
TL;DR
Enterprise workflows rarely receive perfectly sorted documents. Instead, they receive mixed document bundles—a 50-page PDF containing a few critical invoices buried among dozens of irrelevant cover pages, terms, and policies. Sending the entire document through one pipeline is both expensive and can lead to inaccuracies. The ADE Classify API acts as a pre-parse triage layer. By evaluating and labeling the raw document page-by-page based on your custom classes, it allows you to filter out noise to save compute costs and intelligently route specific pages to their appropriate downstream processing paths.
The Problem: The High Cost of Unsorted Data
In an ideal document processing pipeline, every document is clean, single-purpose, and perfectly formatted. In reality, enterprise systems ingest mixed document bundles. A client applying for a mortgage doesn't upload perfectly categorized files; they scan their earnings statements, bank records, utility bills, and a blurry picture of their passport into a single 50-page PDF.
This creates two massive architectural bottlenecks if you attempt to process the file as-is:
- Wasted Compute (The Cost Problem): Heavy document processing—like OCR, parsing, and LLM extraction—is computationally expensive. If you parse a 50-page document when you only needed the two pages containing invoices, you just wasted credits and processing time on 48 pages of noise.
- Extraction Hallucinations (The Accuracy Problem): If you pass that massive, parsed text dump to an extraction agent designed to pull "Invoice Totals," the model loses focus. It will inevitably attempt to extract financial data from a driver's license or a terms-and-conditions page, resulting in corrupted databases.
The Solution: Pre-Parse Classification
To build scalable, cost-effective processing pipelines, you cannot parse blindly. You need a triage layer that sits at the very front of your architecture, evaluating the raw file before heavy processing begins.
The ADE Classify API acts as this intelligent routing layer. Here is how the classification pipeline works:
- Define Classes: You define a JSON list of custom document classes, including semantic descriptions to guide the model.
- Page-by-Page Evaluation: The API evaluates the massive document concurrently, analyzing every single page.
- Classification & Reasoning: The API assigns each page a specific class and provides a detailed reasoning string explaining the decision.
- Downstream Routing: Your application uses these page labels to route the right pages to the right processing pipelines.
Architectural Advantages of Pre-Parse Classification
Implementing Classify at the top of your funnel unlocks several critical capabilities for enterprise teams.
1. Cost-Effective Filtering
Because Classify operates before the heavy ADE Parse step, it acts as a highly efficient filter. If an insurance company receives a 100-page claim packet, Classify can instantly identify the 10 pages of "Medical Records" and 2 pages of "Invoices." Your system can discard the remaining 88 pages of fluff, dramatically reducing your token consumption and overall processing costs.
2. Dynamic Workflow Routing
Different document types require entirely different workflows. Classify enables true dynamic routing. Once the API labels the pages, your application can effortlessly fork the workflow: sending pages 1–3 to the "Bank Statement Pipeline," pages 4–5 to the "Earnings Statement Pipeline," and flagging the rest for human review.
3. Instructional Schemas (Zero-Shot Accuracy)
You are not limited to passing generic category names and hoping the model guesses correctly. The Classify API accepts a structured JSON array where you can provide explicit descriptions.
By passing an instruction like {"class": "invoice", "description": "A commercial bill with line items, totals, and payment terms"}, you are applying prompt engineering directly into the routing layer. This eliminates ambiguity between similar documents (e.g., a generic receipt vs. a formal invoice) without the need to train or fine-tune a custom model.
4. Explainable AI and Fallback Handling
A black-box AI that just outputs labels isn't enough for enterprise routing. Classify returns a structured JSON response that provides a reason for every page. It tells you exactly why a page was classified a certain way.
Furthermore, if an anomalous page appears (e.g., a handwritten note in the middle of a loan packet), the API does not force it into an incorrect bin. It intelligently labels the page as unknown and uses a suggested_class field to explain what it thinks the anomaly actually is, providing critical debugging context. Unknowns become the seed of a review queue: everything with a clear class flows straight through, unknowns go to a human, and the reason field is logged for downstream auditing.
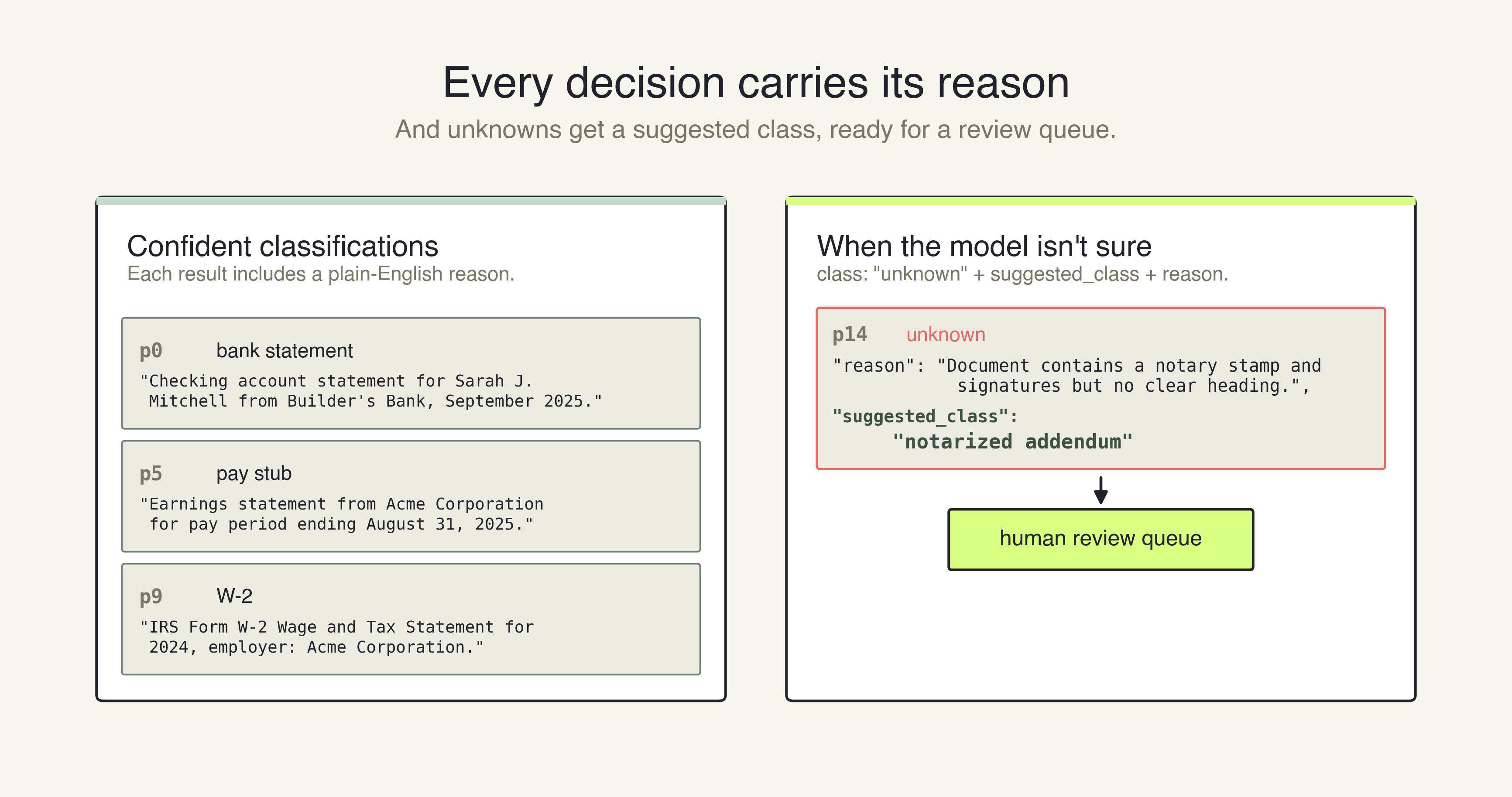
ADE Classify in Action
Integrating this triage layer requires passing a cleanly structured JSON array of classes in your API call. This allows you to shape the model's reasoning on the fly. Notice how you can mix classes with detailed descriptions and classes that are self-explanatory:
curl -X POST 'https://api.va.landing.ai/v1/ade/classify' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-F 'classes=[{"class":"invoice","description":"A commercial bill with line items, totals, and payment terms"},{"class":"bank_statement","description":"A monthly summary of account transactions"},{"class":"earnings statement"}]' \
-F 'document=@document.pdf'Once the API returns the page-by-page breakdown, your pipeline logic takes over: filtering out the unneeded pages, routing the invoice pages to a financial extraction tool, and sending the earnings statement pages to the HR pipeline.
Start Routing Intelligently
Stop wasting compute on irrelevant pages and feeding downstream agents chaotic, mixed data. By placing the ADE Classify API at the front of your architecture, you ensure your pipelines are cost-effective, precise, and routing-aware from step one.
- Try out your document on va.landing.ai for quick validation and testing.
- Try the API: Upload a mixed bundle and inspect how the API reasons through the pages.
Read the Documentation: Full reference for the ADE Classify API.