Document Pre-trained transformer-2

When we first launched Agentic Document Extraction (ADE), our focus was on breaking documents into agentic chunks: text, tables, figures. That was already a step forward from monolithic OCR, because it gave developers structured building blocks.
But in the real world, documents aren’t that simple. A financial report may include tables, signatures, stamps, and logos on the same page. An insurance claim might mix ID cards, checkboxes, and handwritten notes. A compliance filing could hide a QR code in a corner.
Until now, these elements often got lost or misclassified. Developers had to hack around outputs or write brittle regex rules.
With DPT-2, we’re introducing an expanded chunk ontology—a richer, more granular classification system that gives every document element its rightful place.
What’s in the Expanded Ontology
In addition to Text, Tables, and Figures, DPT-2 now detects:
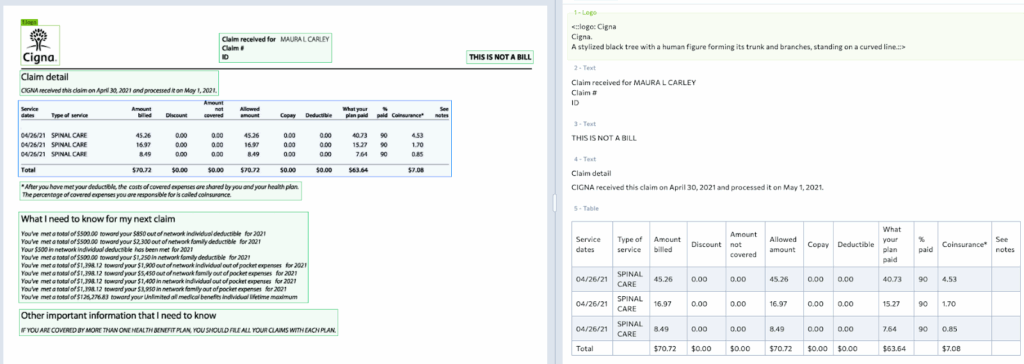
Attestations: Signatures (signed or not signed, including handwritten signature detection), stamps, seals
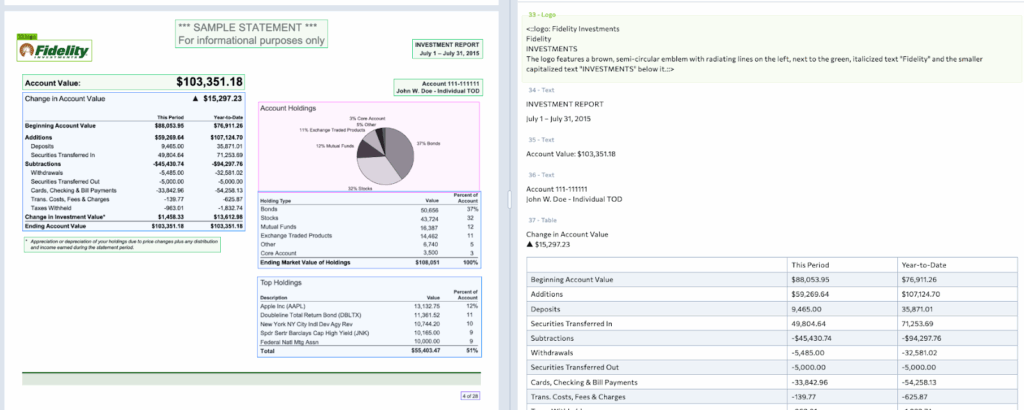
Logos: entity and brand marks
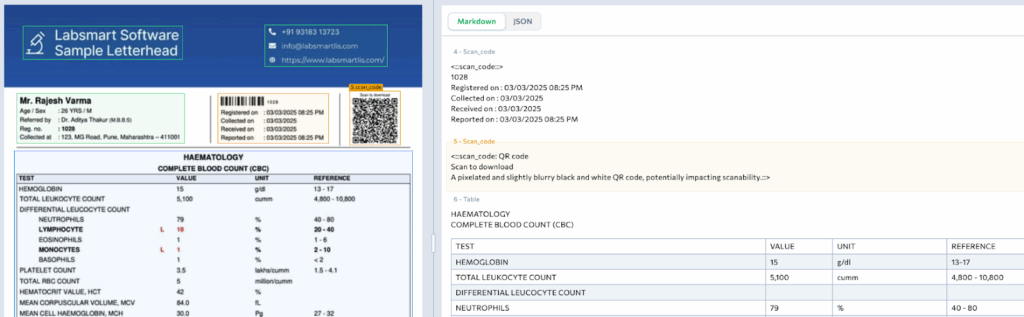
Scan Codes: Barcodes, QR codes, 2D codes
ID & Cards: Driver’s licenses, insurance cards, student IDs
Marginalia: Notes, annotations, side-comments
Each chunk type is tagged consistently, with structured metadata. This means your downstream systems can treat them differently, programmatically.
Why This Matters
Compliance and Trust****Regulatory filings, loan applications, and insurance claims often require attestations. By detecting signatures and seals explicitly, DPT-2 enables full audit trails.
Traceability****Scan codes and ID cards are often keys to joining documents across systems. DPT-2 recognizes them directly, so you can integrate document AI into broader workflows.
Cleaner Outputs****Logos are now captioned concisely (“Company logo: LandingAI”) instead of verbose descriptions. That keeps your structured output clean and usable.
Example
Consider a loan application package. It often includes bank statements, W-2 forms, tax returns, profit-and-loss statements, and ID cards—critical documents for risk assessment and accurate underwriting.
Sample page includes:
Applicant income/liability table
ID card scan
Signatures
With DPT-2:
Table → preserved structure + values
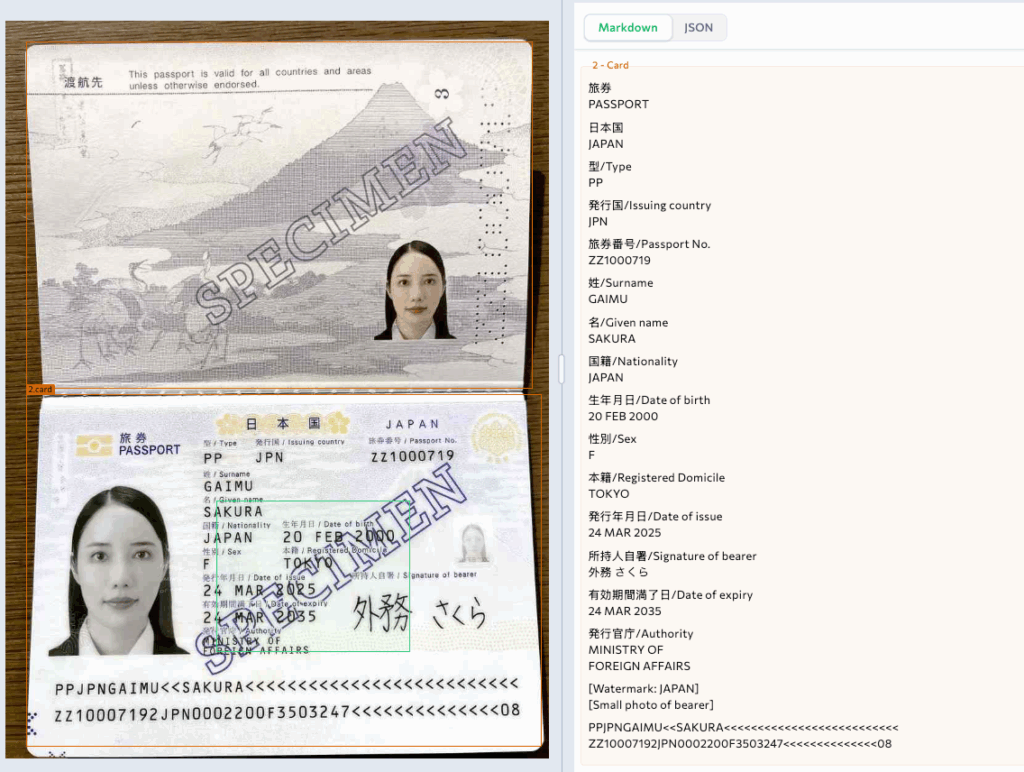
ID card → labeled chunk_type: id_card
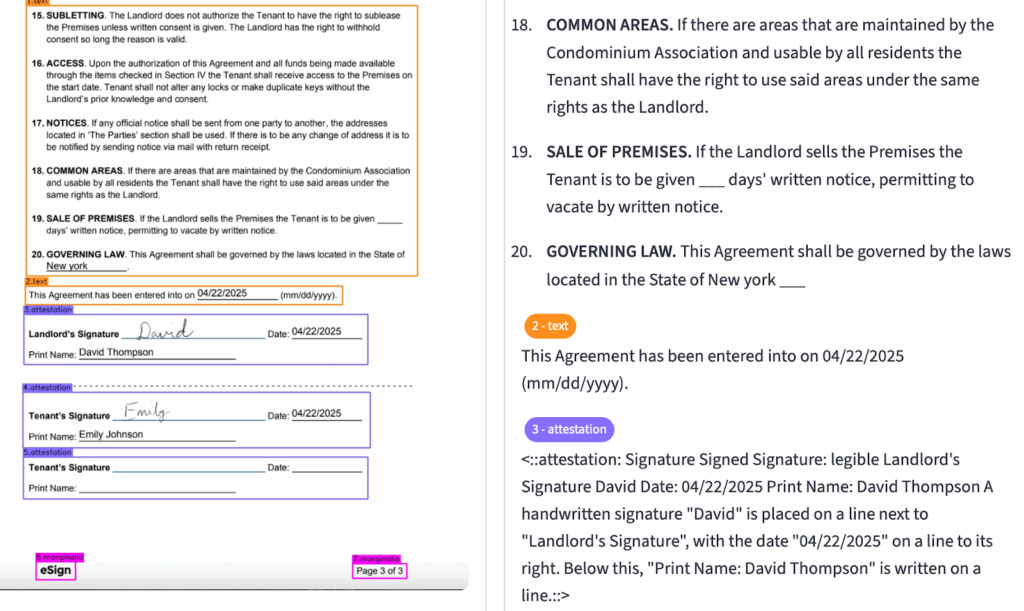
Signature → labeled chunk_type: attestation, handwritten signature “David”
This means your application pipeline can:
Populate the financial model (from the table)
Verify identity (from the ID card)
Confirm consent (from the signature)
Capture employment status (from the checkbox)
All automatically—and with full traceability back to the source document.
Expanded Chunk Ontology is available now in DPT-2—try it in the Playground or integrate it directly via API.
Start exploring DPT-2 with Expanded Chunk Ontology today.
Example Images
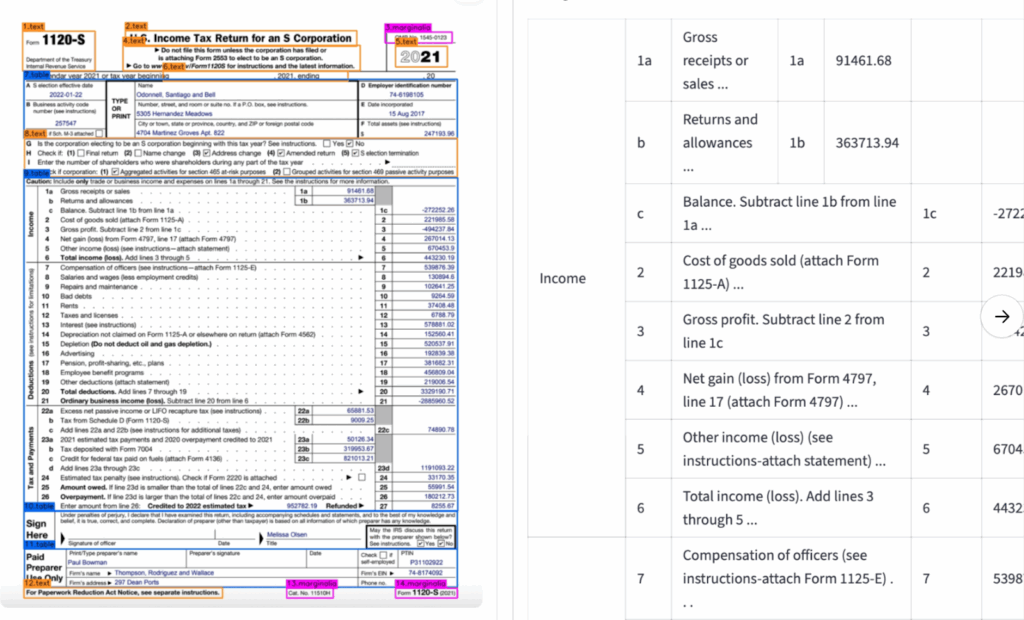
Examples showing tables, text and marginalia for complex documents:
Examples showing attestation chunk type:

Examples showing card chunk type:

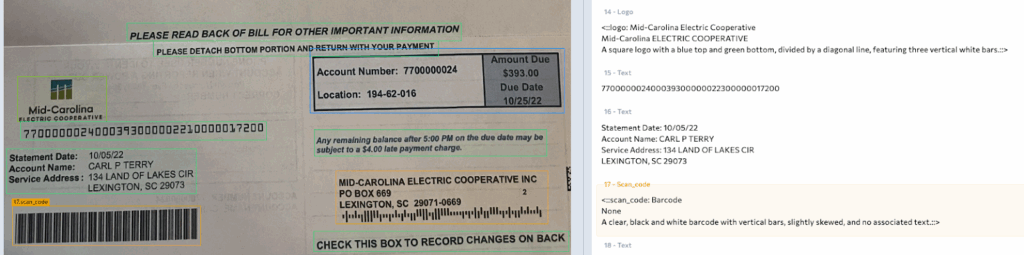
Examples showing scan_code chunk types:
Examples showing logo chunk types:
Get Started:
Test your document in the Playground
Ask questions in our community on Discord
Learn about compliance and security in our Trust Center and Security Page
Have questions about how your organization can use Agentic Document Extraction at scale? You can contact us with any questions.