How GreenLite Cut Plan Review Time by 50% with Reliable Document Extraction
GreenLite solved this by rebuilding their extraction layer - enabling scalable AI-driven review and ultimately cutting turnaround time by 50%. With a document extraction foundation in place.
LandingAI Team and GreenLite

Reviewing construction plans for code compliance at scale requires comprehensive data, domain-specific AI agents, and reliable document extraction. Without that last piece, the entire system breaks down.
GreenLite solved this by rebuilding their extraction layer - enabling scalable AI-driven review and ultimately cutting turnaround time by 50%. With a document extraction foundation in place:
- Plan review turnaround improved by ~50% based on internal measurements
- Precision and recall exceeded 90% as of publication date
- Engineering effort shifted from fixing extraction errors to advancing higher-value AI reasoning
- New document workflows became possible beyond the initial scope
Reliable extraction didn’t just improve accuracy, it unlocked scale.
Scaling plan review across hundreds of jurisdictions
GreenLite, is an AI-native permit intelligence and code compliance platform that helps national brands and commercial developers secure construction permits faster and more predictably across the U.S. The company combines an AI-driven compliance engine with in-house AEC experts to manage the full permitting lifecycle, from jurisdiction diligence through permit issuance.
Operating across hundreds of jurisdictions, GreenLite processes hundreds of projects each month, each involving large, complex document sets that often span tens to hundreds of pages.
At its core, plan review is both a document and a reasoning problem. Before any compliance analysis can occur, unstructured plan sets must be reliably extracted and structured. For GreenLite, extraction quality directly determined how effectively their AI systems could operate and scale.
"Our Plan Review Agent has a lot of complicated components under the hood: traversing building code knowledge graphs, reasoning across disciplines and sheets, assessing issues informed by historical projects. None of it works if we can't trust what came off the page. ADE gave us a reliable foundation, so our team could focus on incorporating our team’s expertise into our compliance reasoning system." - Daniel Valner, Product Manager, GreenLite
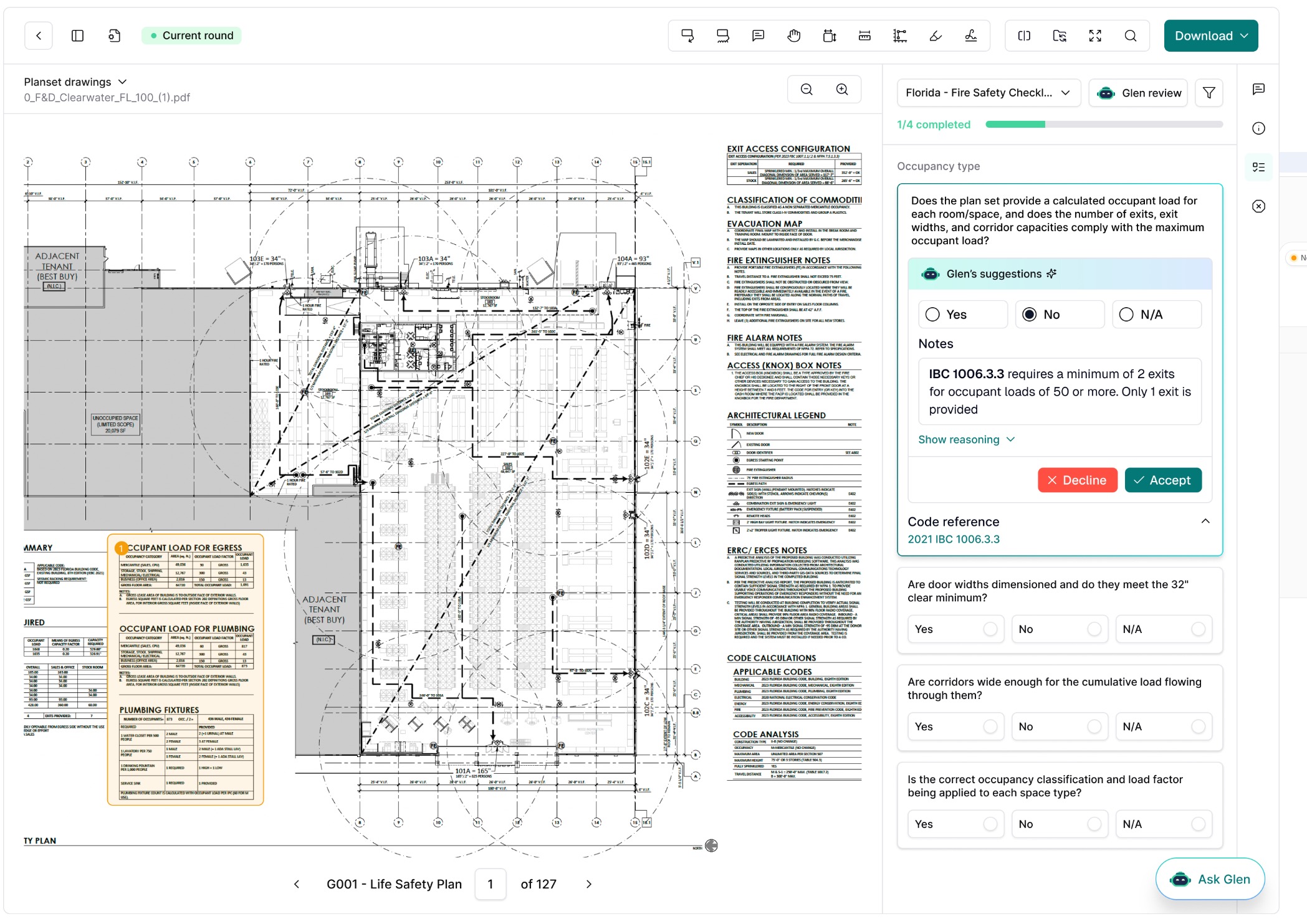
Example of GreenLite’s Plan Review at work
Where document extraction fails in real workflows
Plan sets are among the hardest documents to parse in any industry. They vary widely in style, font, and layout from project to project and architect to architect. Pages mix dense technical figures, stamped drawings, multi-column specifications, and schedules that don't conform to any consistent template. Even within a single plan set, sheet-to-sheet variation is the norm rather than the exception.
Traditional OCR and off-the-shelf IDP/VLM tools struggled in predictable ways:
- Inconsistent textual extraction across fonts. Accuracy degraded significantly on non-standard or stylized fonts common in architectural drawings, producing unreliable output that downstream agents couldn't trust.
- Tables failed to extract properly. Schedules and tabular data came out as unstructured text, broke at page boundaries, or lost row-column relationships entirely.
- Imprecise bounding boxes. Spatial coordinates returned by other tools were loose enough that referencing extracted content back to its location on the sheet was unreliable, which mattered for both agent reasoning and reviewer trust.
- Lost layout and figure-text relationships. Multi-column order was scrambled, and the connection between figures and their surrounding text was dropped.
The business cost was real. Extraction inaccuracy caused GreenLite’s Plan Review Agent to fail on certain items, which meant more human review, slower turnaround, and a lower ceiling on how much scope the agent could confidently own.
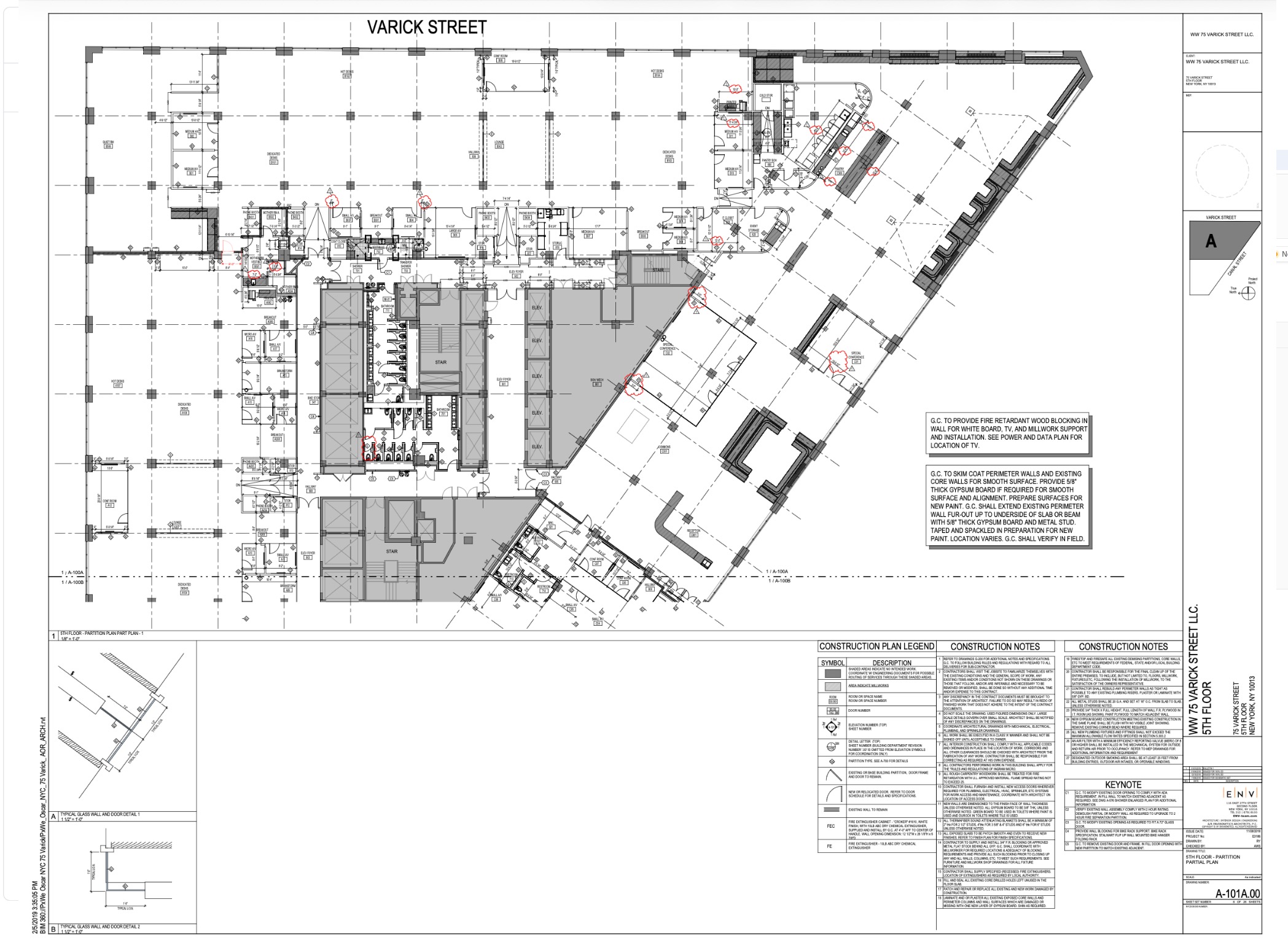
Example of plan sets with dense figures and non-standard layouts
Choosing an extraction layer that holds up in production
GreenLite ran a structured evaluation across a range of options, including VLM-based parsing with frontier models and several dedicated OCR and IDP providers. LandingAI's Agentic Document Extraction (ADE) was the most consistent performer on GreenLite’s document types, particularly on plan sets with dense figures and non-standard layouts, where other tools degraded unpredictably. The solution begins with intelligent indexing of all plan documents. Using layout-aware parsing and visual grounding, ADE extracts and tags text, diagrams, tables, and visual elements using LandingAI’s proprietary foundation models running on AWS GPUs.
Key factors in the decision:
- Consistency across document variation. ADE held up across the full range of plan set styles GreenLite’s processes, where other tools performed well on some layouts and poorly on others.
- Layout-aware parsing. Structural context of tables, schedules, and multi-column pages was preserved rather than collapsed to flat text.
- Developer-first integration. A clean API and library made it straightforward to slot ADE into GreenLite’s existing agent pipeline.
A reliable extraction foundation for plan review agents
LandingAI’s ADE serves as the document extraction layer powering GreenLite’s Plan Review Agent.
Each plan set is processed into structured outputs that preserve layout, content type, and precise spatial grounding. Large documents are handled automatically—split, parsed, and reassembled into a coherent, fully indexed view—so downstream systems always operate on consistent, complete data.
This structured output is stored as a unified data layer, including:
- page-level content chunks
- associated images
- metadata such as page index, coordinates, and document context
All downstream agents across compliance reasoning, knowledge graphs, and review workflows operate on this structured representation, not raw PDFs.
This allows GreenLite’s system to:
- reason across documents reliably
- maintain context across pages and sections
- reduce dependency on manual correction
With extraction handled consistently, engineering and domain experts can focus on higher-value reasoning and decision-making—rather than fixing document errors.
Faster reviews, higher accuracy, less manual work
Since deploying ADE as GreenLite’s extraction foundation, GreenLite's Plan Review Agent has processed thousands of checklist items across hundreds of projects. System-wide, precision and recall both exceed 90%, and performance has continued to improve as the system matures.
Business impact:
- Plan review turnaround time has improved by roughly 50% based on internal measurements.
- As of this publication, close to 90% of the recommendations surfaced by GreenLite’s Plan Review Agent are accepted by their expert reviewers.
- Reliable extraction freed GreenLite's engineering team to focus on higher-leverage work on the knowledge graph and agent reasoning layer rather than patching around extraction errors.
- Extraction quality opened the door to use cases beyond the original scope, including additional document types handled by GreenLite’s other agents.
Make extraction your foundation—not your bottleneck
See how GreenLite is scaling AI-powered plan review:
👉 https://greenlite.com
Try Agentic Document Extraction on your own documents(start for free):
👉 https://va.landing.ai
About LandingAI
LandingAI is an AWS Partner, specializing in AI-powered solutions for processing images and documents. The company’s Agentic Document Extraction API enables organizations to convert complex, unstructured documents into structured, LLM-ready data at scale, leveraging the robust and secure infrastructure of AWS. LandingAI’s solutions are trusted by enterprises across industries to drive efficiency, accuracy, and innovation in document-intensive workflows.