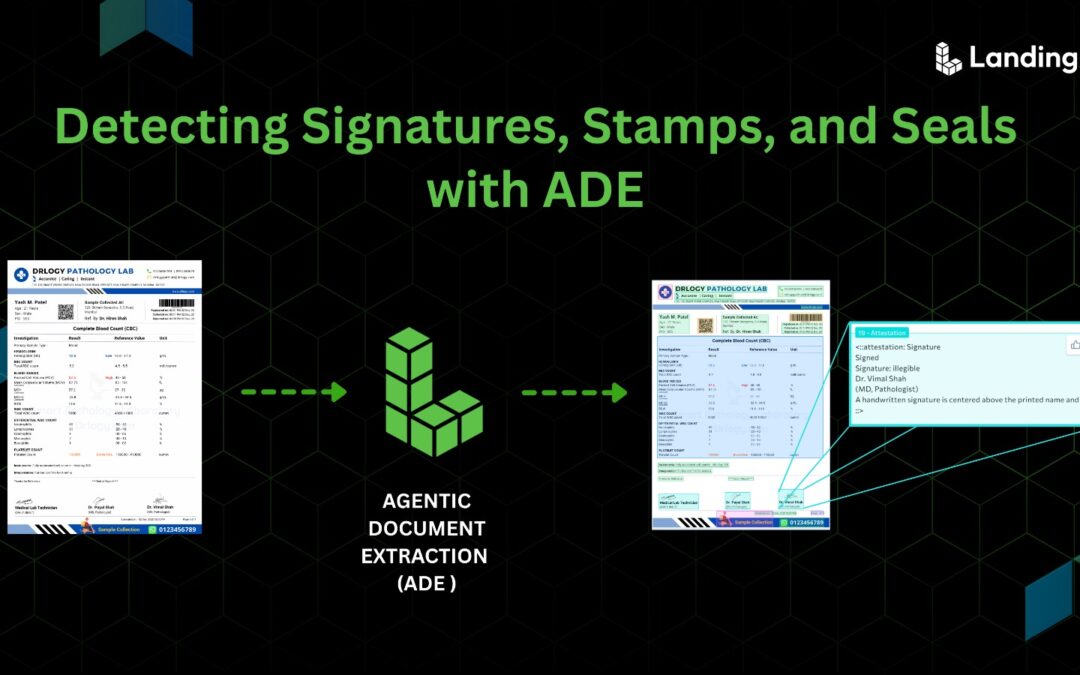
TL;DR Signatures, stamps, and seals are critical markers of authenticity in documents. Yet detecting these elements remains difficult because they vary widely in form, placement, and quality. Traditional OCR and template-based systems often fail to capture them...
Imagine your application needs to process data from a massive 1000-page contract or a 1-GB engineering report scanned into a single PDF. The upload completes, but now the parsing step grinds everything to a halt, blocking your app, slowing users down, and backing up...
Agentic Document Extraction (ADE) from LandingAI brings handwritten information into the digital world by converting essays, prescriptions, and centuries-old manuscripts into structured, searchable, and analyzable data. Designed to interpret documents the way...
Today we are sharing a powerful solution for a high-volume document extraction pipeline which lands data into Snowflake. Built specifically for Snowflake Data Engineers, the GitHub repo provides an end-to-end workflow which provides performance at scale:...
1. The Problem Ask an AI assistant to analyze a document, only to hear: “I can’t access external URLs or PDFs, please upload the file”? BTW, that dead-end isn’t random, it’s by design. LLMs run in a sandbox with no direct access to your filesystem or enterprise...