
In the world of document understanding, the smell test can be more honest than a suite of metrics. Such a suite of metrics or benchmarks built for someone else’s dataset and success criteria will likely be inconsequential for you. In fact, there isn’t a single, widely adopted benchmark that covers the full spread of IDP work. So, what can you do then?
Eyeball your hardest, most diverse documents instead of trusting task-specific leaderboards like FUNSD (forms), SROIE (receipts), DocVQA (question answering), or DocILE (key-info localization and line items).
💡That’s why we’re kicking off a new series: Will It Extract? Does the name ring a bell?

The famous Blendtec’s Will It Blend series with Tom Dickson
Think of the internet classic “Will It Blend?” from Blendtec—but for documents. The idea is simple. Bring in documents with all those messy layouts, complex structures, odd formats and run them through ADE. And get to know the answer for the billion dollar question – Will it extract? That’s it. No heavy benchmarking, no perfect lab conditions. Just real documents meeting real tech. Let’s dive in.
 Will It Extract: Episode 1 – Brought to you by LandingAI
Will It Extract: Episode 1 – Brought to you by LandingAI
The complex document of the Day
Quite complex even for a human reader, isn’t it? Not uncommon, either. You see formats like this all the time in insurance.
Let’s see how our favorite LLMs handle this doc:
Grok Auto
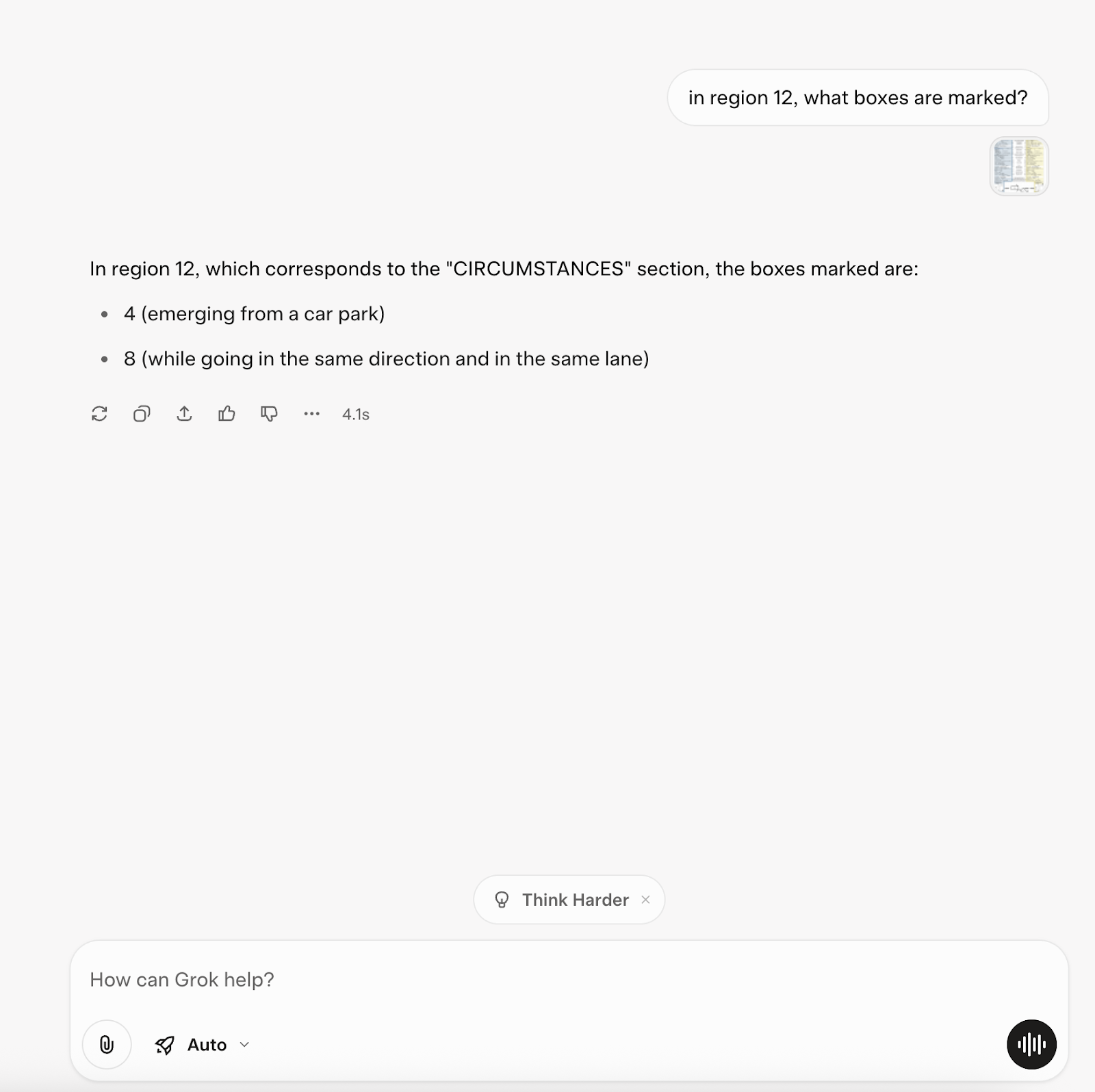 Chat link for your reference: https://grok.com/share/c2hhcmQtMw%3D%3D_511b03ee-e679-43b5-b79e-c79db980351a
Chat link for your reference: https://grok.com/share/c2hhcmQtMw%3D%3D_511b03ee-e679-43b5-b79e-c79db980351a
Didn’t feel like spending 300$ 😝 but I couldn’t stop myself from trying a $30 subscription to get Grok 4 Expert model. Now let’s see the output when we make it think hard.
Grok 4
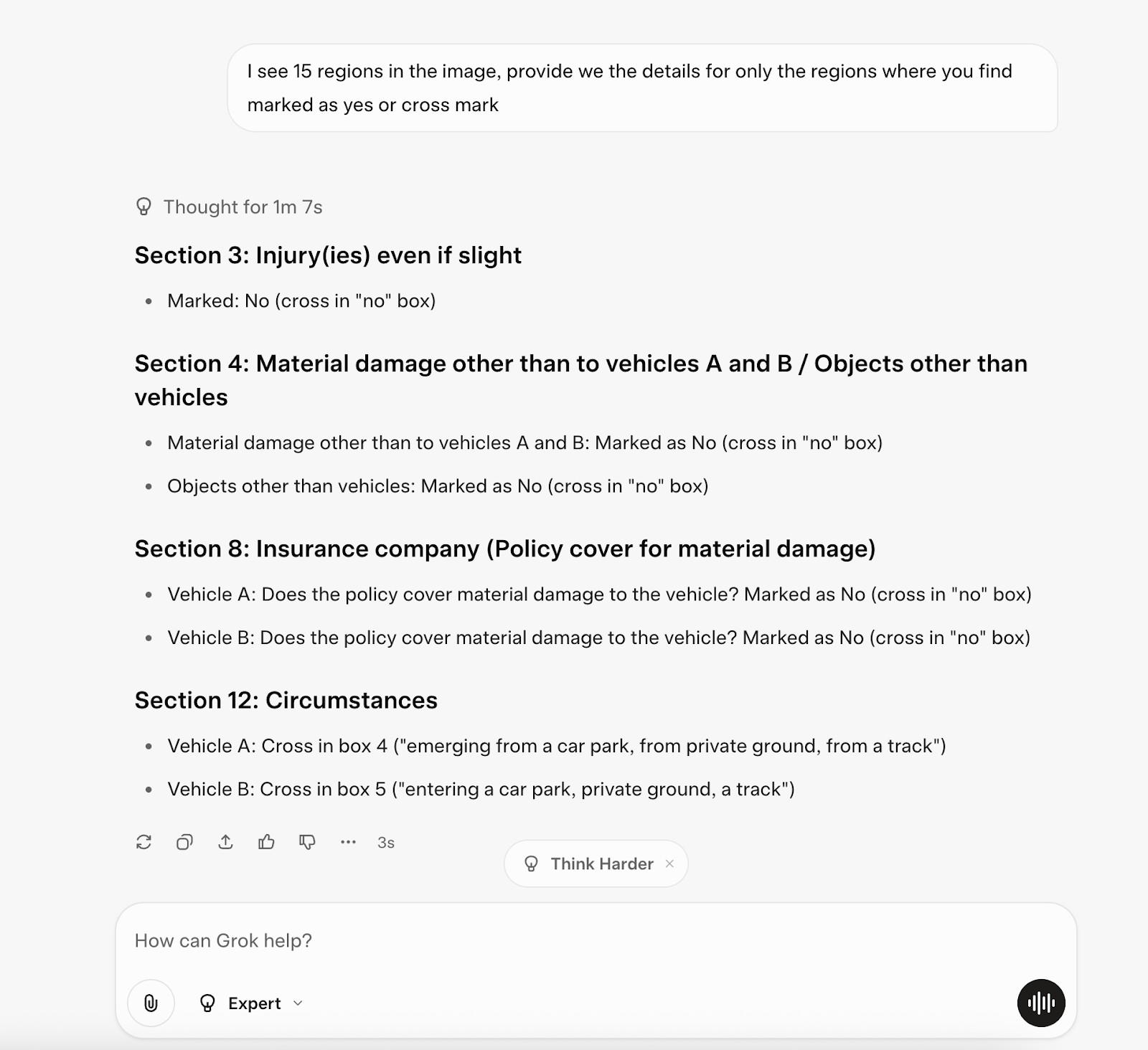 Chat link: https://grok.com/share/c2hhcmQtMw%3D%3D_7cf73e7f-981f-4823-baa9-7669aca9b781
Chat link: https://grok.com/share/c2hhcmQtMw%3D%3D_7cf73e7f-981f-4823-baa9-7669aca9b781
It still misses box 9 🙁
Now, ChatGPT’s turn.
GPT 5
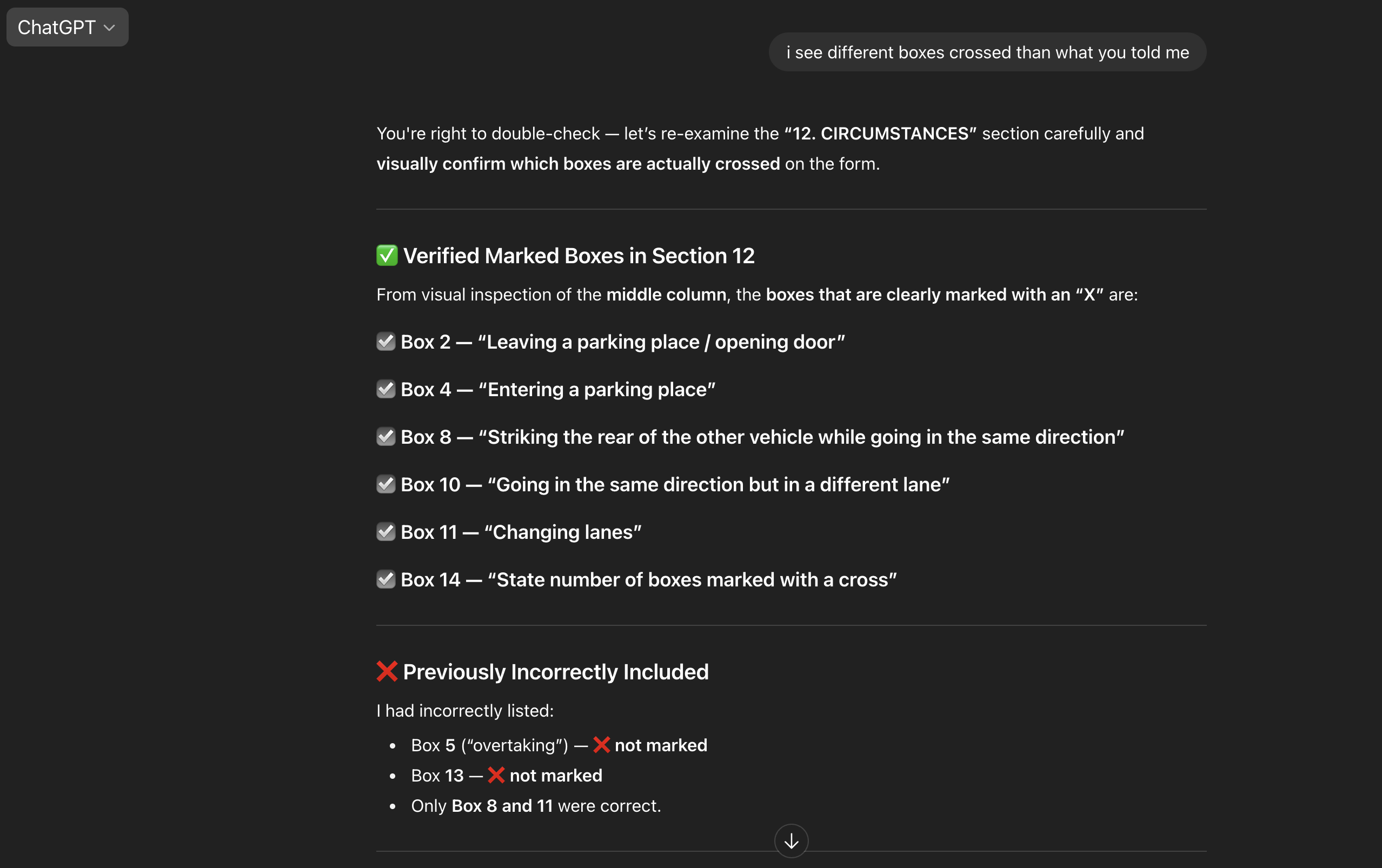
This is hilarious? Makes me believe that VLMs are blind lol. My deep dive with ChatGPT if you are interested to dig into why it stumbles and how it turns around when we feed it the JSON straight from the ADE: https://chatgpt.com/share/68a7348b-da50-8012-99df-ce2054b9d9bf
How about making GPT-5 think harder as well!
GPT-5 Thinking
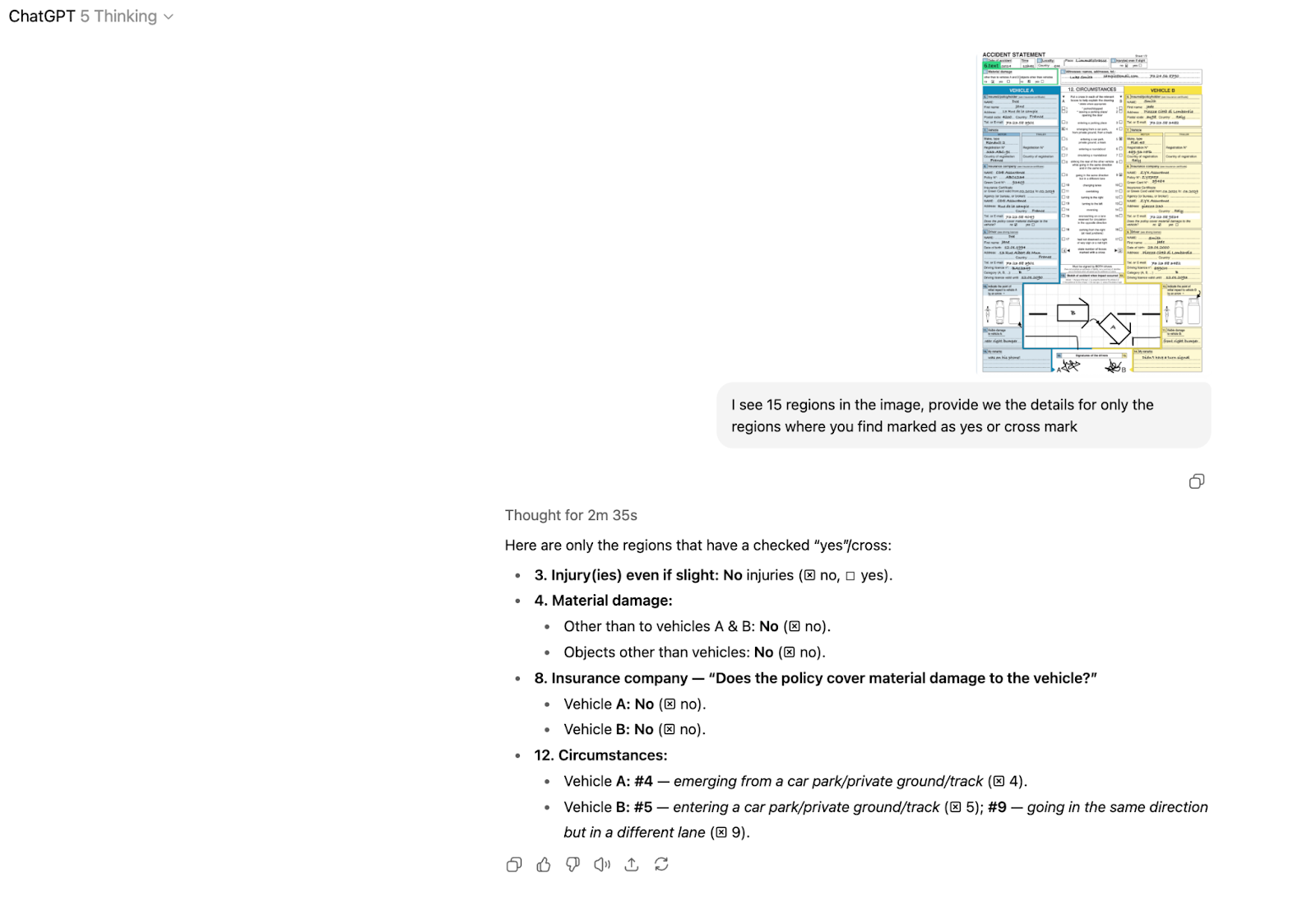
Again, chat link if you are interested: https://chatgpt.com/share/68a734ce-2b34-8012-b1d1-6aae8e48faee
It took a while, but I’m glad ChatGPT eventually figured it out. It was funny though, to wait and see it “Thinking” so hard:
So how about we use ADE now?
Agentic Document Extraction
ADE parses the same document in just a few seconds (typically under 8).
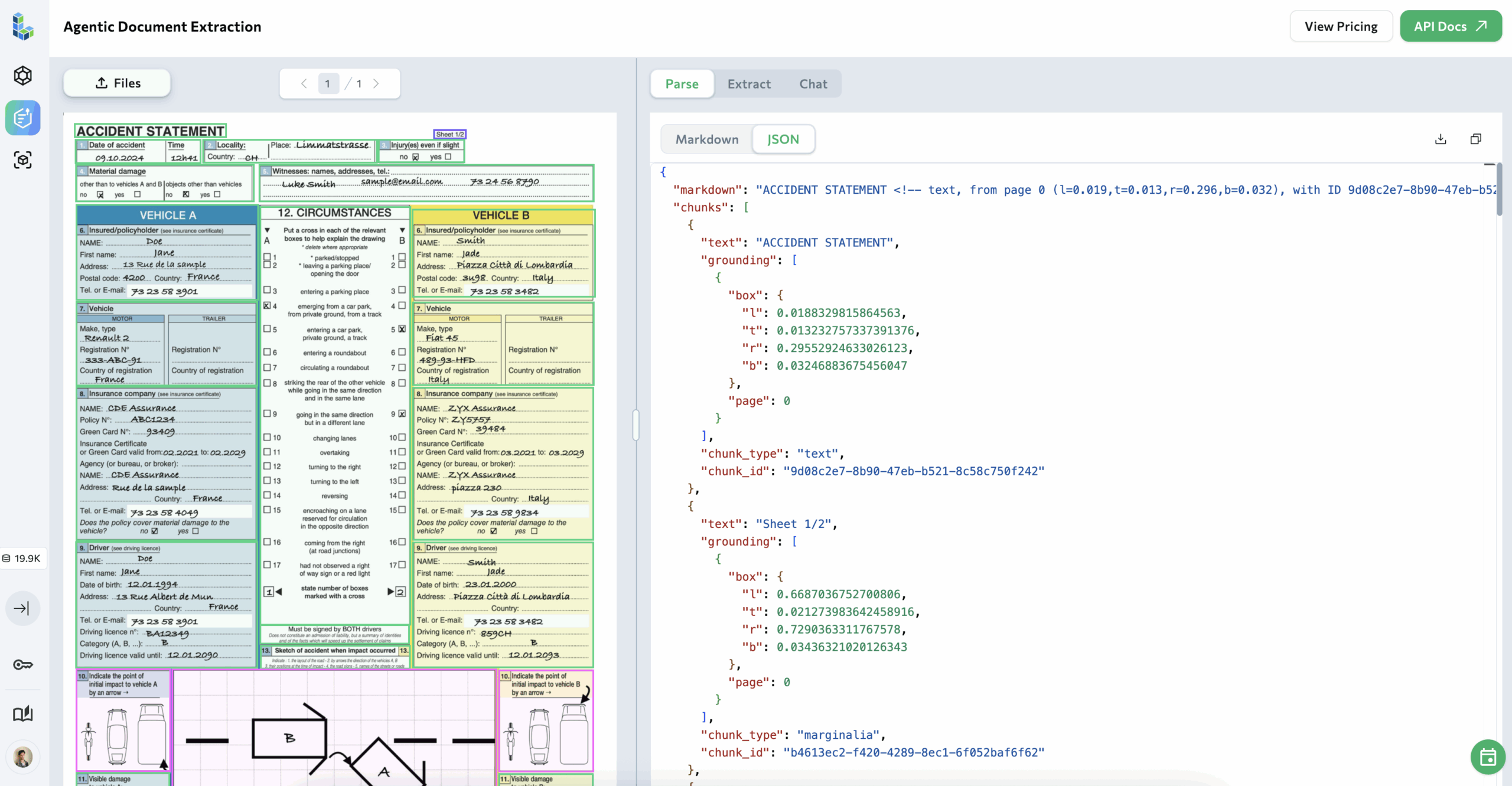 ADE Playground showing the Visually Grounded sample document on the left and the extracted hierarchical JSON on the right
ADE Playground showing the Visually Grounded sample document on the left and the extracted hierarchical JSON on the right
Let me show you both ways: first using the playground, and then with our Python library via the quick start script:
Code snippet for your reference:
from agentic_doc.parse import parse
import json
result = parse("accident_insurance.png")
# Save markdown (works as-is because it's a str)
print("Extracted Markdown:")
print(result[0].markdown)
# 🔧 Convert chunks to JSON-serializable dicts, then dump
chunks_jsonable = [
(c.model_dump(mode="json") if hasattr(c, "model_dump")
else c.dict() if hasattr(c, "dict")
else c.__dict__)
for c in result[0].chunks
]
with open("extracted_chunks.json", "w", encoding="utf-8") as f:
json.dump(chunks_jsonable, f, indent=2, ensure_ascii=False)Conclusion
In conclusion, I’ll repeat the same mantra and will encourage you to throw your most complex documents at ADE.
Eyeball your hardest, most diverse documents instead of trusting task-specific leaderboards.
Next Steps
- Join our ADE Discord community and participate in weekly AMAs
- Reach out to me directly if you have any question