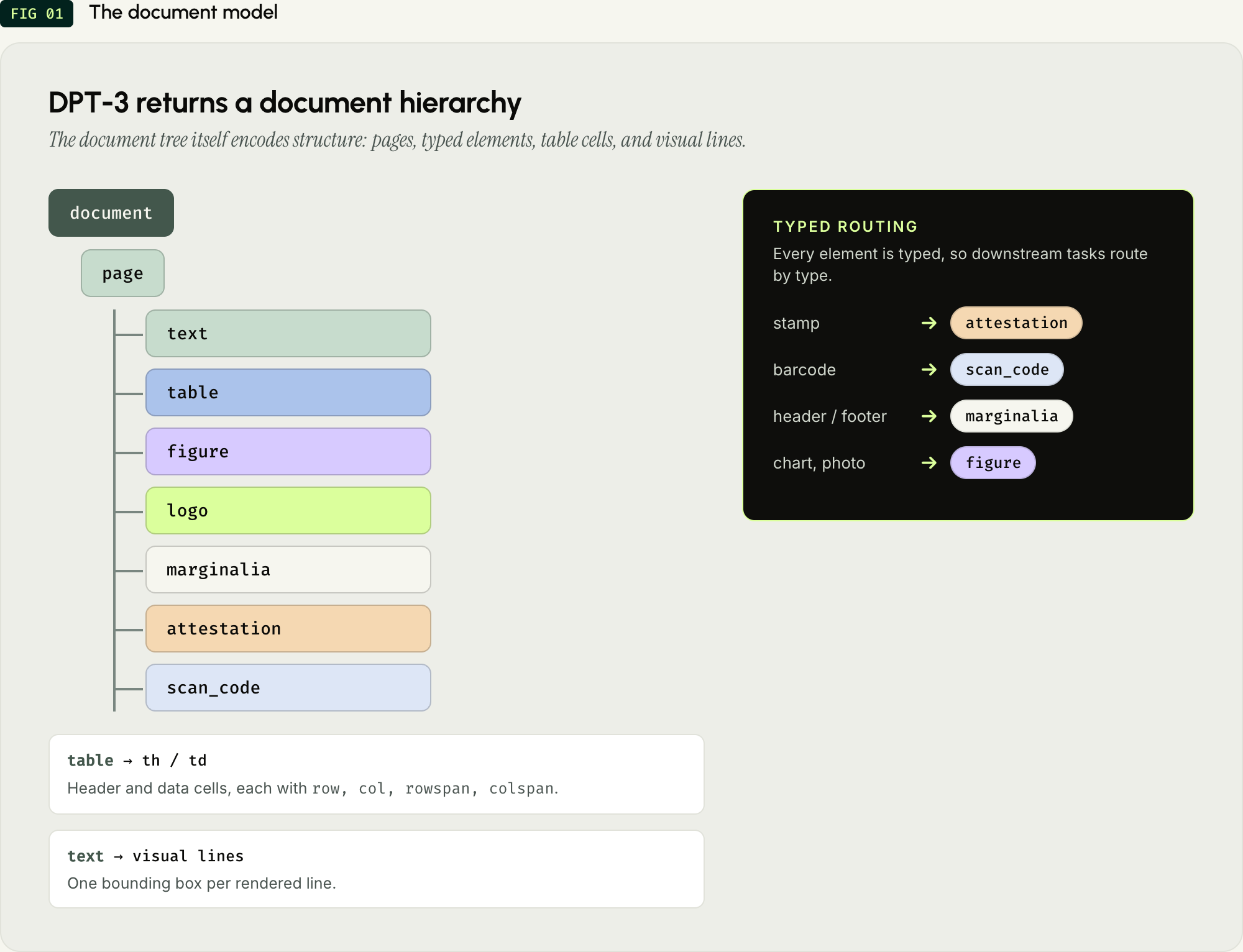
DPT-3 reads a document and builds a document hierarchy. The root is the document. Pages hang off the root. Most elements (text, figure, logo, etc.) are leaves .This new document model enables:
Parent–child relationships. The document tree itself encodes the document’s structure.
Typed routing. Stamps surface as
attestation, barcodes asscan_code, page headers and footers asmarginalia. This enables simple routing by type for downstream tasks.Preserved table structure. A table node contains explicit
td(data cell) andth(header cell) children, each withrow,col, as well asrowspanandcolspanfor merged cells.Captioned non-text elements. Non-text elements include a transcription (any embedded text, like axis labels) and an LLM-ready description. This unlocks Indexing in RAG without a separate vision pass.
First-class math. Block equations render as
$$...$$, inline equations as$...$.
A New API
The new /v2/ade/parse returns four top-level fields. Three of them carry the document content; the fourth (metadata) carries bookkeeping. The four top-level fields are:
- markdown: A single, clean CommonMark string, ready for a chunker or LLM context window.
- structure: The document tree. Each node has a
type, a string id, and aspan [start, end)representing exact Unicode character offsets into the markdown string. - grounding: A flat object keyed by the element
id(as a string). Each value is an Element Grounding object structured with two levels: a high-level elementboxand a fine-grainedpartsarray for line-by-line coordinates. - metadata:The operational details of the run, including model version, processing duration, exact character counts and credit usage.

Why this structure?
The structure/grounding split is intentional. Most downstream consumers — chunkers, retrievers, LLM prompts — operate on the markdown and the structure alone and do not require pixel coordinates. The grounding map is loaded only when an audit view, a redaction step, or a visual citation must be produced. This keeps payloads small for the common path and exact for the geometry path.
An Example
To see this in practice, we sent a scanned envelope to the new API endpoint. Here is exactly how the response breaks down the addresses and visual elements across the three representations.
The Markdown The document contains the sender's address, a postage stamp, and the recipient's address. The parser natively identifies the stamp as a logo and emits it as a markdown image with the description as alt text, followed by any text rendered inside the stamp on the next line.
The Structure The structure field builds the logical tree. This envelope is one page containing three distinct elements. Notice that there are no coordinates here—only structural logic and character spans.
The Grounding The spatial data lives in the grounding object. It maps the element IDs from the structure directly to their bounding boxes on the page. Let's look at the sender's address (Element "1").
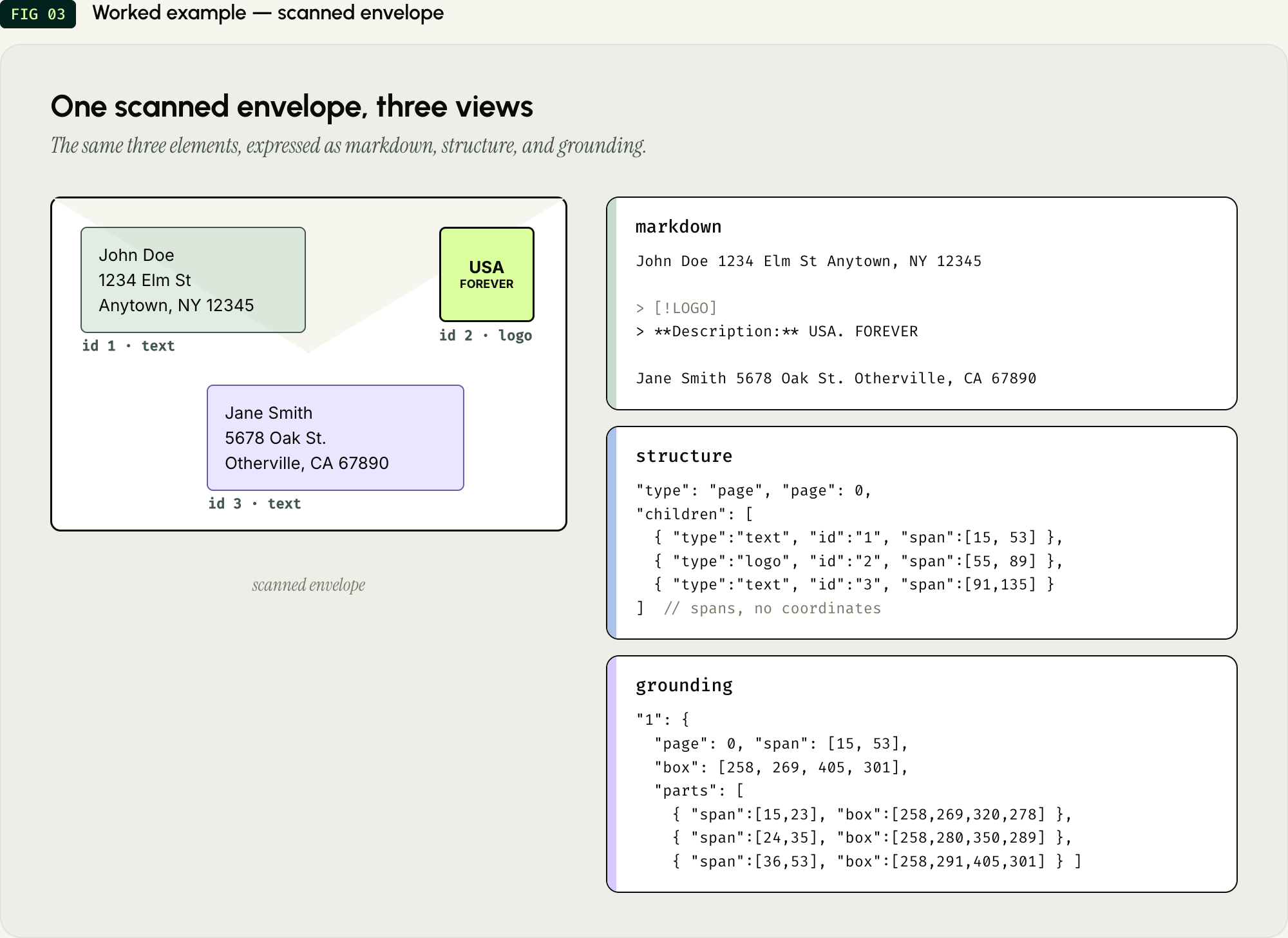
Notice how the parts array breaks the address block down. The element has an overall box [258, 269, 405, 301] covering the entire address, but the parts array provides a separate bounding box for each visual line (name, street, city/zip).
Configurability via Options
You can pass an options JSON to control what comes back:
- pages: Pass a 0-indexed array (e.g., [0, 1]) to parse specific pages.
- elements.<type>.caption: Set to false to drop figure descriptions text to save LLM context tokens. For example, with options.elements.figure.caption=false, the figure blocks are reduced to just > [!FIGURE].
- elements.table.format: Switch from "markdown" to "html" if your downstream system requires strict cell-merging tags
- grounding.parts — Set to false when you only need element-level grounding.
Example — process only page 0, use HTML table format, omit grounding parts:
{
"pages": [0],
"elements": { "table": { "format": "html" } },
"grounding": { "parts": false }
}Complexity-Aware Pricing
Treating every page of a document equally is a waste of compute. A near-blank cover sheet should not cost the same as a dense financial table. To solve this, DPT-3 introduces Complexity-Aware Pricing. Users pay for the content returned, not for the paper sent.

The credit cost per page now scales directly with the volume of markdown returned. For typical mixed workloads, this drops average per-page cost by 25–40%. See pricing for full details.
Getting Started
- Test it instantly: Try out your document on the playground for quick validation and testing.
- Read the Documentation: Full reference for the new Parse API.