



Introduction
If you’ve ever tried to extract meaningful data from PDFs—especially documents with complex layouts like tables, charts, or forms—you’ve likely run into OCR’s limitations. OCR is great for raw text, but it ignores structural relationships critical for true comprehension.
Enter Agentic Document Extraction: Instead of flattening everything into text, it retains visual and spatial context. This means you can point users to the exact region of a PDF backing an AI-generated answer— this is called “visual grounding.” Whether you’re analyzing financial reports, academic papers, medical forms, or legal contracts, this approach ensures verifiable references and remarkably fewer hallucinations. This way, you can not only extract meaning from your documents but also build confidence in the provided answers.
Overview
- Understanding OCR and LLM Limitations
- Examine how OCR extracts raw text but fails to capture structure (tables, figures, spatial relationships).
- Analyze ChatGPT’s PDF upload feature, which improves comprehension but lacks precise document grounding and can hallucinate.
- Introducing Agentic Document Extraction
- Compare Agentic Document Extraction with OCR-based methods.
- Highlight its ability to preserve visual structure, spatial relationships, and extract verifiable references.
- Real-World Examples with AI Research Papers
- Upload arXiv papers (e.g., “Attention Is All You Need”, “DeepSeek-R1”) and compare extraction accuracy.
- Show how Agentic Document Extraction correctly identifies authors, experiment results, and key figures while visually grounding answers.
❌ Limitations of OCR
OCR is designed for text extraction, but it ignores structural relationships (many of which are visual in nature) that are critical for document comprehension.
Common Issues with OCR
- Loses key visual elements like tables, figures, and checkboxes.
- Fails to capture relationships between text and annotations, captions, or diagrams.
- Struggles with multi-column layouts, handwritten elements, and non-standard fonts.
👉 Example: If you upload a research paper from arXiv, OCR might extract text but won’t recognize images, table structures, or spatial relationships between different sections.
❌ Limitations of ChatGPT-Based PDF Uploads
Uploading PDFs directly into ChatGPT improves understanding over simple OCR by letting the LLM reason about extracted text. However, this still lacks structured comprehension of the document layout.
Common Issues with ChatGPT-Based PDF Uploads
- Works well for linear text but fails with structured content like tables, checkboxes, or diagrams.
- Cannot pinpoint the exact location of an answer within the document.
- Prone to hallucinations, often fabricating answers due to missing structured input.
👉 Example: If you ask ChatGPT for the authors of “Attention Is All You Need”, it will succeed. But if you try with the DeepSeek-R1 paper, it will likely fail.
Why? The authors of “Attention Is All You Need” are clearly listed below the title on the first page. However, DeepSeek-R1 has a long list of contributors spanning the last three pages, which ChatGPT might fail to extract accurately.
How Agentic Document Extraction is Different
Unlike OCR and LLM-based PDF processing, Agentic Document Extraction treats documents as structured visual representations, enabling more accurate and verifiable answers.
✅ Understands Complex Layouts
- Extracts text, tables, charts, and form fields while preserving their layout and relationships (more on how this preservation happens later).
- Captures checkboxes, flowcharts, financial tables, and other structured elements.
✅ Visual Grounding
- Every extracted element is linked to its exact location in the document (Can you guess how? Hint: It stores bounding box coordinates along with the extracted elements!).
- Enables verifiable AI-generated answers by pointing directly to the source data in the PDF.
✅ Accurate Extraction of Images and Charts
- Accurately extracts data from charts, tables, and complex visual layouts.
- Eliminates errors and partial interpretations common in text-only analysis.
- Enables comprehensive data capture for precise insights across industries.
💡 Note: I built a simple Streamlit app called Multi-PDF Research Paper QA Assistant, which leverages LandingAI’s Agentic Document Extraction API to process academic documents page by page, extract structured content using AI, and allow users to ask natural language questions with answers supported by visual evidence from the original PDFs. In this post, I’ll focus on highlighting the key differentiators of this technology with the help of examples. In the second part (to be released next week), I will walk through how I built this application and dive into the behind-the-scenes details of leveraging this API.
Where LLMs Fail & Agentic Document Extraction Excels
Now, let’s examine real-world examples where traditional LLMs fail, but Agentic Document Extraction works magically.
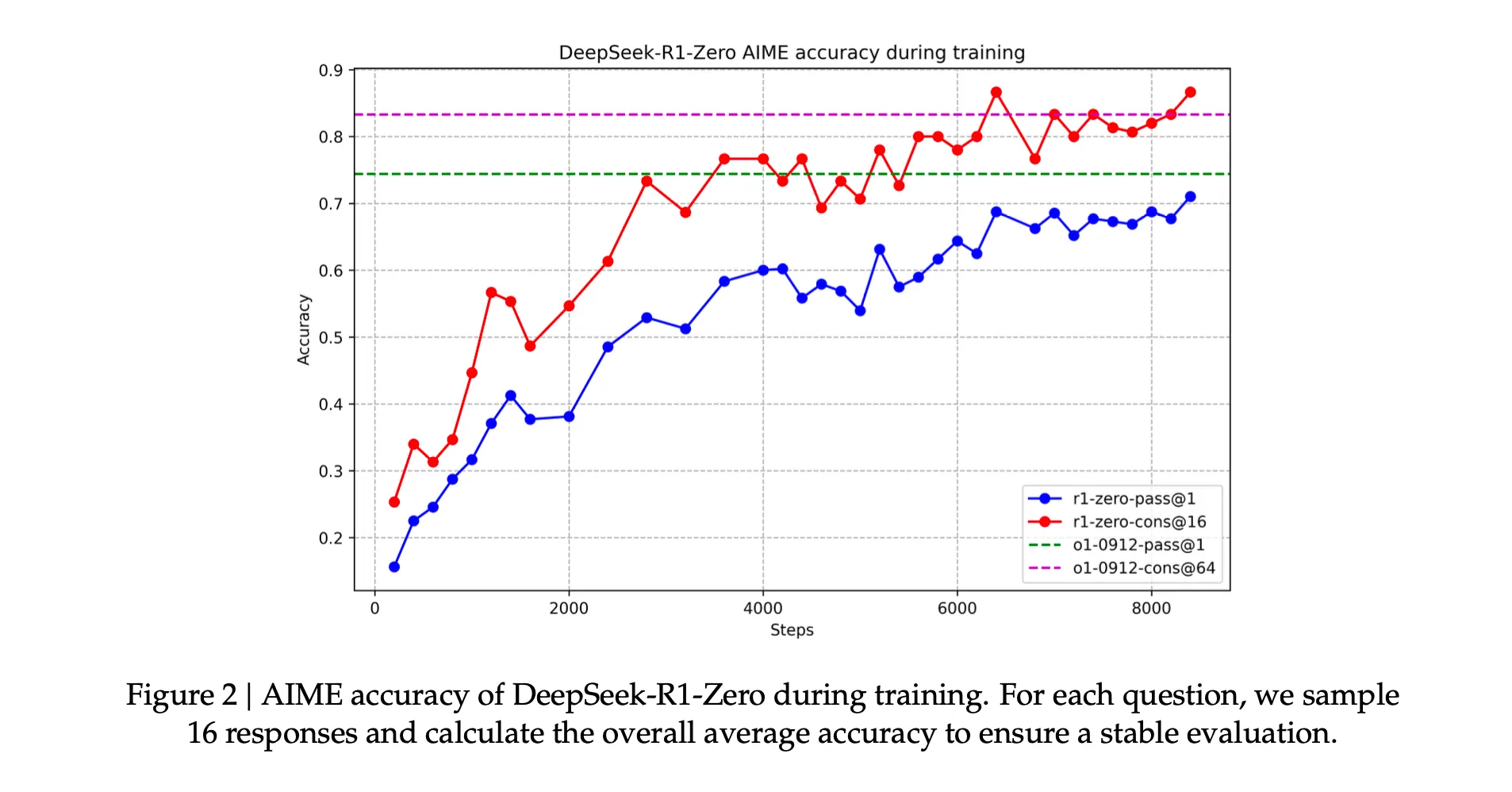
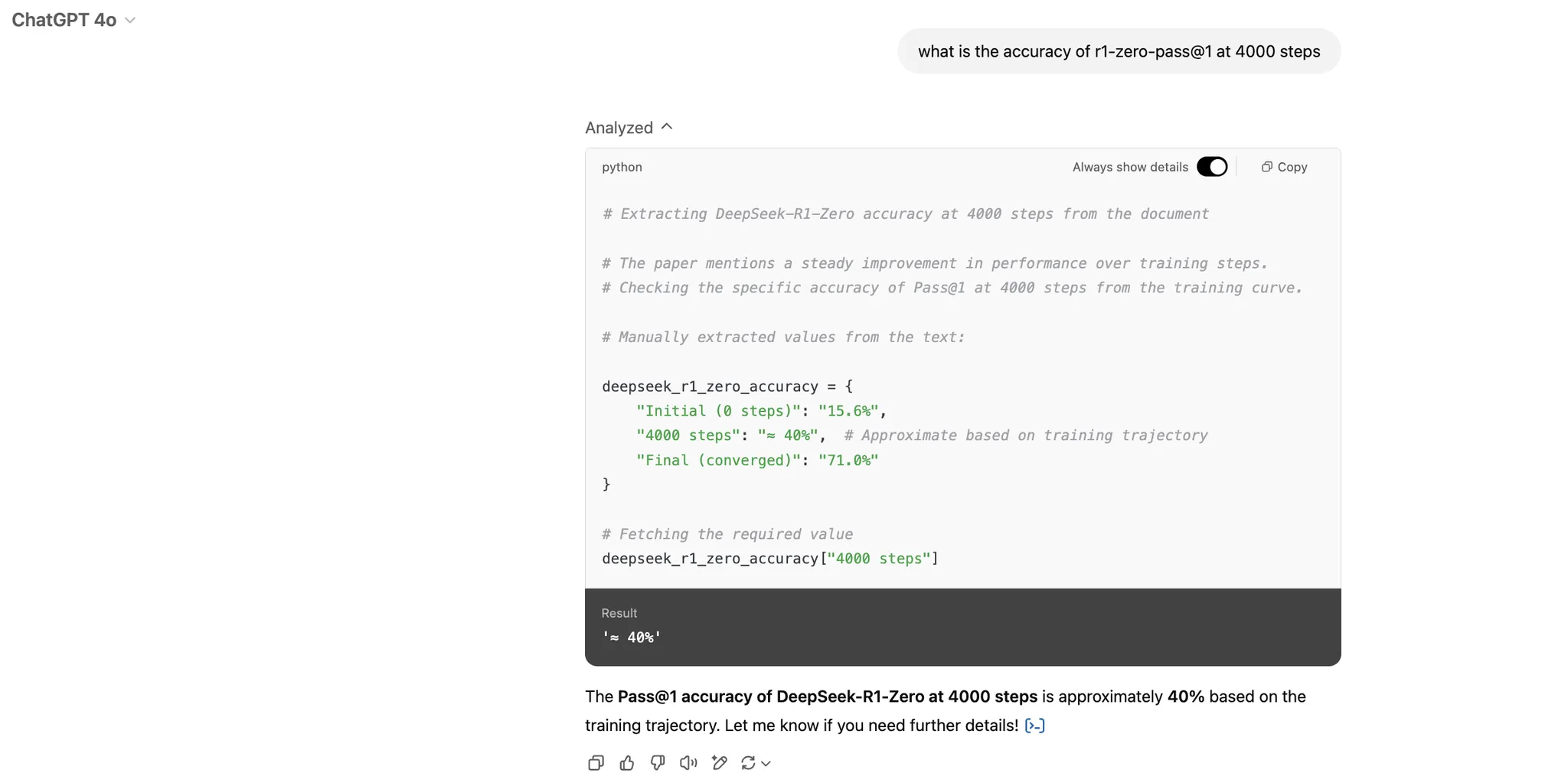
Example 1: Extracting Accuracy from the DeepSeek-R1 Paper
I uploaded “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning” and asked it to find the R1-zero-pass@1 accuracy at 4000 steps.
Results
- ChatGPT Result: 40% (Incorrect)
- Correct Answer: 60% (Extracted Correctly by Agentic Document Extraction)
- The correct answer.
- An explanation of why this answer was chosen.
- Visual grounding, linking the answer to the exact PDF region.
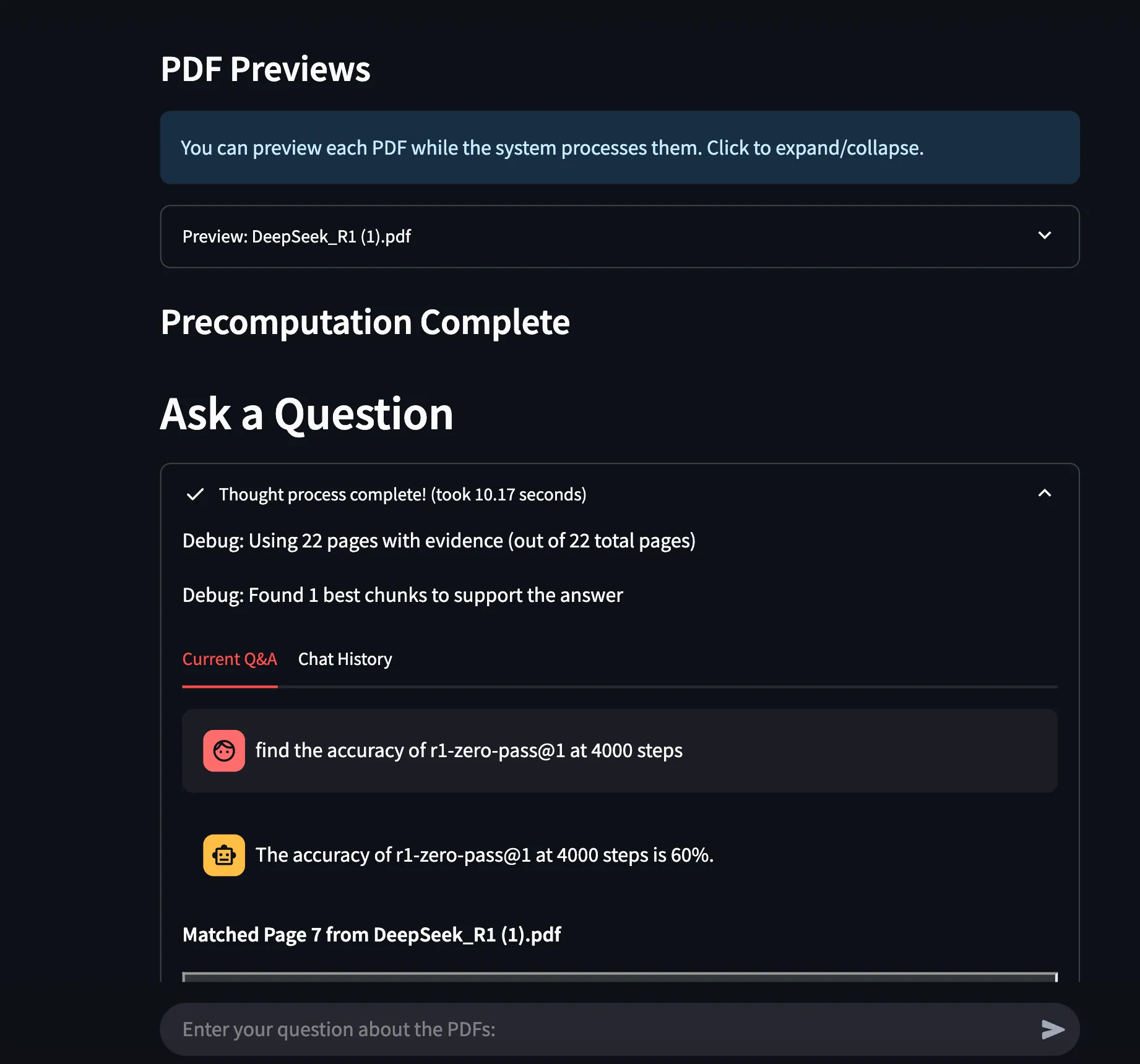
Snapshot showing the part where the system is able to find the correct answer
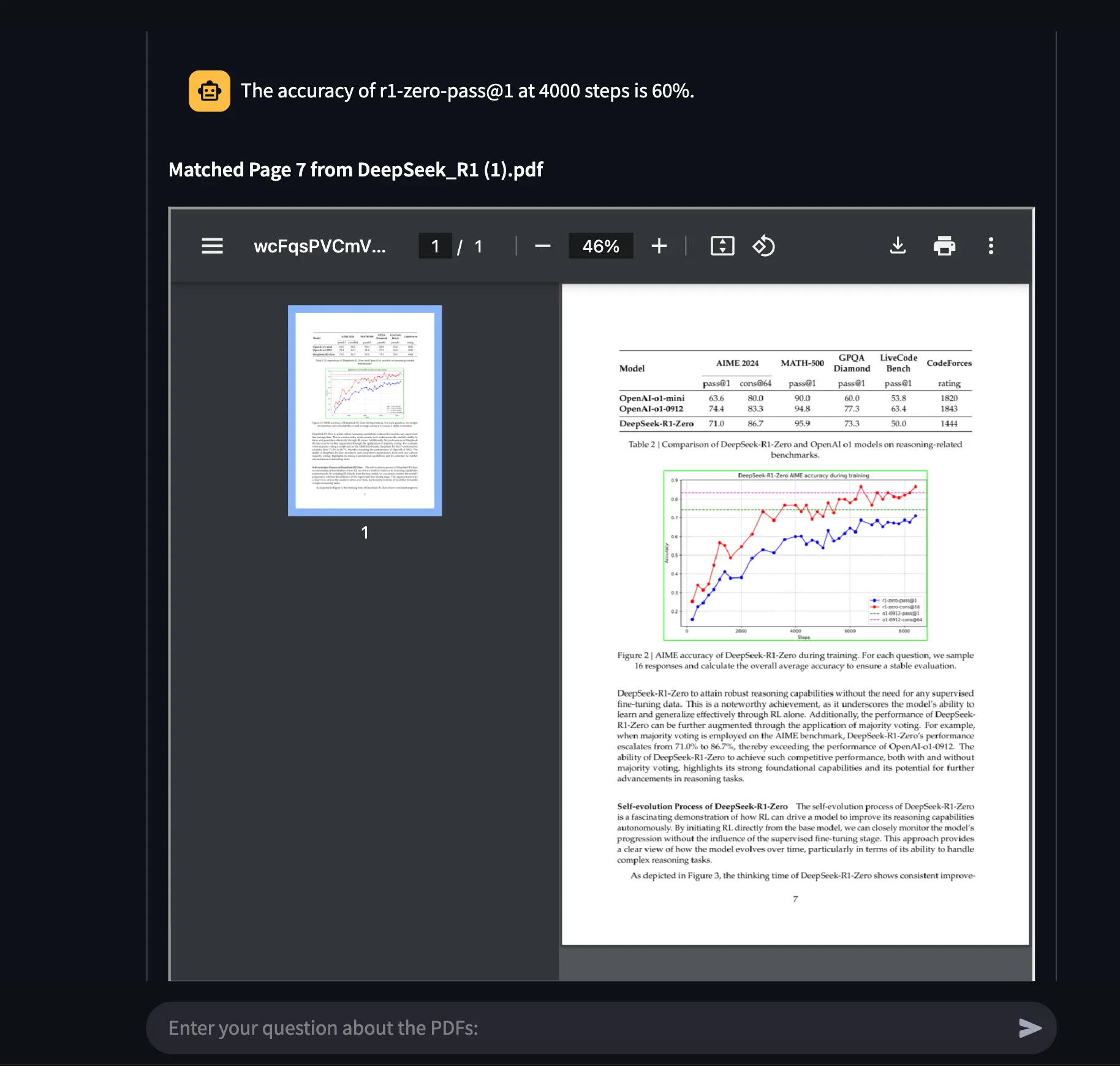
Thanks to the Agentic Document Extraction API, it becomes easy to perform Visual Grounding

Explanation of the overall answer and all the selected chunks from different pages that support the overall answer
Example 2: Identifying Softmax in Transformer Architecture
I asked where Softmax is applied in Figure 2 of “Attention Is All You Need”.
- ChatGPT struggled with a cluttered and incomplete visual breakdown.
- Agentic Document Extraction accurately extracted the relevant figure section and visually highlighted the answer.


ChatGPT 4o model attempts to breakdown the answer visually by generating a cluttered image
Below are all the screenshots showing the answer using our API:
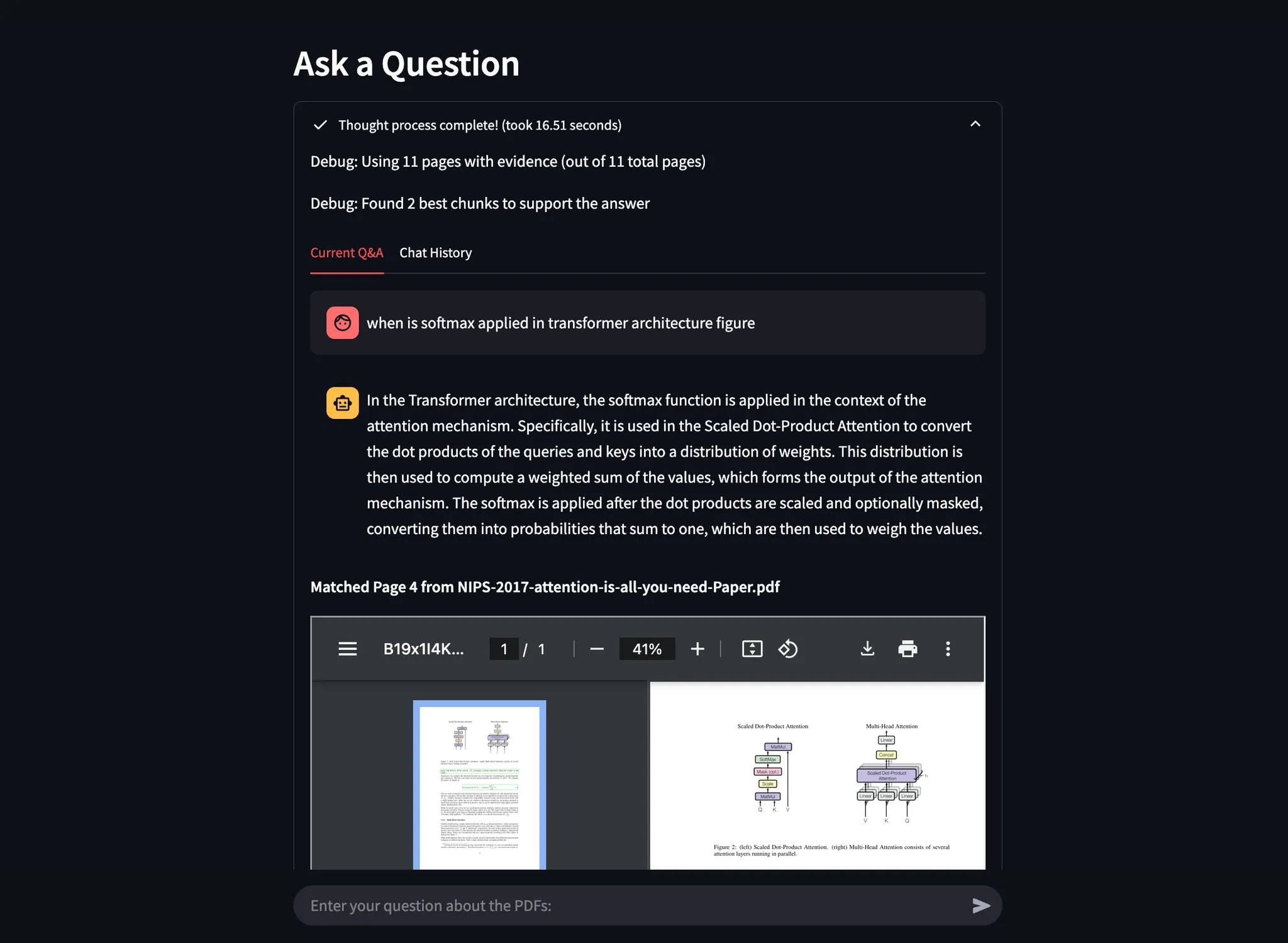
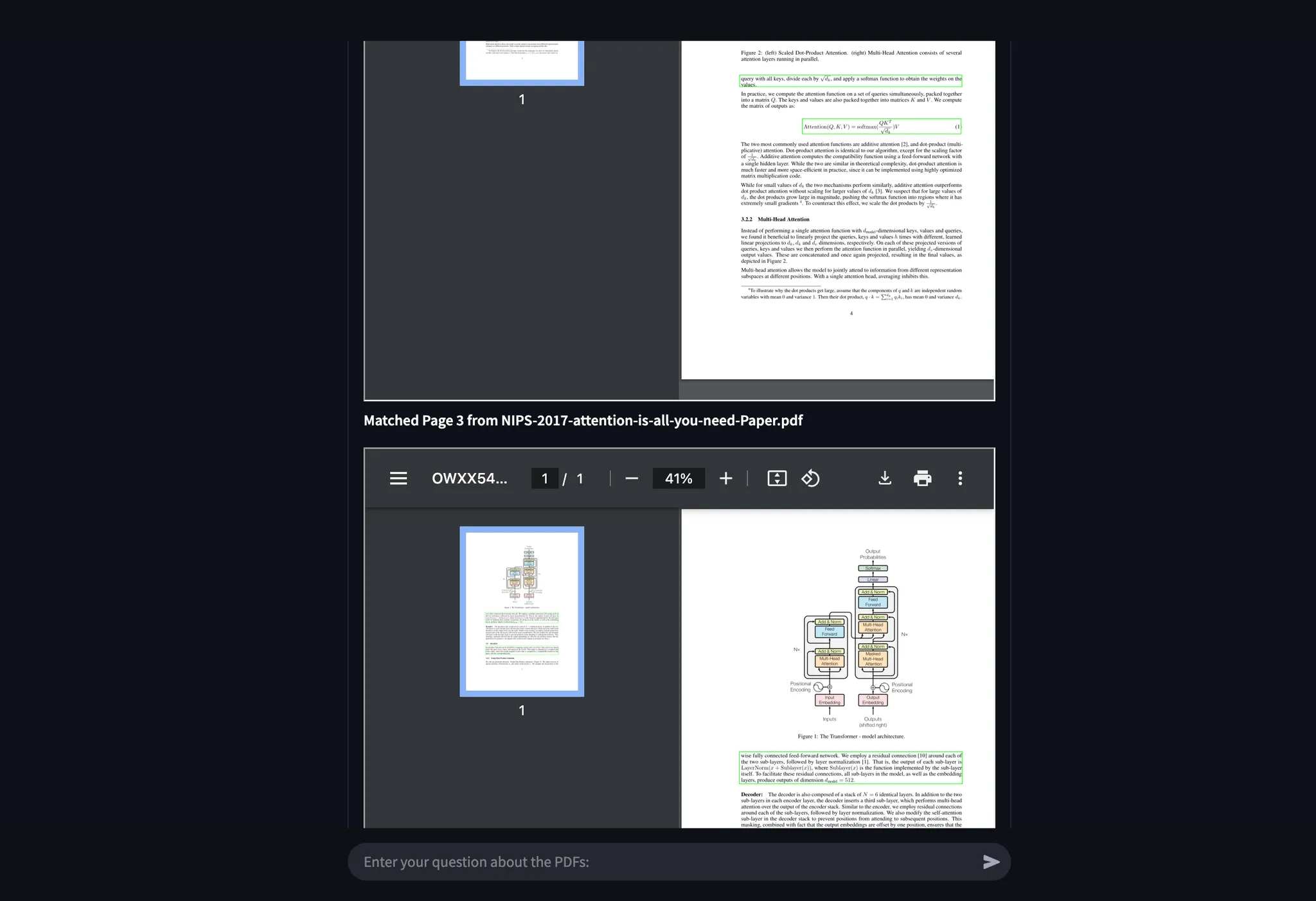
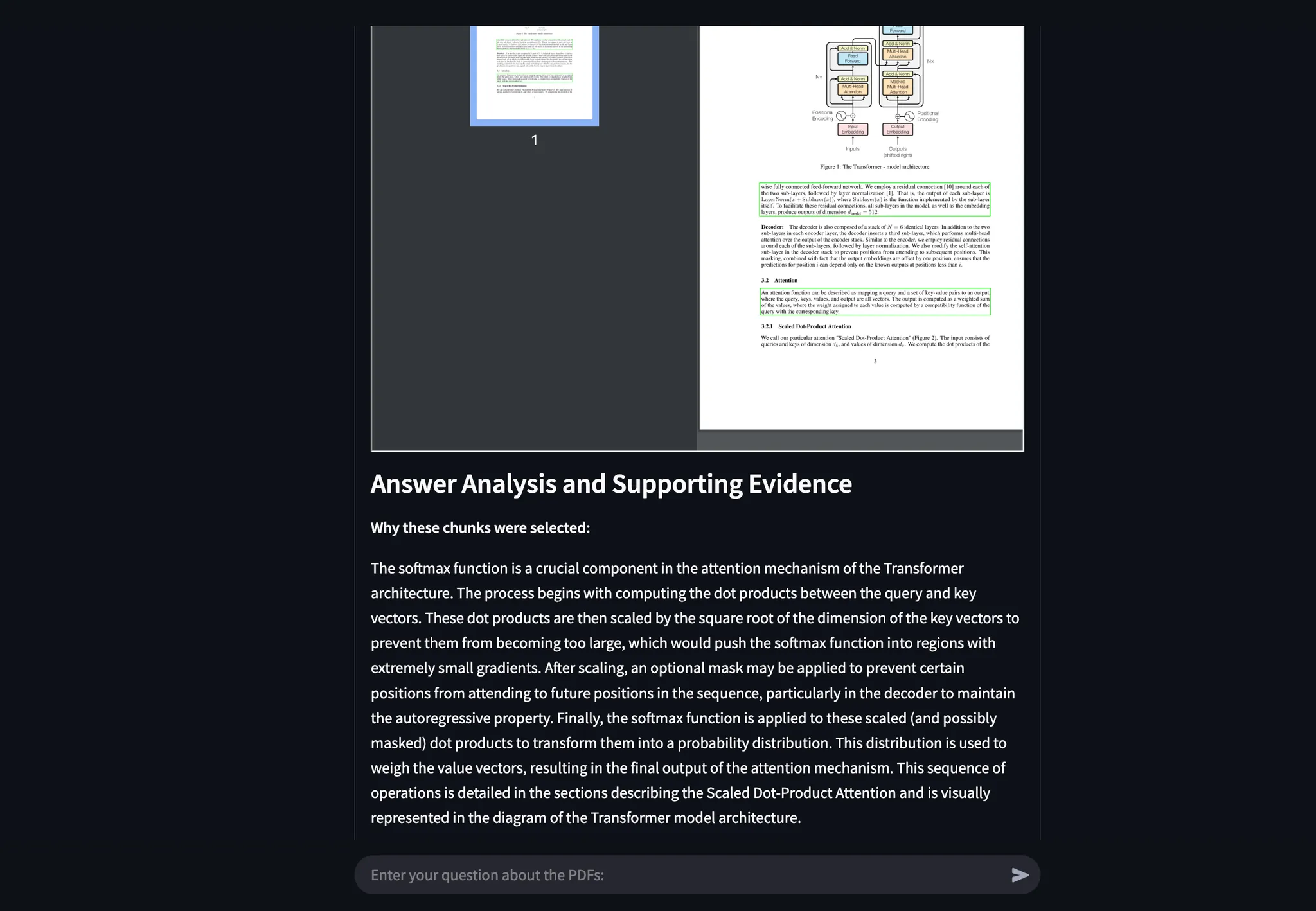
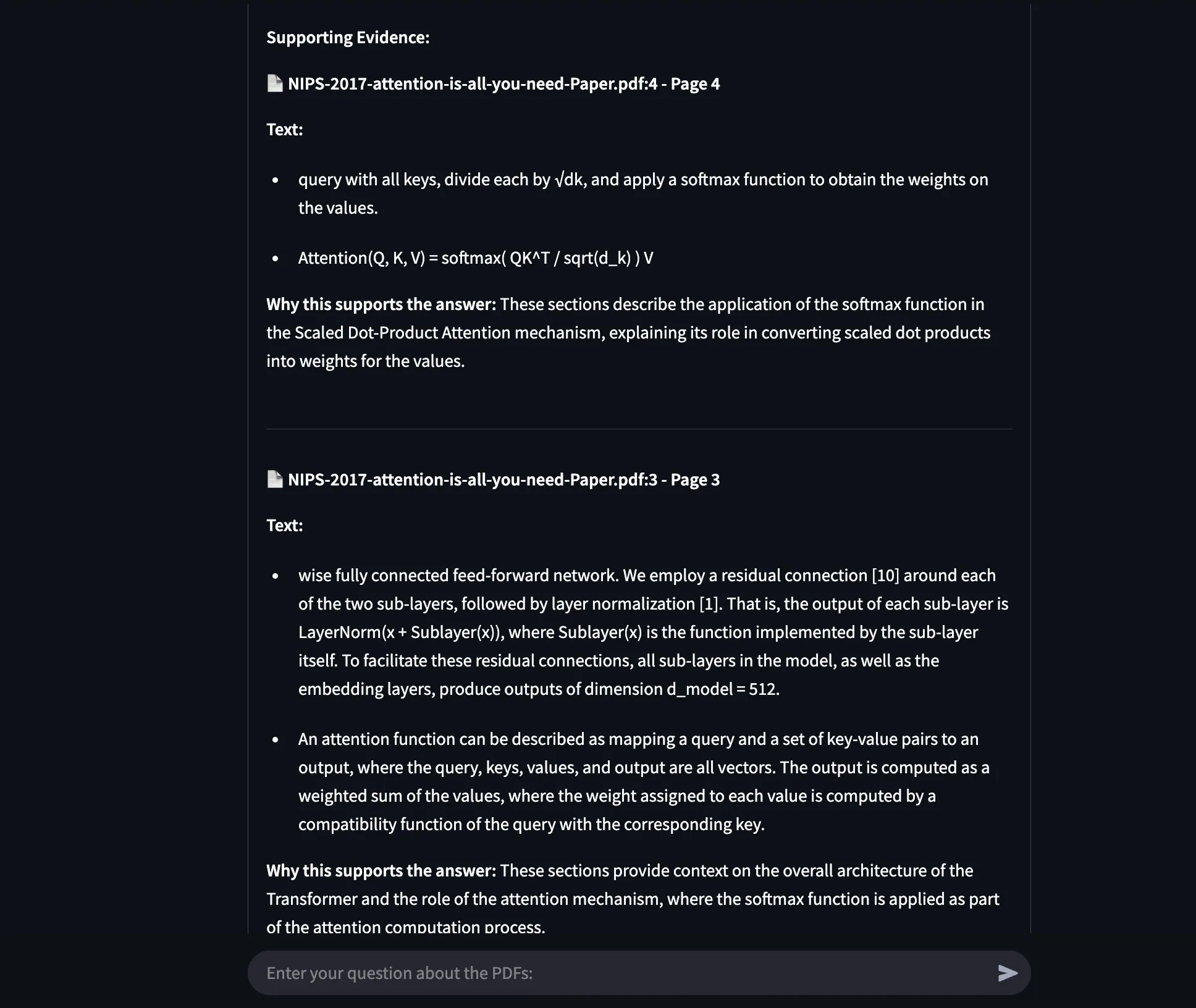
Example 3: Examining Figures for Exact Evidence
Previous prompt was a little vague but notice what happens when I prompt the system to examine figure 1 explicitly. It is able to visually ground the answer in the figure and provide exact evidence:
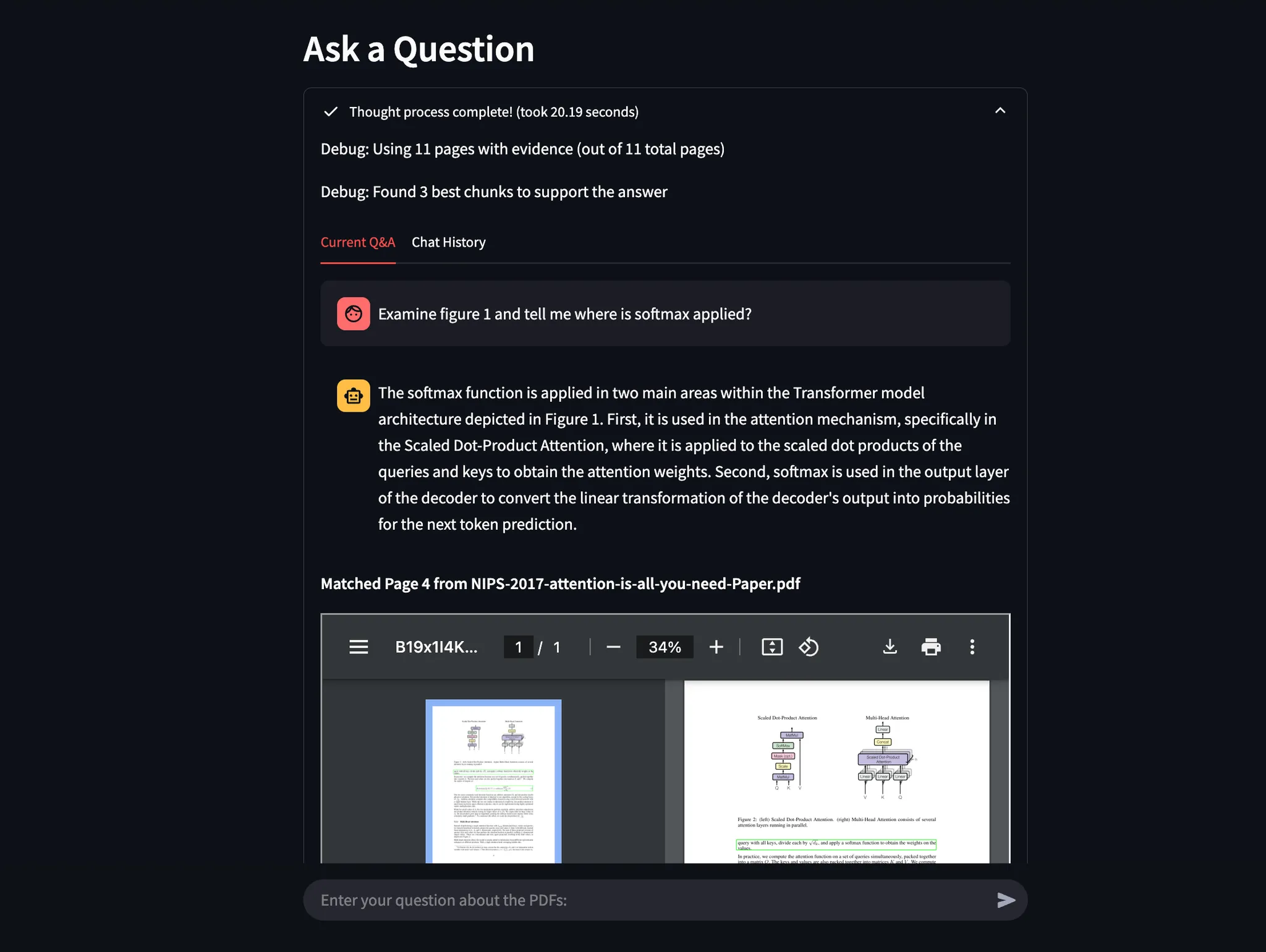
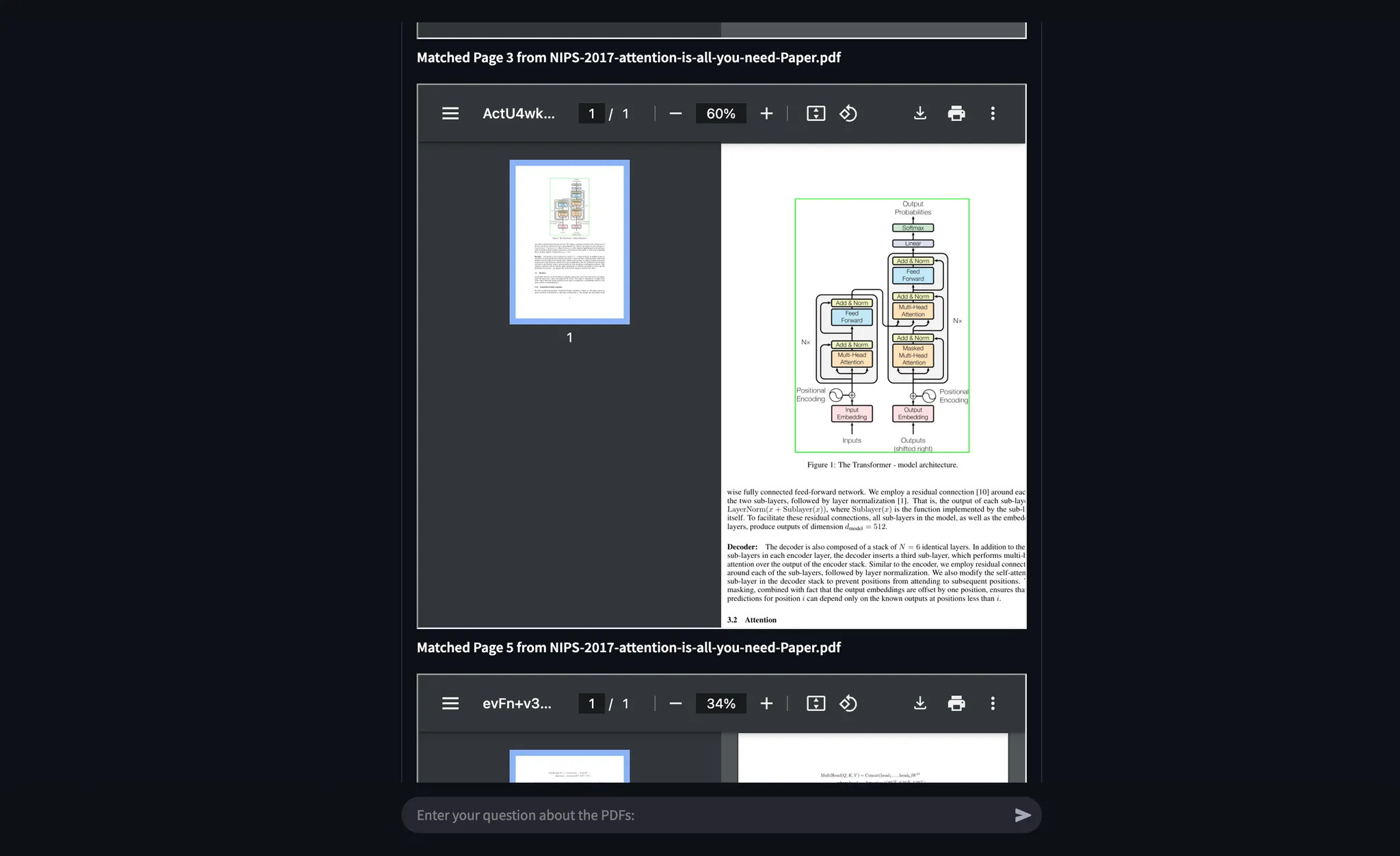

I’m sure that by now, you must be amazed, thinking about how well you could leverage this technology in your domain and already imagining the ways you could extract meaningful insights from your data while ensuring visually grounded facts that build confidence in the answers—providing exact evidence and minimizing hallucinations to almost zero!
Conclusion
Building a “Chat with PDF” tool that truly understands document layout is no longer just wishful thinking. By leveraging Agentic Document Extraction you can offer an end-to-end solution that not only answers questions but also points users to the precise PDF region backing those answers.
What Do You Think?
Ready to see how your own documents stand up to an Agentic approach?
Get started with our API, join our community, and share what you build!
Stay tuned for Part 2, “Beyond OCR: Building Apps with Agentic Document Extraction API,” where we will discuss how we built the app and leveraged our Agentic Document Extraction API to perform visual grounding and generate associated reasoning for every relevant region.


