Credit Support Annex Automation: Margin Collateral Agent

TL;DR
The Margin Collateral Agent automates CSA extraction, collateral normalization, deterministic margin calculation, and audit-ready explanation generation for OTC derivatives workflows.
That matters because FMSB reported that an average 45% of margin calls were disputed in June 2024, and 54% of those disputes came from disagreements on inputs and valuation models during exposure and margin calculation (FMSB, 2025).
The system uses LandingAI ADE for PDF extraction, three Claude-powered normalization agents, a rule-based validation layer, a deterministic five-step margin calculator, and Claude Sonnet for explanations with clause-level citations.
The architectural bet is simple: LLMs handle document interpretation and collateral matching where judgment is needed. The arithmetic stays rule-based and reproducible. Every field traces back to a source page. Every calculation step is logged. The system produces audit scripts, not just answers.
Built by Beemnet Haile, an active member of the LandingAI builder community, during the Financial AI Hackathon Championship 2025. Explore the source code on GitHub or watch the demo video to see the full pipeline in action.
Jump to: Document extraction | Collateral normalization | Margin calculation | Technical stack
Why This Matters
Outstanding OTC derivatives hit $846 trillion in notional value at mid-2025, up 16% year-over-year, the largest annual increase since 2008 (BIS, 2025). Behind those positions sit Credit Support Annexes that define how collateral moves between counterparties.
Leading derivatives firms collected $1.5 trillion in combined initial and variation margin at year-end 2024 (ISDA, 2025). Cash as variation margin collateral fell from 80.0% in 2020 to 68.3% in 2024 while government securities and other assets gained share, making manual collateral matching harder to scale.
The usual alternatives are spreadsheets and human review, or enterprise platforms that cost millions and take months to implement. The Margin Collateral Agent addresses that gap: automate the workflow without giving up determinism, provenance, or auditability.
How Does Credit Support Annex Automation Start with Document Extraction?
LandingAI ADE parses the CSA, then a schema-driven extraction pass pulls exactly the fields the margin engine needs, each with source page provenance.
LandingAI ADE scored 99.16% on the DocVQA validation split when questions were answered from ADE parse output without image access (LandingAI, 2025). That is a parsing-fidelity benchmark, not a direct CSA extraction score, but it reflects how faithfully the parser preserves document structure for downstream workflows.
ISDA's own May 2025 work on benchmarking generative AI for CSA clause extraction reached a similar architectural conclusion: integrating industry-specific data significantly boosts extraction accuracy, and a modular framework outperforms generic prompting on nuanced legal language (ISDA, 2025). The Margin Collateral Agent's CSA-specific schema applies that same principle.
The extraction pipeline runs three steps:
Upload and validation. The system checks PDF extension, file size limits, and PDF signature bytes before accepting a document. No malformed files enter the pipeline.
Parse. The PDF goes to LandingAI ADE, which returns structured markdown preserving the document's layout and content hierarchy.
Extract. The parsed markdown runs through a second ADE pass using a custom CSA extraction schema. This schema targets exactly what downstream processing needs: party names, effective dates, thresholds, minimum transfer amounts, eligible collateral definitions, haircut schedules, independent amounts, and rounding conventions.
Why we scoped the schema this way: When we built the hackathon version, we made the extraction schema CSA-specific rather than generic. A general-purpose extractor returned too much noise and missed patterns like infinity thresholds or tiered haircut tables. Constraining the schema gave us cleaner output and fewer normalization errors downstream.
Every extracted field carries source page provenance. If the system says the MTA is $500,000, you can trace that claim back to a specific page in the original PDF.
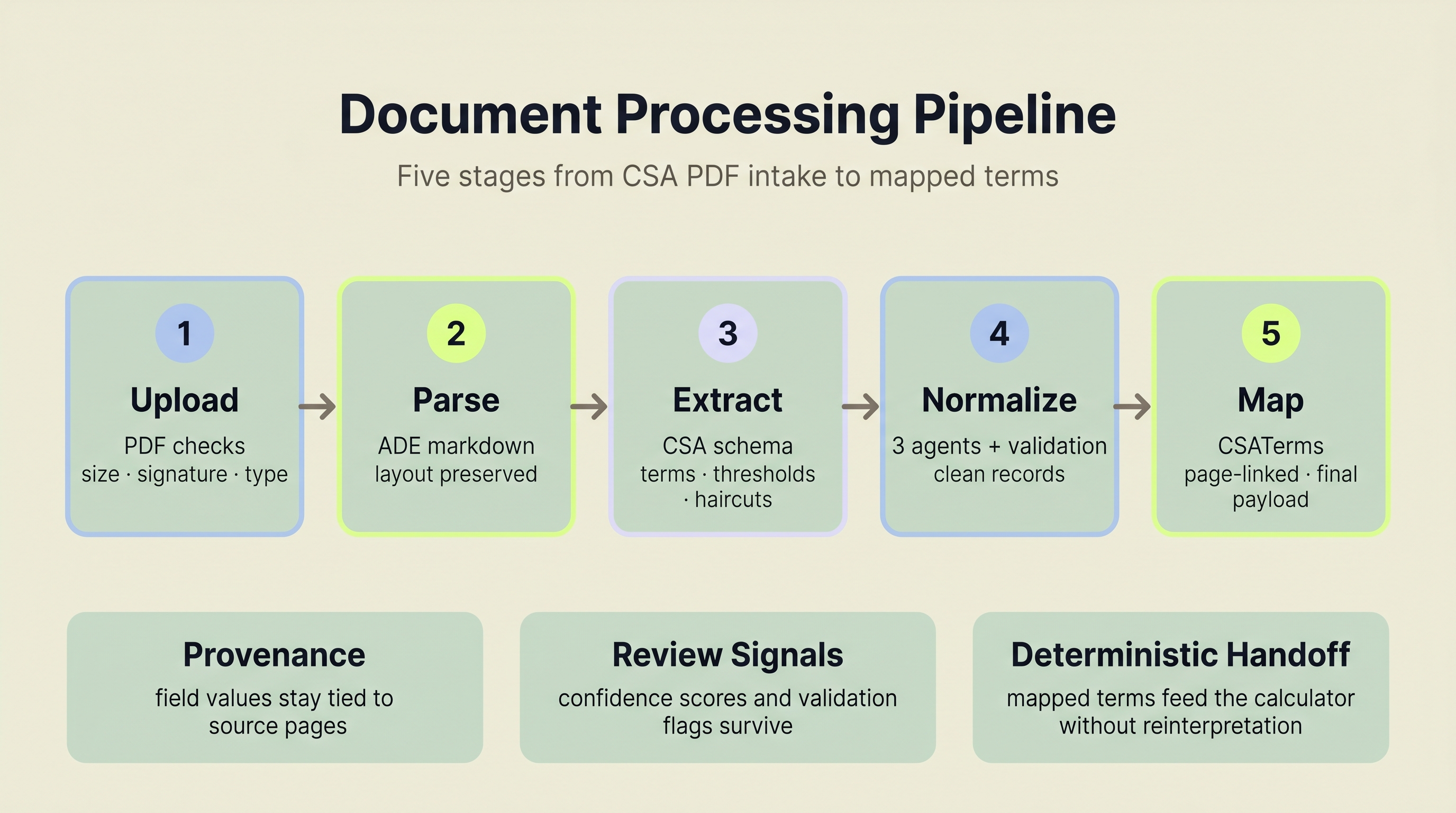
The five-stage document pipeline: upload and validate, parse via LandingAI ADE, extract with a CSA-specific schema, normalize with multi-agent reasoning, then map to the margin calculator.
What Does Multi-Agent Collateral Normalization Actually Do?
Normalization turns raw CSA text into structured, machine-readable collateral data, and it's where 54% of margin disputes originate.
Of the 45% of margin calls disputed in June 2024, 54% of those disputes came from disagreements on inputs and valuation models during exposure and margin calculation (FMSB, 2025). Raw CSA text is not machine-readable. "US Treasury Bills with remaining maturity of one year or less" needs to become a structured record with asset type, maturity range, and applicable haircut. That translation is normalization, and it's where most manual errors happen.
The normalization flow uses three Claude-backed agents running in parallel through asyncio.gather, then passes their combined output through a rule-based validation agent:
Collateral Agent. Runs a six-step reasoning chain (parse, detect ambiguities, resolve, validate taxonomy, validate logic, synthesize) that catches conflicts other approaches miss. If a collateral type description implies one maturity range while the valuation string implies another, the agent flags the conflict and resolves it rather than silently picking one. That silent misclassification is the kind of input error driving the 54% of disputes FMSB traced back to inputs and valuation models.
Temporal Agent. Handles timezone inference and time normalization. CSA documents express timing inconsistently: "New York time," "close of business London," bare 24-hour times with no zone. This agent resolves those references to standardized timezone identifiers.
Currency Agent. Identifies base currency, maps currency names and codes, and flags multi-currency provisions.
Validation Agent. Cross-checks the outputs of the other three agents. Flags contradictions, low-confidence fields, and anything that should go to human review.
What made this architecture work: The model-backed agents do the messy interpretation work, then the validation layer checks the combined output for contradictions and low-confidence fields. If the collateral agent is 60% confident about a haircut mapping, that uncertainty survives into the review path instead of getting hidden behind a clean-looking answer.
In a manual workflow, a collateral analyst reads "US Treasury Notes and Bonds with remaining maturity of 1 to 10 years" and makes a judgment call about which haircut tier applies. If two analysts read the same text differently, the margin call is different. The normalization layer makes that interpretation explicit, traceable, and reviewable before it reaches the calculator.
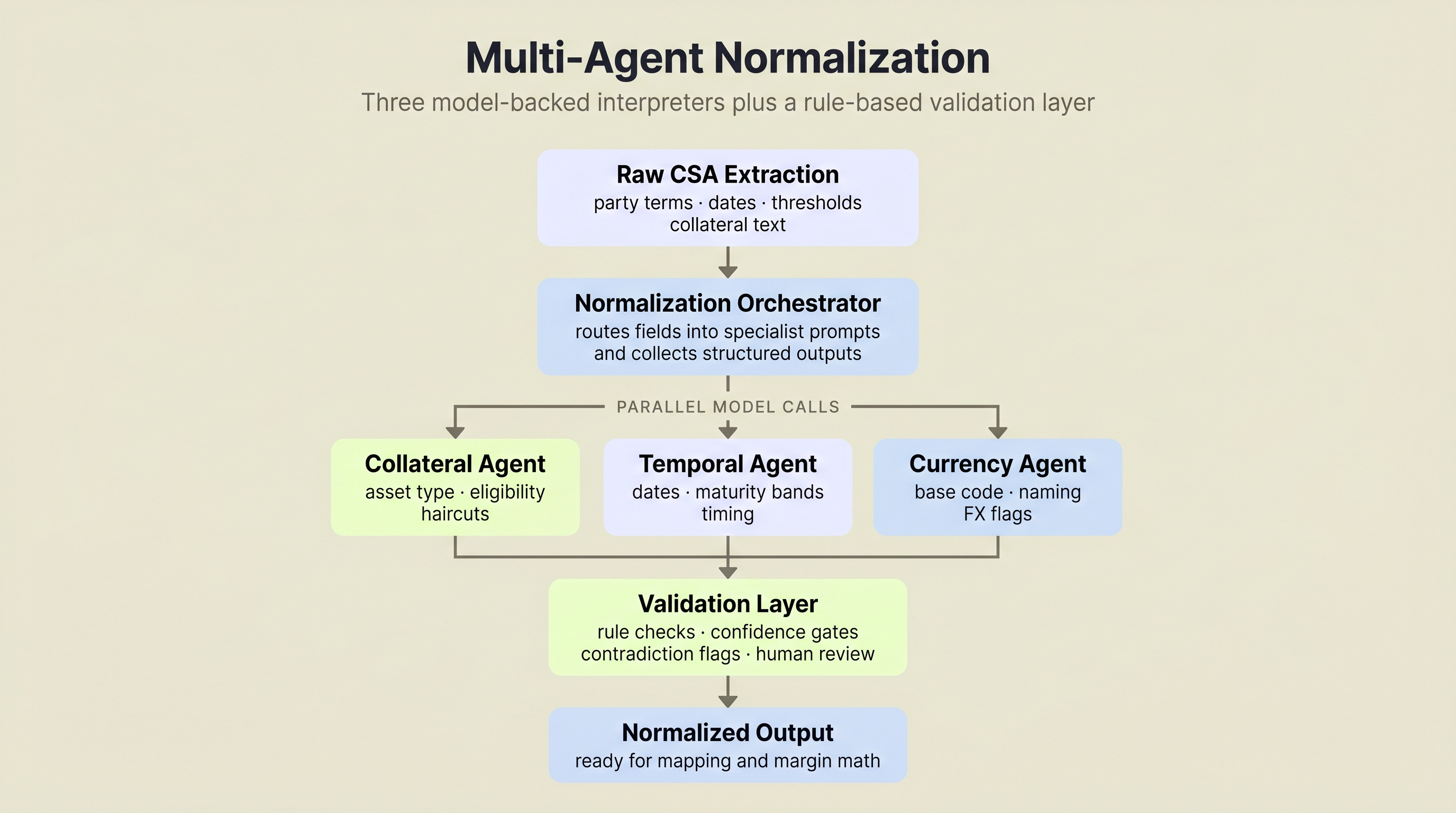
Three specialized agents run in parallel (Collateral, Temporal, Currency), then a Validation Agent cross-checks their combined output before it reaches the deterministic calculator.
| Workflow signal | Reported value | Why it matters |
|---|---|---|
| Margin calls disputed (June 2024) | 45% | Exceptions are common enough that workflow speed and auditability matter operationally. |
| Disputes arising during exposure and margin calculation | 54% | Input quality and model consistency are central failure points, not side issues. |
| Variation margin received as cash (year-end 2024) | 68.3% | Cash still dominates, but non-cash collateral is material, so eligibility matching cannot be skipped. |
Source: FMSB, 2025; ISDA Margin Survey, 2025.
Why Keep Margin Calculation Deterministic?
When $1.5 trillion in margin moves on calculation results, reproducibility is not optional. Same inputs must produce the same output every time.
ISDA reported that 32 firms collected $431.2 billion of initial margin and $1.0 trillion of variation margin for non-cleared derivatives at year-end 2024 (ISDA, 2025). That's why the margin engine is pure Python, not an LLM.
The calculator runs five steps in sequence:
- Exposure above threshold. Subtracts the party-specific threshold from current mark-to-market exposure. If the threshold is infinite (a real CSA provision), no collateral is required. The system handles this explicitly.
- Effective collateral after haircuts. Each posted collateral item has its market value reduced by the applicable haircut, looked up by matched asset description, credit rating scenario, and maturity range.
- Independent amount adjustment. Adds or subtracts any fixed collateral buffer specified in the CSA, based on the calculation perspective.
- MTA filter. If the resulting margin call falls below the minimum transfer amount, it rounds to zero.
- Rounding. The final amount is rounded according to the CSA's rounding convention.
Why we kept this deterministic: When we built the hackathon version, we wanted to be able to change prompts and models without re-validating the calculator every time. As long as the normalization layer emits the same structured output format, the math layer does not change. In a regulated workflow, that separation is the point.
The API selects party-specific parameters (threshold, MTA, independent amount) based on the calculation perspective. You can calculate from Party A's view or Party B's view against the same CSA terms, and both results are traceable.
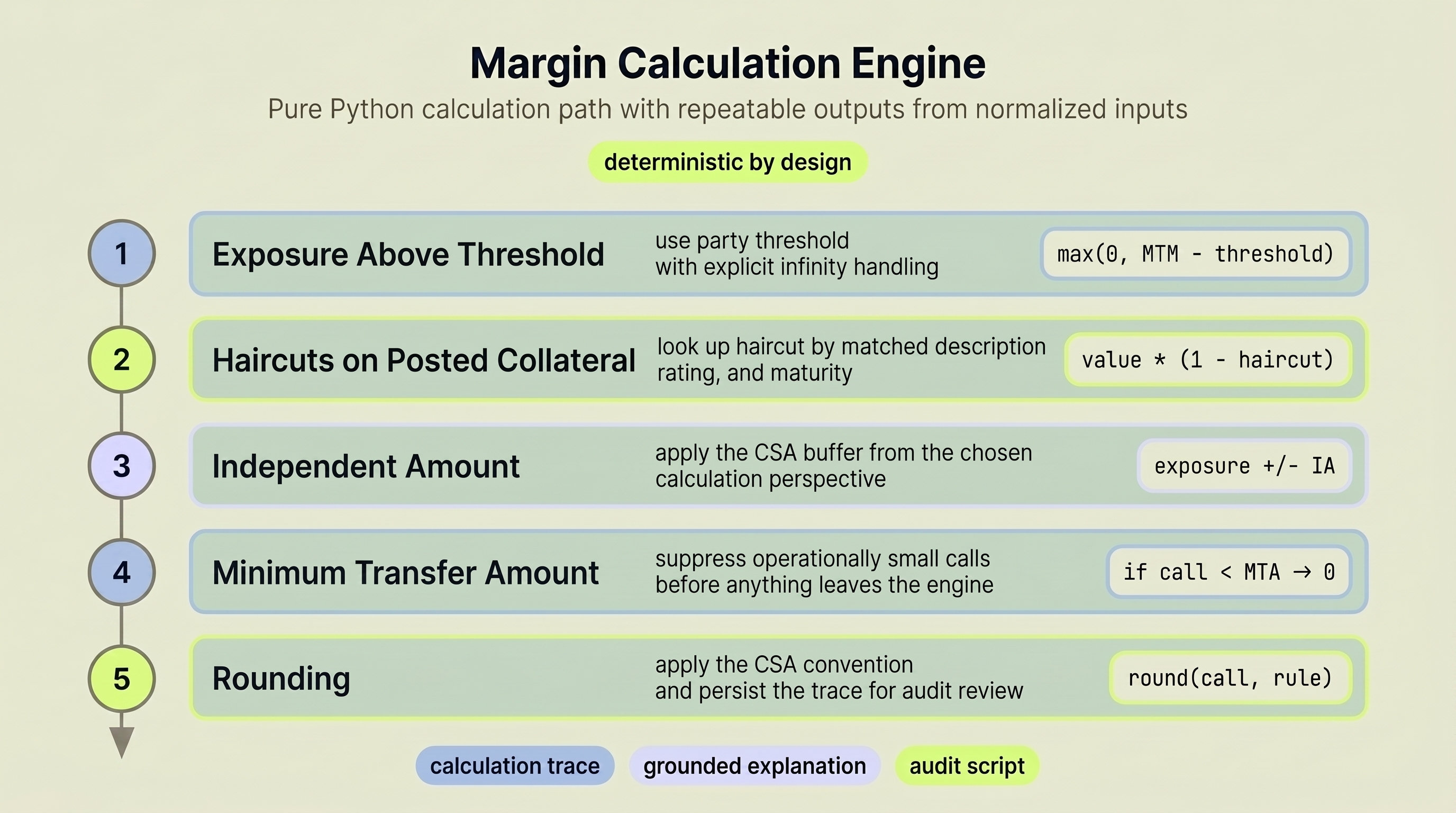
The five-step deterministic engine: exposure above threshold → effective collateral after haircuts → independent amount → MTA filter → rounding. Pure Python, no LLM calls.
How Does Collateral Import and Matching Work?
Cash as variation margin collateral declined from 80% in 2020 to 68.3% at end-2024, while government securities rose to 17.8% and other securities to 13.8% (ISDA, 2025). Collateral is diversifying, which means matching posted collateral against CSA-eligible categories is getting harder.
The import flow has three stages:
CSV upload. Users upload collateral holdings as CSV files with description, market value, and optional maturity ranges. The parser validates each row before anything moves forward.
AI-backed matching. A Claude-powered matcher compares each imported collateral description against the normalized CSA collateral definitions from the extraction pipeline. "FNMA 30-Year Fixed Rate MBS" needs to match against the CSA's "Agency mortgage-backed securities" category. This is a judgment call, and it's where AI outperforms lookup tables.
Haircut application. Once matched, the system looks up the applicable haircut by description, rating scenario, and maturity range. From here, the deterministic calculator takes over.
The handoff point is explicit. AI does the matching. Rules do the math. There is no ambiguity about where one ends and the other begins.
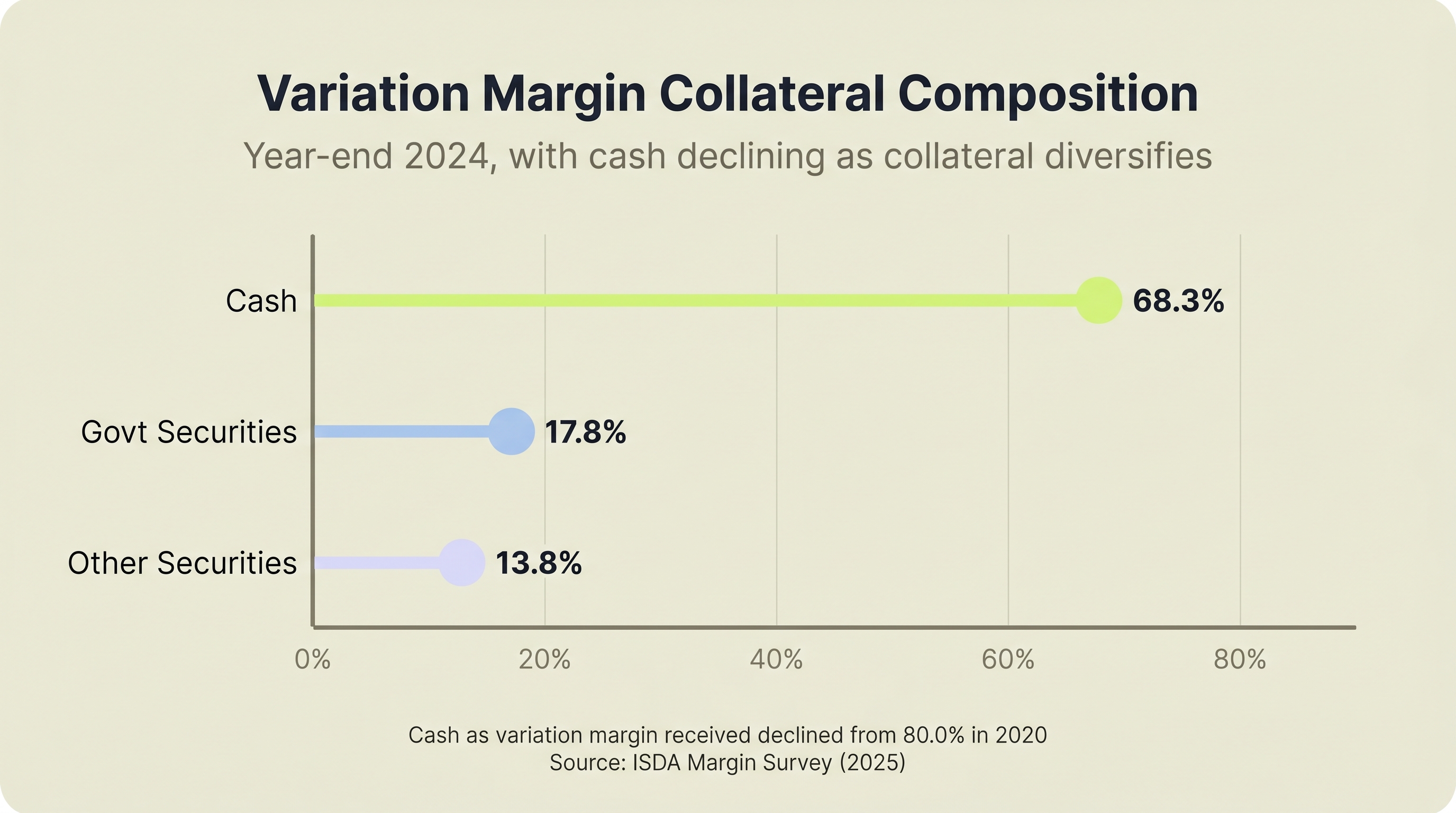
Cash as variation margin received fell from 80.0% in 2020 to 68.3% in 2024. Government securities and other assets are gaining share. Source: ISDA Margin Survey, 2025.
What Makes the Collateral Audit Trail Different from a Log File?
Auditability is the line between an interesting demo and something a risk officer can actually inspect. The Margin Collateral Agent builds it into three layers.
Explanation generation. After a margin calculation completes, Claude Sonnet generates a structured explanation grounded in the actual calculation steps, CSA terms, and collateral items. These aren't generic summaries; they reference specific thresholds, haircut percentages, and rounding rules from the source document.
Formula pattern analysis. A separate ClauseAgent extracts formula patterns from the CSA: delivery amount formulas, return amount structures, threshold logic, haircut structures, MTA rules, and rounding conventions. Each pattern gets a complexity score. This layer tells you not just what the calculation did, but what the contract says the calculation should do.
Audit script generation. The system auto-generates an annotated Python script that reproduces the margin calculation with inline comments explaining each step. This is the artifact an auditor or risk officer actually wants: a self-contained, readable script they can run independently.
Every extracted field traces to a source page in the original PDF. Every normalization decision carries a reasoning chain. Every calculation step is logged with its inputs and formula. This is an evidence chain, not a log file.
What Is the Technical Stack?
The codebase is split into a FastAPI backend and a React + TypeScript frontend, with persisted artifacts saved throughout the workflow.
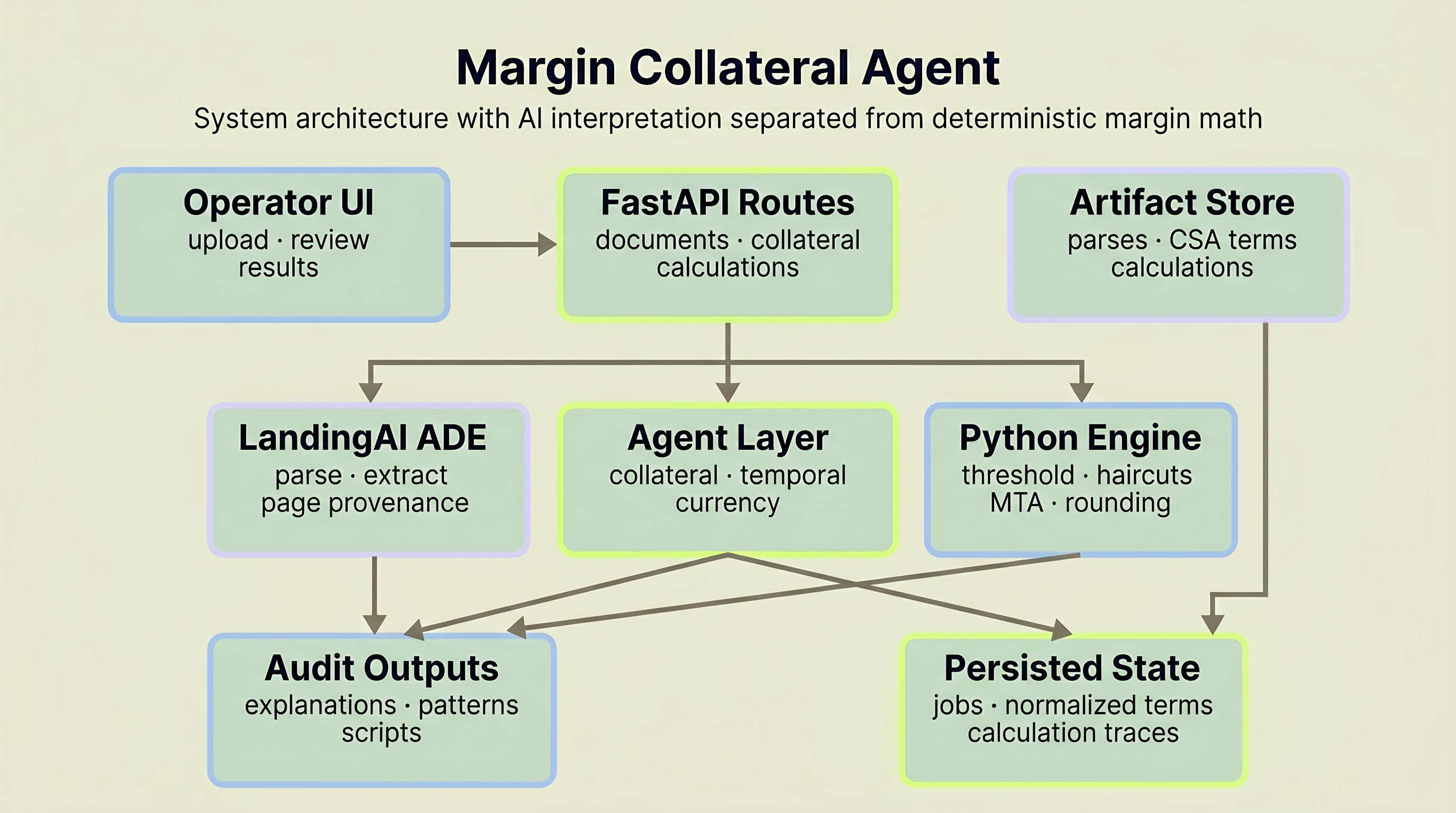
System architecture: React frontend → FastAPI routes → orchestration layer → LandingAI ADE + Claude agents → deterministic calculator → PostgreSQL persistence.
Backend. The FastAPI app exposes document-processing, collateral, calculation, export, formula-analysis, script-generation, and analytics routes. Typed Pydantic schemas define the contracts between stages, and the repo includes unit, integration, and benchmark tests.
AI layer. LandingAI ADE handles document parsing and schema-driven extraction. Anthropic Claude models handle multi-agent normalization, collateral matching, explanation generation, and clause-pattern analysis. The calculator stays deterministic and separate from those model calls.
Pipeline. Upload → parse → extract → normalize → map → calculate → explain. A background processing flow wraps the early document stages and exposes job polling. Artifacts are persisted along the way: parsed documents, extractions, normalized data, calculations, explanations, formula patterns, and generated audit scripts.
Frontend. The React frontend provides dashboard, extraction review, calculation input, and results pages. The results UI fetches explanations, formula patterns, exports, and generated audit scripts for operator review.
This project is not a full collateral platform. It is a working reference architecture for the CSA interpretation and margin-explanation layer that sits upstream of one. See the backend workflow example and API endpoint guide for the concrete route sequence.
Key Takeaways for Financial Operations Teams
- The problem is input quality, not calculation complexity. FMSB found 54% of disputes arose during exposure and margin calculation because of disagreements on inputs and models. Fix the inputs, and the downstream math becomes much easier to trust.
- Separate AI judgment from deterministic math. LLMs normalize messy contract language. Rules compute margin. Neither does the other's job.
- Auditability is an architecture decision, not an afterthought. Source provenance, reasoning chains, and generated audit scripts are built into the pipeline.
- The automation gap is operational, not hypothetical. ISDA's year-end 2024 data show both large margin volumes and a steady shift toward non-cash variation margin collateral. The manual approach does not get easier from here.
- The review bottleneck is interpretation, not arithmetic. Most time spent on CSA processing goes to reading collateral descriptions, resolving ambiguities, and matching posted collateral to eligible categories. Those are the steps this system automates with full reasoning transparency.
If you're evaluating LandingAI ADE for document-heavy financial workflows, this build shows how to turn manual CSA review into traceable, auditable margin calls your team can defend.
- Explore the build. Beemnet shipped the full prototype: source code on GitHub and demo video walking through the pipeline end to end.
- Talk to LandingAI. Scoping a treaty intake or contract management workflow? Feel free to email us to discuss applying the same extraction pattern to your documents.
Frequently Asked Questions
Can this handle multiple ISDA credit support annex formats?
The extraction schema targets standard ISDA CSA provisions: thresholds, MTAs, eligible collateral, haircuts, independent amounts, rounding, and party definitions. LandingAI ADE's published 99.16% DocVQA result reflects strong parsing fidelity (LandingAI, 2025), but real CSA performance depends on the agreement set and extraction schema. In this project, format variation is handled by the schema plus the downstream normalization layer, and every extracted field keeps provenance for review.
What happens when normalization confidence is low?
The validation agent flags low-confidence fields for human review. Each normalization agent returns a confidence score and reasoning chain. Since FMSB found that 54% of disputes arose during exposure and margin calculation because of disagreements on inputs and models (FMSB, 2025), catching uncertain fields before they reach the calculator matters. You can retrieve the full reasoning through a dedicated API endpoint and override the result before calculation.
Does the deterministic margin calculator support currencies beyond USD?
The current schema constrains the Currency model to USD. With cash as variation margin declining to 68.3% and non-cash collateral rising (ISDA, 2025), multi-currency support is a natural next step. It would require extending the schema and adding FX conversion logic to the calculator.
What external APIs does the system depend on?
Two: LandingAI ADE for document parsing and field extraction, and Anthropic Claude for normalization agents, collateral matching, explanation generation, and formula analysis. The margin calculation itself has zero external dependencies. It runs locally as pure Python.
How is this different from enterprise collateral management platforms?
Enterprise platforms manage the full collateral lifecycle: inventory, optimization, settlement, and reporting. The Margin Collateral Agent focuses on one specific bottleneck: turning CSA PDFs into structured, calculable margin outputs with audit trails. It's a workflow tool that sits upstream of those systems, not a replacement for them.