How Autyn Cut Loan Processing from 2 Hours to 2 Minutes at 98% Accuracy
LandingAI Team and Autyn

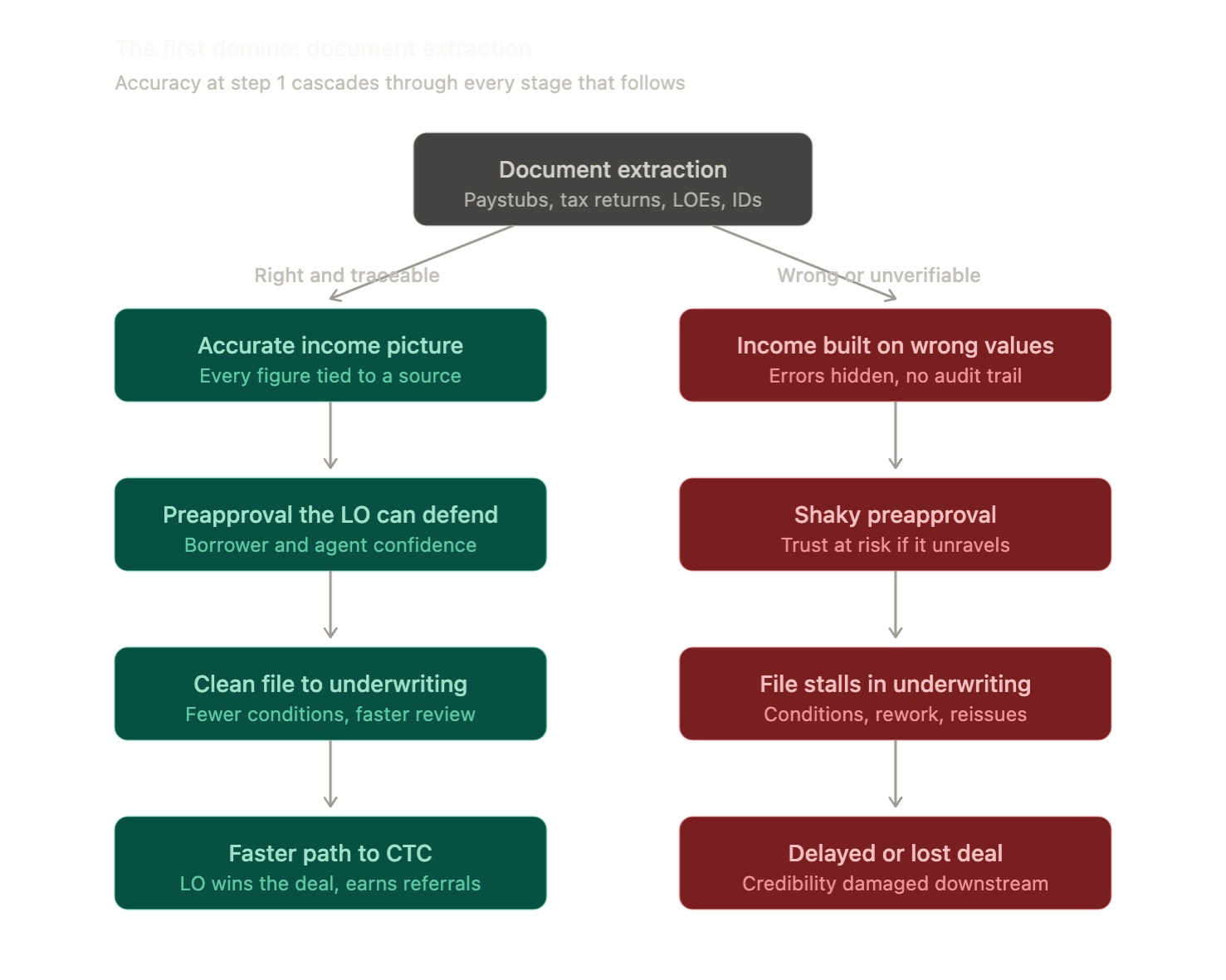
Reconstructing borrower income from a stack of unstructured tax returns, paystubs, and bank statements is the most error-prone task in a mortgage file — and the bottleneck Autyn set out to automate.
Autyn solved this by replacing a brittle OCR-plus-LLM pipeline with a schema-driven, confidence-scored extraction layer. The result is an income engine loan officers can actually stand behind:
- 94–98% field-level accuracy on the borrower documents that used to break the old pipeline
- End-to-end income extraction of a full borrower package in 1–3 minutes, work that takes a human 1–2 hours
- 500+ loan files and 3,000+ documents processed in production
- Loan officers save 2–4 hours of manual work per file
- Every extracted value returned with a source tag and confidence score, so low-signal fields route to human review instead of passing silently
Reliable extraction did not just reduce manual work — it gave Autyn a defensible income figure on every file.
Automating the most judgment-heavy task in a mortgage file
Autyn is an AI-native mortgage operations platform built for independent mortgage brokers. The platform automates the document-heavy work of loan processing — document verification, income calculation, and condition management — so mortgage originators can close more files without adding headcount.
The fastest preapproval often wins the deal. And a preapproval rests on a borrower's full financial picture, which starts with reading their documents accurately. A single self-employed borrower file can run 80-plus pages with five or more distinct document types interleaved inside one PDF: paystubs, W-2s, full tax returns with Schedule C and Schedule E attachments, business returns such as the 1120-S, K-1s, bank statements, and identity documents. Reconstructing a defensible income figure from that pile is the most error-prone, judgment-heavy task a loan processor performs.
"Very often a loan officer who gets a borrower a solid preapproval fastest earns the deal and the real estate agent's referrals. Reconstructing income is the hardest part, and Agentic Document Extraction is the cornerstone to getting it right and traceable. Accurate data upfront means we can get a cleaner loan file to the underwriter and get to CTC faster. Get it wrong and everything downstream gets affected." - Myra D'Souza, CEO, Autyn
Where conventional document AI breaks down in lending
Autyn's income engine has to read some of the most inconsistent documents in consumer lending. The friction was not document length — it was that the documents follow no reliable format. Pain concentrated in four places:
- Letters of explanation. Free-form and borrower-written, with no standard template or layout from one file to the next.
- Paystubs. Dozens of different formats across employers and payroll providers, with no consistent placement of earnings, deductions, or year-to-date figures.
- State and government-issued documents. Identity and benefit documents that vary by issuing agency, with no uniform format.
- Personal tax returns (Form 1040) and supporting income documents. The pages that actually matter are buried inside large, mixed PDF bundles alongside unrelated paperwork.
Autyn's early pipeline was the same one most document-automation teams reach for first: conventional OCR plus a large language model. It broke down on exactly the documents that mattered most:
- Template- and pattern-based extraction failed on documents it had not seen before. The moment a paystub, letter of explanation, or state document deviated from a known layout — which was most of the time — values landed against the wrong labels or were missed entirely.
- LLM-only extraction hallucinated and could not show its work. Values came back with no traceable link to a page or location in the source document, which is unacceptable in a regulated lending workflow where every figure has to be defensible to an underwriter and an auditor.
- Cost and reliability problems at scale. Fallback extraction tooling produced retry loops and unpredictable per-file cost as volume grew, without solving the underlying accuracy gap.
- No confidence signal. The pipeline could not flag which extracted values were shaky and needed a human look, so errors passed through silently instead of being caught.
The business cost was existential, not cosmetic. A wrong income figure is not a typo — it is a misqualified borrower and a preapproval that falls apart later. In a referral-driven business, a collapsed preapproval damages a loan officer's credibility with both the borrower and the referring agent. Lost trust is far more expensive than the rework itself.
Choosing an extraction layer that holds up in a regulated workflow
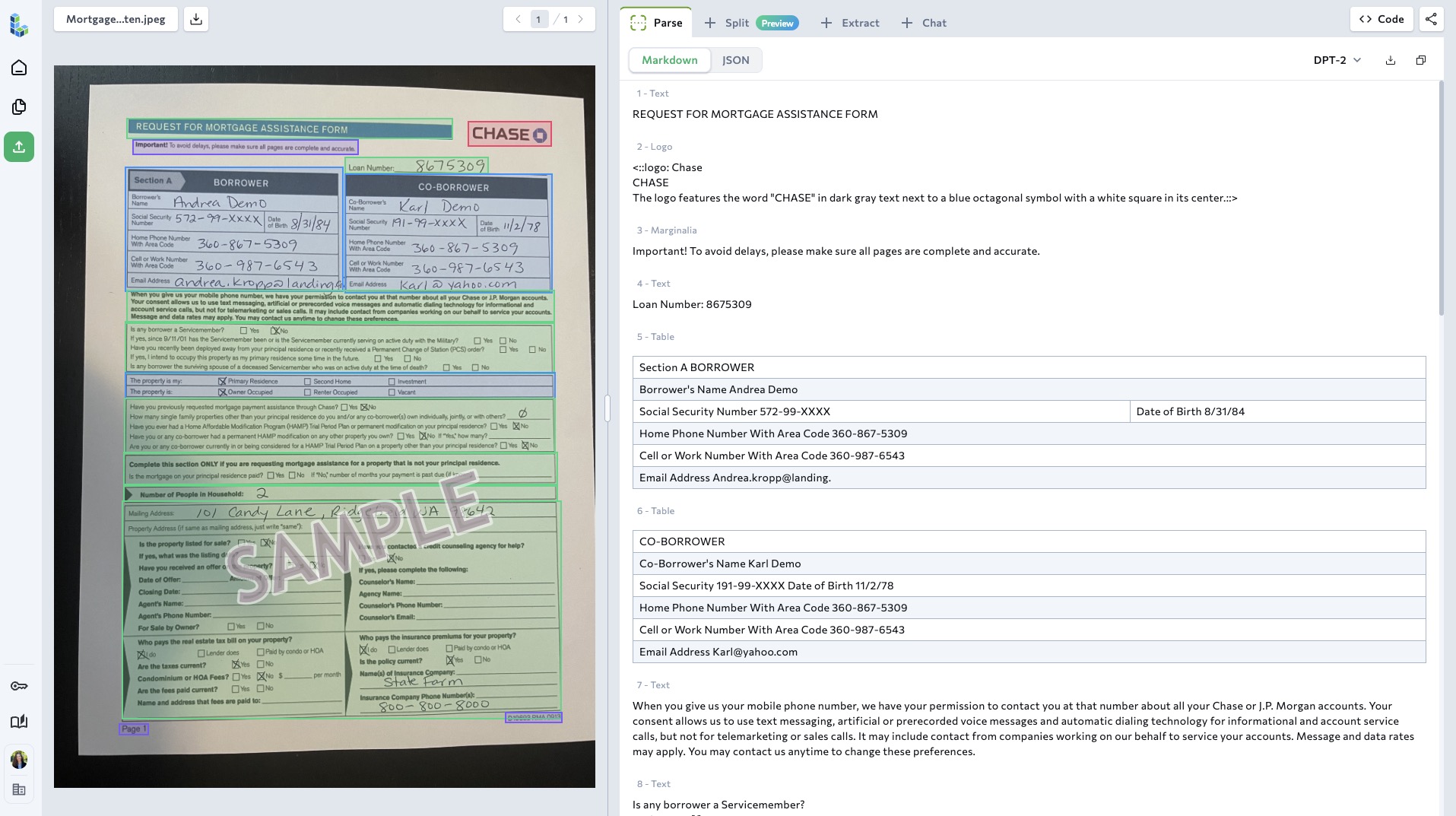
Autyn evaluated document-processing options against the standard the mortgage vertical actually demands: not just "did it read the page," but "can we prove where every number came from." LandingAI's Agentic Document Extraction (ADE) was assessed directly against real borrower documents — tax returns, paystubs, business filings — rather than benchmark samples.
ADE outperformed the alternatives on the documents that had been breaking the old pipeline. In Autyn's production logs, ADE returns each extracted field with an explicit source tag and a numeric confidence score — for example, a partnership EIN at 99.7% confidence and a low-signal field flagged at single-digit confidence on the same return, giving Autyn exactly the per-value signal its earlier OCR-plus-LLM stack could not provide.
Key factors in the decision:
- Schema extraction. ADE extracts against a schema Autyn defines, so output arrives as predictable, typed data — consistent even when the underlying document format varies from one borrower to the next.
- Per-field confidence scoring. Low-confidence values route to human review instead of passing silently. Extraction becomes a controllable step, not a black box.
- Source-tagged outputs. Every value is linked back to a page and location in the source document, which is the difference between an answer and a defensible answer.
- Deployable in regulated environments. ADE ships with enterprise security and compliance posture, including HIPAA and SOC 2 Type II. Customer data is not used for training.
- Developer-first integration. Autyn integrated ADE directly via its API, using the official Python library inside the platform's AIML layer. ADE slotted in as a dedicated extraction component without requiring any custom model training or labeled-data collection — Autyn was extracting structured data from real loan files using ADE's pre-built models and its own schemas.
Sample image of mortgage assistance form
A traceable, confidence-scored extraction foundation for income
ADE serves as the document extraction layer powering Autyn's income engine across its full borrower document set: tax returns, paystubs in many different formats, letters of explanation, and state and government-issued documents. ADE works alongside other tools in a deliberately layered pipeline and handles a substantial share of Autyn's document-extraction workload.
Every value ADE returns carries a confidence score and a source tag. Autyn uses that metadata to:
- drive review thresholds and route low-confidence fields to a processor
- build verification and alert logic that checks not only the value of a field but whether the data needed to make an underwriting determination is actually present
- generate auditable, source-linked loan analysis documents for processors and underwriters
With confidence-scored extraction handling the high-variance documents, Autyn's team focuses on the underwriting logic and human-in-the-loop workflows that sit on top — not on patching extraction errors.
Faster files, higher accuracy, defensible numbers
Since deploying ADE, Autyn has processed 500+ loan files and 3,000+ documents in production, with loan volume growing sharply in 2026 across the full range of borrower documents — including the non-standardized formats that would have broken the old pipeline.
Business impact:
- Field-level accuracy of 94–98% on the borrower documents that used to break the old pipeline, with document classification confidence in the 90%+ range.
- Per-document parse and extract in 5–30 seconds depending on length; end-to-end income extraction of a full borrower package in 1–3 minutes, work that takes a human 1–2 hours.
- Loan officers save 2–4 hours of manual work per file.
- Extraction stopped being a source of silent error. Per-field confidence scores power internal human-in-the-loop processes, raising accuracy for Autyn's clients.
- New document types ship faster. The team can quickly train and add new documents to the pipeline as the borrower mix evolves.
- Per-file extraction cost stays in line with margins, even as volume scales.
What's next
Autyn's roadmap deepens its use of ADE as both the platform and its loan volume scale:
- Tighter cost per file. Move toward document-level change tracking so that when a broker swaps a single updated document, only those pages are re-extracted rather than the whole file — keeping per-file extraction cost low as volume grows.
- Broader document coverage. Extend schema-first extraction to more of the borrower document set and edge-case filings, so a larger share of every loan file is handled by accurate, grounded extraction.
Make extraction your foundation — not your bottleneck
See how Autyn is automating mortgage operations: 👉 https://autyn.ai
Try Agentic Document Extraction on your own documents (start for free): 👉 https://ade.landing.ai
About LandingAI
LandingAI is an AWS Partner, specializing in AI-powered solutions for processing images and documents. The company's Agentic Document Extraction API enables organizations to convert complex, unstructured documents into structured, LLM-ready data at scale, leveraging the robust and secure infrastructure of AWS. LandingAI's solutions are trusted by enterprises across industries to drive efficiency, accuracy, and innovation in document-intensive workflows.