Reinsurance Document Extraction: Automating Treaty Intake with Human-in-the-Loop AI
From treaty PDF to approved contract record, with LandingAI Agentic Document Extraction

TL;DR
Reinsurance contracts arrive as dense PDFs. Operations teams retype dates, premium amounts, party names, and retention figures into management systems by hand. This manual intake burns time, injects errors into every downstream process, and pulls underwriters away from underwriting — they spend 40% of their time on administrative tasks instead of actual risk work (Accenture, 2022). Even a partial reduction in re-keying is operationally meaningful.
Re-Ink demonstrates a workflow pattern reinsurance ops teams can act on today: use LandingAI ADE as the document-processing intelligence layer to turn treaty PDFs into reviewable draft records, keep a human reviewer at the approval step, and wrap the extracted draft in application-specific business logic. The prototype accepts PDF or DOCX uploads, extracts contract details, financial terms, and core counterparties such as cedent and reinsurer names, then routes that payload to human review before anything is saved.
Re-Ink was built by Vineet Sarpal, Business Analyst at Sapiens and an active member of the LandingAI builder community, during the Financial AI Hackathon Championship 2025, on a stack of FastAPI, React, PostgreSQL, and LangGraph agents that assist reviewers during intake and support post-approval contract analysis. He also recorded an end-to-end demo that walks through the extraction workflow from upload to approved record.
What Re-Ink Was Built to Do
Re-Ink was built as a reference implementation for one narrow job: turn a reinsurance PDF or DOCX into a reviewable draft contract record. A user uploads a document, LandingAI parses and extracts targeted fields, and a reviewer edits or confirms the payload before anything is saved.
In practice, the workflow focuses on contract identifiers, dates, financial terms, and core counterparties such as cedent and reinsurer names. The value is not full autonomy. It is a prototype that makes a specific pain point concrete and shows how LandingAI's document-processing intelligence can replace a chunk of brittle manual intake work.
That narrower framing matters in a market that still runs heavily on documents. Reinsurance remains a $394.7 billion global market (Atlas Magazine, 2024), manual extraction from dense source documents can carry error rates above 6% even in disciplined research settings (Reisch et al., via PMC/NIH, 2024), and insurers still struggle to operationalize AI consistently. 82% of insurers believe AI will dominate operations, yet only 14% have fully integrated it (AutoRek 2026, via Insurance Business Magazine). The gap is not just model quality. It is workflow.
The write-up stays focused on that workflow: the pain point behind the prototype, how LandingAI fits into the extraction path, what the prototype extracts today, and why human review stays in the loop.
Why Reinsurance Document Extraction Still Fails at Scale
The prototype targets the most fragile part of reinsurance intake: manual re-keying from dense treaty documents into contract systems. Analysts still pull dates, premium terms, retention figures, and counterparties out of long PDFs by hand, and every downstream workflow inherits whatever gets entered on that first pass.
Actual Re-Ink application screenshot from the repository
A typical quota share treaty shows why this breaks down. The document may specify a cedent, one or more reinsurers, possibly a broker, effective and expiration dates, premium and commission percentages, retention limits, and coverage territories. An analyst has to identify each data point and key it into the system, often under renewal-season time pressure.
That manual step is expensive. Insurers spend 14% of their operational budgets fixing errors from manual processes (AutoRek 2026, via Insurance Business Magazine). The failure modes are predictable: date formats vary across jurisdictions, party names appear in different forms throughout the same document, and financial terms use inconsistent notation.
The problem isn't that people make mistakes. It's that the volume and complexity of reinsurance documents makes perfect manual extraction statistically impossible at scale. Even small per-field error rates compound fast across thousands of data points per treaty season.
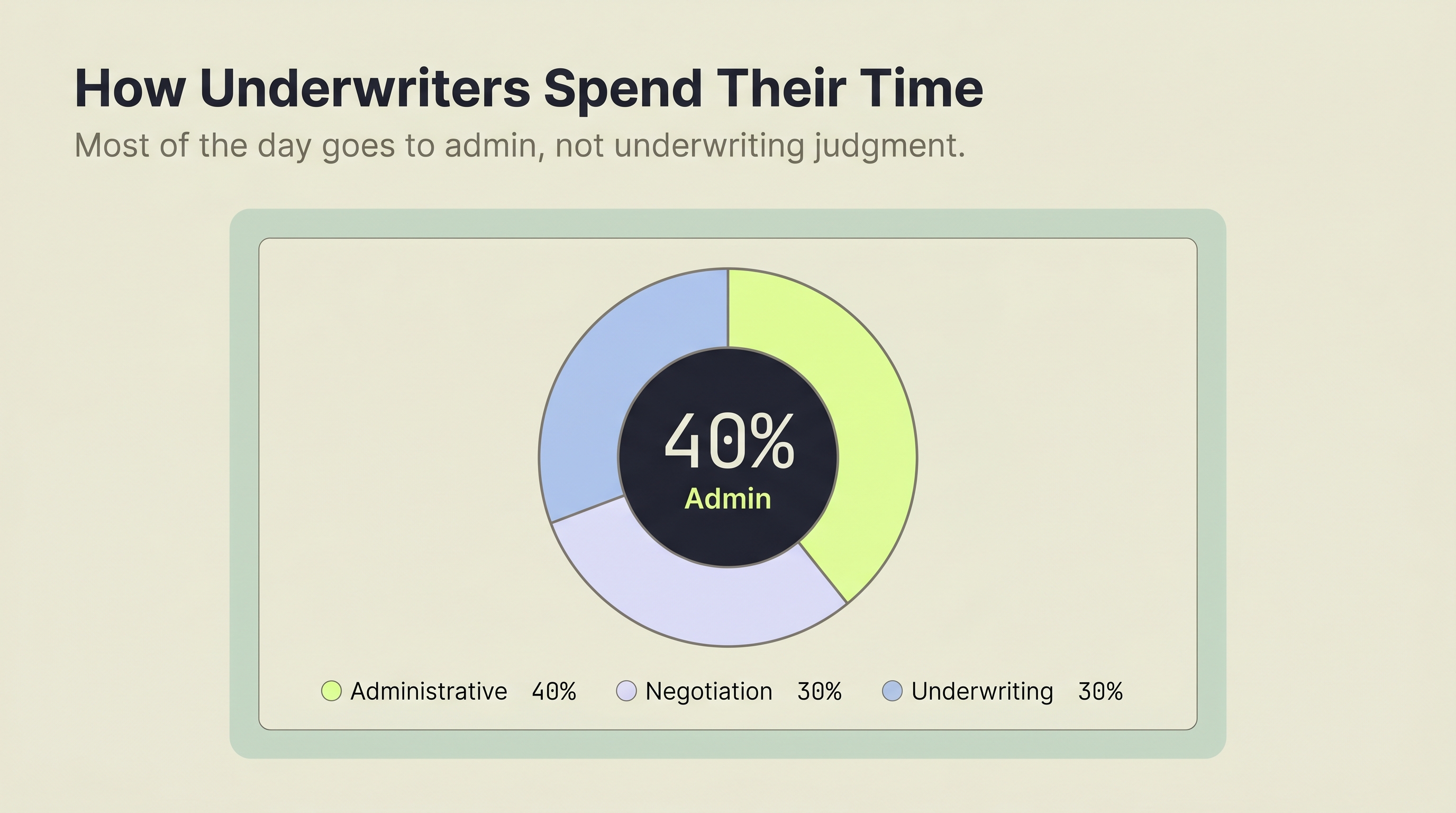
Source: Accenture P&C Underwriting Survey, 2022
According to Accenture's P&C Underwriting Survey, underwriters spend just 30% of their time on actual underwriting, with 40% consumed by administrative tasks and another 30% on negotiation and sales support (Accenture, 2022). Reinsurance document extraction automates the administrative slice so underwriters can focus on risk assessment and relationship management.
How LandingAI Fits Into the Workflow
LandingAI ADE is the document-processing intelligence layer in this prototype. Instead of treating the upload as raw OCR text and then hand-building regex or template logic around it, Re-Ink uses LandingAI's two-step parse-and-extract flow to turn long treaty documents into reviewable draft data.

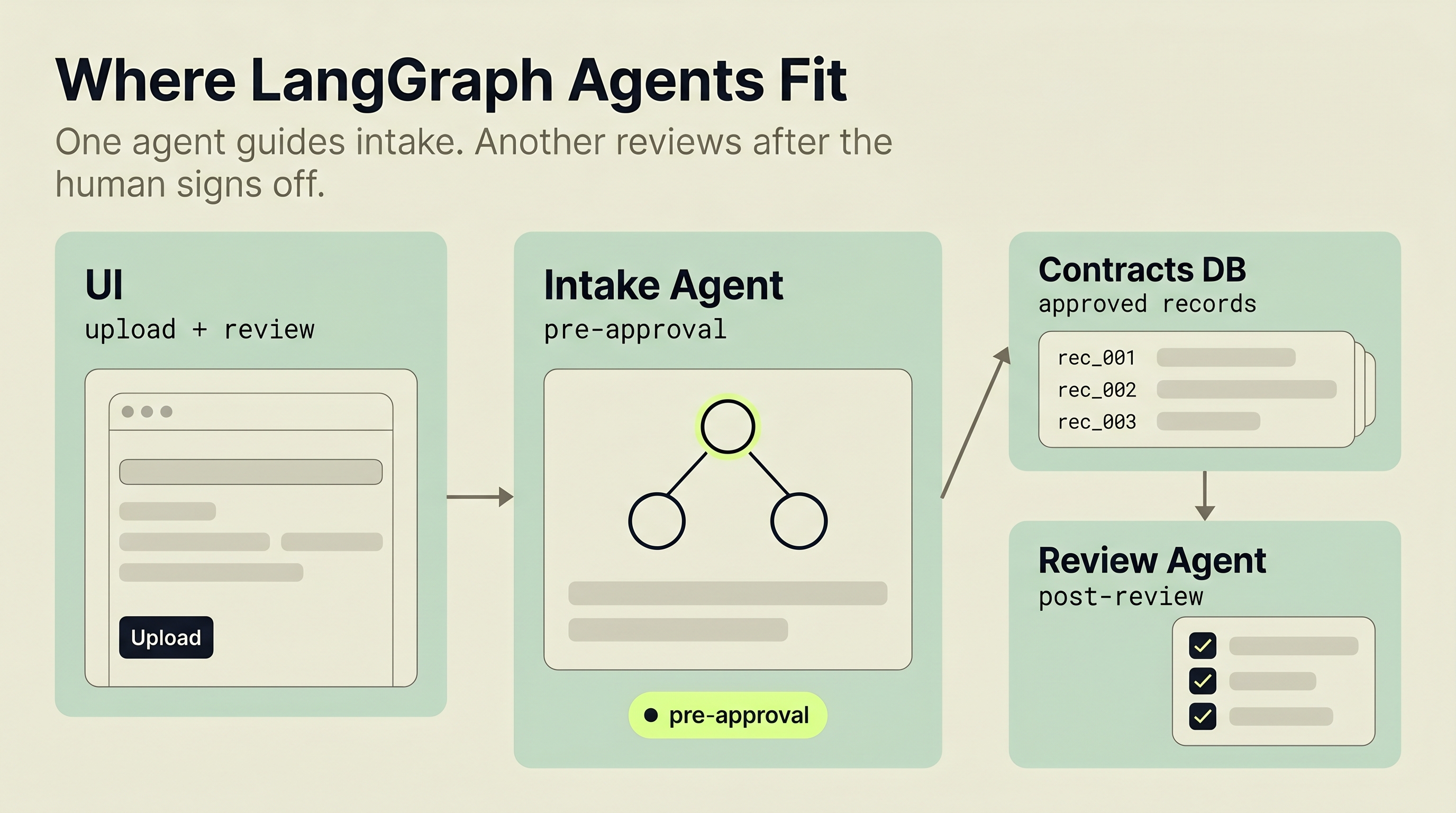
Repo-grounded workflow diagram based on the implemented extraction path
Re-Ink uses LandingAI's agentic document extraction, which goes beyond basic OCR. For enterprise teams, the practical value is less custom document plumbing. For developers, the practical value is less time spent maintaining brittle extraction rules. The pipeline has two stages:
Parse stage. LandingAI's document parser (dpt-2-latest model) reads the uploaded PDF or DOCX and identifies the document structure: sections, tables, headers, paragraphs, and embedded data.
Extract stage. The extraction model (extract-latest) pulls specific fields from the parsed structure based on a predefined schema. Re-Ink's schema targets contract identification, dates, financial terms, coverage details, and party information.
The output is structured JSON that can be reviewed and transformed into Re-Ink's database models. In other words, no regex patterns and no template matching. The extraction model understands document context, so it can identify a "retention amount" whether the treaty labels it "Net Retention," "Ceding Company Retention," or buries it in a paragraph.
Prototype finding: During hackathon testing with SEC EDGAR-sourced reinsurance filings, Re-Ink's extraction pipeline was most reliable at pulling core counterparty information such as cedent and reinsurer names even when those entities appeared in narrative treaty language rather than neatly labeled tables.
This type of schema-first workflow is part of a larger intelligent document processing push. The market reached $3.22 billion in 2025, with banking, financial services, and insurance making up roughly 40% of it (Precedence Research, 2025). Reinsurance is a useful prototype domain because the documents are long, repetitive, financially material, and still heavily manual.
What Re-Ink Extracts Today
The current extraction flow focuses on the fields operations teams need first, not every possible treaty nuance. That boundary is useful for enterprise teams scoping where ROI may appear first and for developers deciding where human review still needs to fill gaps. In practice, the prototype covers contract identifiers, core dates, financial terms, and key counterparties.
Contract identification: contract number, contract name, contract type, and related classification fields. The contract number serves as a unique key to prevent duplicate ingestion.
Dates: effective date and expiration date, with room for reviewers to confirm additional dates such as inception date when available. These dates control downstream processes such as coverage activation and renewal timing.
Financial terms: premium, currency, limits, retention, commission, and related coverage fields. Some values are mapped directly during post-processing, while others are best treated as reviewable draft data before approval. A single miskeyed decimal in a commission rate can propagate into every settlement calculation.
Party extraction: today the extraction flow is strongest on core counterparties, especially cedent and reinsurer names. Reviewers can then edit party details, classify party type, and add missing parties before saving.
The underlying data model includes a contract_parties association table for contract-to-party links, which keeps the system ready for richer role-on-contract handling as the workflow evolves.
The extraction runs asynchronously. When a user uploads a document, Re-Ink creates an extraction job, returns a job ID, and the frontend polls Re-Ink's status endpoint until results are ready. The ExtractionStatus component updates as processing moves forward. No page refreshes, no waiting on a loading screen with no feedback.
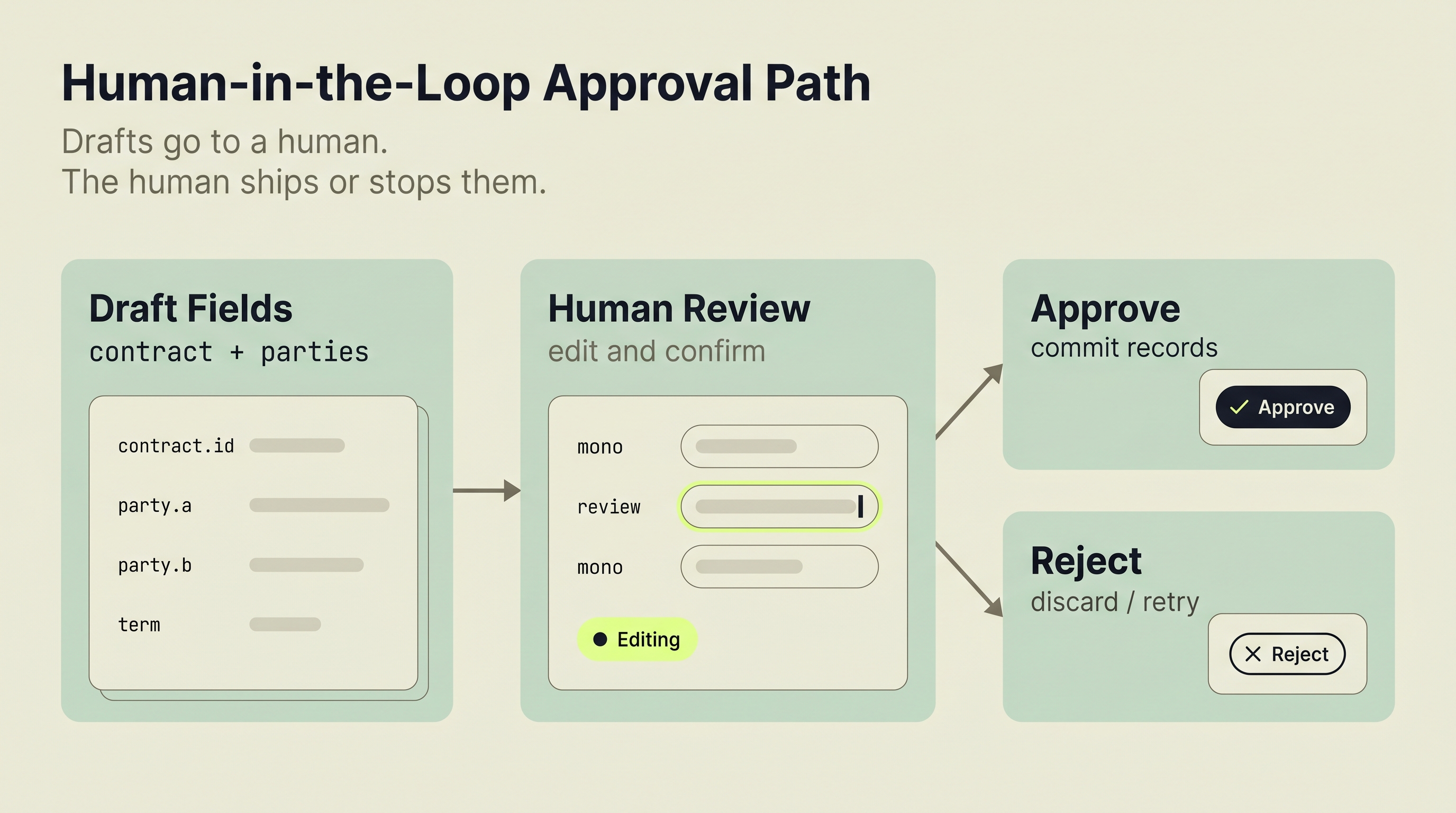
Why Human Review Stays in the Loop
Human review is the control point in Re-Ink. Nothing is persisted until a reviewer confirms or corrects the draft payload.
For enterprise readers, this is the operational safeguard that makes extraction usable in a real intake flow. For developers, it is the place where model output becomes application data rather than just another intermediate result.
Review is the control point: nothing is persisted until a human approves the draft payload
Re-Ink's review workflow puts extracted data in front of a human before any record hits the database. After extraction completes, the ReviewForm component displays the fields the AI pulled from the document: contract terms, dates, financials, and party details. The reviewer can edit any field, correct party types, add missing information, or reject the extraction entirely.
This isn't a trust problem, though. It's a regulatory and operational reality. Reinsurance contracts carry financial obligations measured in millions. A cedent's retention limit or a reinsurer's participation percentage must be verified against the original document by someone who understands the business context. No regulator accepts "the AI said so" as a compliance defense.
Implementation note: Re-Ink's approval endpoint (
POST /api/review/approve) creates Contract and Party records in a single transaction. If any part of the approval fails (duplicate contract number, invalid party data), the entire transaction rolls back. The reviewer's corrections are what enter the database, not the raw extraction output.
Beyond accuracy, the review step also creates a feedback loop. When reviewers consistently correct the same type of extraction error, that pattern signals where the extraction schema or prompt needs adjustment. Full automation skips this signal entirely.
This middle path matters beyond one prototype. 90% of insurance executives acknowledge the urgency of reinventing workforce strategies for human-AI collaboration, but only 25% have taken concrete steps (Deloitte, 2026). The gap often comes from an all-or-nothing framing: either automate completely or keep every task manual.
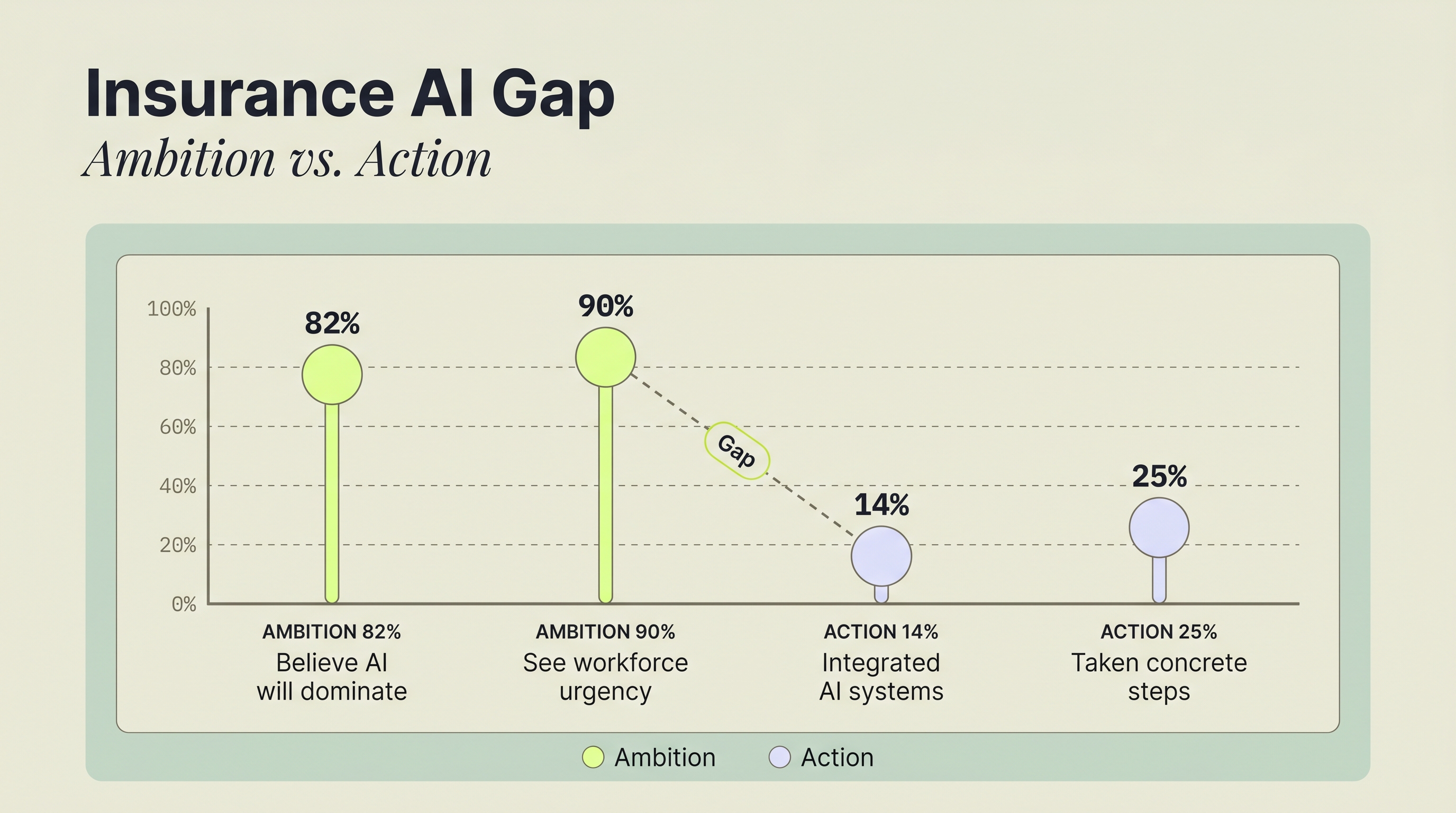
Source: AutoRek 2026 / Deloitte 2026 Global Insurance Outlook
How Agents Support Review
Re-Ink uses agents to support review, not to replace extraction or approval. In this prototype, LandingAI handles document understanding, while the agent layer wraps business-specific review behavior around the extracted draft.
Guided intake agent. This agent analyzes the extraction results for a given job and surfaces issues before the reviewer sees the data. It checks for missing required fields, flags inconsistencies (like an expiration date before the effective date), and generates a suggested review payload. The reviewer gets a pre-filled form with warnings attached, not a raw data dump.
Automated contract review agent. After a contract is approved and stored, this agent runs a compliance-focused analysis. It uses a LangGraph StateGraph with two nodes: validate (checks that the contract exists and has complete data) and analyse (sends the contract snapshot to an LLM for risk assessment and compliance flagging). The analysis returns a structured ContractReviewAnalysis with a summary, identified risks, and recommended actions.
Importantly, both agents support an offline mode (AGENT_OFFLINE_MODE=true). In offline mode, agents return deterministic mock responses instead of calling OpenAI. This lets the prototype run the full workflow during development and testing without burning API credits, and it's how the automated test suite validates the end-to-end flow.
More broadly, this kind of review assistance is part of the larger insurance AI opportunity. McKinsey estimates generative AI could unlock $50 to $70 billion in additional insurance revenue, with major gains in customer operations and software engineering workflows (McKinsey, 2026).
The agent architecture separates concerns cleanly. The extraction pipeline (LandingAI) handles document understanding. The LangGraph agents handle business logic and compliance. The human reviewer makes the final call. Each layer adds value without duplicating the others.
The repo uses one agent before approval and another after a contract has already been stored
How the System Is Built
The architecture is intentionally straightforward because the goal is legibility, not platform theater. FastAPI handles APIs and services, React handles upload and review state, PostgreSQL stores approved records, and LandingAI plus LangGraph provide extraction and review assistance.
Backend (FastAPI + Python). The API layer uses thin route handlers organized by resource: documents, contracts, parties, review, and agents. Business logic lives in the service layer. The LandingAIService handles extraction API calls. The AgentService orchestrates LangChain agents. An in-memory job tracker keeps extraction state during processing.
Frontend (React + TypeScript). React Query manages server state with automatic cache invalidation after mutations. Zod validates form inputs client-side before submission. The UploadPage component orchestrates the full workflow: file upload, extraction status polling, and review form rendering in a single page without navigation interrupts.
Database (PostgreSQL + SQLAlchemy). Contract and Party models are linked through a many-to-many association table. Pydantic schemas enforce validation at the API boundary. The database URL auto-converts to psycopg 3.x format at startup.
Extraction pipeline. Upload hits POST /api/documents/upload. The service saves the file, submits it to LandingAI, and returns a job ID. The frontend polls GET /api/documents/status/{job_id} until completion. Results come back from GET /api/documents/results/{job_id} as structured JSON matching the extraction schema.
The full demo walks through this pipeline end to end, from PDF upload to approved contract record. The source code is on GitHub.
That architecture also lines up with where the market is going. Digital reinsurance transactions through ACORD's ADEPT platform grew 73% from 2024 to 2025 and over 300% since 2023 (Insurance Business Magazine, 2025), which suggests the industry is increasingly ready for structured digital workflows.
What's Next for Reinsurance Document Workflows
Re-Ink's answer to manual treaty re-keying is a workflow pattern: ADE for parsing and schema-based extraction, then a human reviewer between draft output and stored record.
For enterprise teams, document AI becomes valuable when it is attached to a real workflow boundary — intake, review, approval, persistence — and LandingAI ADE removes most of the brittle document-understanding work that would otherwise stall the project in OCR cleanup and template maintenance.
The broader industry case supports this direction. 82% of insurers believe AI will define operations, but only 14% have integrated it into financial workflows, and digital reinsurance transactions on ACORD's ADEPT platform grew 73% from 2024 to 2025 and more than 300% since 2023 (AutoRek 2026, via Insurance Business Magazine; Insurance Business Magazine, 2025). As structured digital transactions become more common, this kind of DPI-backed intake pattern looks more actionable than abstract AI ambition.
- Explore the build. Vineet shipped the full prototype: source code on GitHub, demo video, and a live deployment you can try.
- Talk to LandingAI. Scoping a treaty intake or contract management workflow? Feel free to email us to discuss applying the same extraction pattern to your documents.
Frequently Asked Questions
What file formats does Re-Ink support for reinsurance document extraction?
Re-Ink accepts PDF and DOCX files up to 50 MB. In a $394.7 billion reinsurance market (Atlas Magazine, 2024), most treaties still circulate as PDFs. The DocumentService validates file type and size before submission to LandingAI's extraction pipeline. Sample treaty documents sourced from SEC EDGAR filings are included in the repository for testing.
Can Re-Ink extract party roles from treaty documents?
Partially. With manual extraction from dense documents producing measurable error rates (Reisch et al., via PMC/NIH, 2024), even extracting core party information can reduce misidentification risk. Today Re-Ink is strongest at pulling cedent and reinsurer names from treaty documents. Reviewers can then edit party type, add missing brokers, and confirm associations before approval.
Does the system work without an internet connection?
Partially. Document extraction requires LandingAI's cloud API, since the intelligent document processing market ($3.22 billion in 2025, per Precedence Research) relies on cloud-based models. However, the LangGraph agents support an offline mode (AGENT_OFFLINE_MODE=true) that returns deterministic mock responses, enabling development and demo workflows without external API dependencies.
How does Re-Ink handle extraction errors or incomplete data?
Re-Ink's human-in-the-loop review step catches extraction gaps before they become costly. Reviewers can edit any field, add missing data, or reject the extraction entirely. The guided intake agent also pre-screens results and flags missing required fields. Approval creates records in a single database transaction that rolls back if any validation fails. That matters because insurers spend 14% of operational budgets fixing manual process errors (AutoRek 2026, via Insurance Business Magazine).
What reinsurance contract types can Re-Ink process?
Re-Ink is designed for reinsurance agreements such as treaty and facultative contracts, including common structures like quota share and excess of loss. The extraction model reads documents contextually rather than matching rigid templates, which helps it cope with varying layouts and terminology. The prototype was tested against treaty excerpts from public SEC EDGAR filings during development, with reviewer confirmation still serving as the final quality gate.