AI Credit Memo Generator: A Hackathon Underwriting Prototype
Siva and Trinh Pham
TL;DR
- The pain point is real: analysts lose time to document gathering, spreading, and memo assembly before they can do actual credit judgment.
- The prototype proves a practical pattern: extract document data, calculate ratios, retrieve context, and draft a memo for human review.
- The clearest LandingAI value in this workflow is at the document-processing layer, where unstructured files become structured financial fields the rest of the system can trust.
- Siva built this as a hackathon prototype to test where AI can remove friction from credit memo preparation.
At a glance: the takeaway is not "AI replaces underwriting." It's that a prototype can expose where document-processing automation removes friction in a real enterprise workflow.
What the prototype made clear is simple: in document-heavy workflows like underwriting, the first bottleneck worth solving is usually not memo writing. It's document processing. If teams can turn messy PDFs and Word files into structured, reviewable fields, the rest of the pipeline becomes testable.
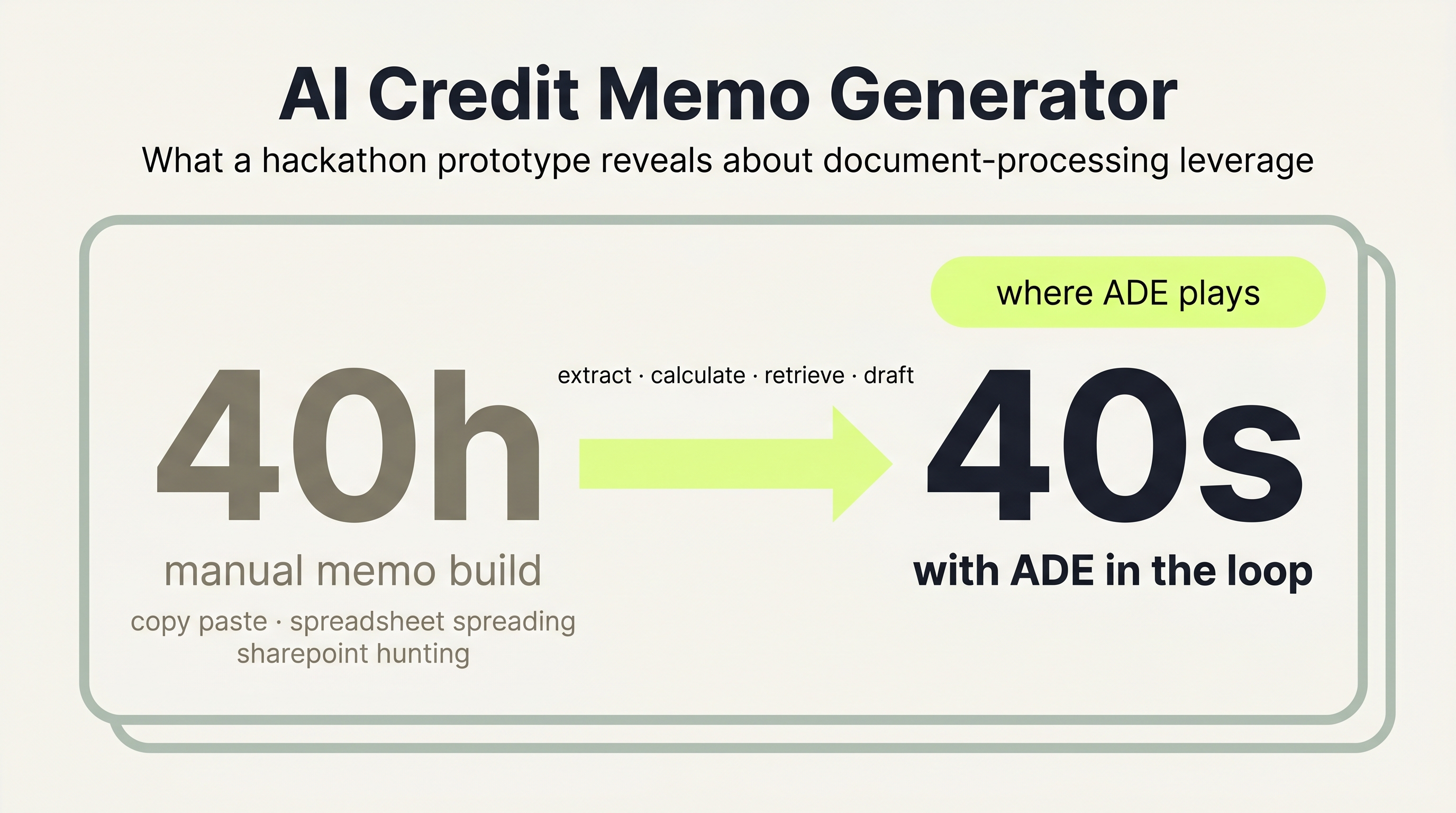
Credit memo preparation is one of commercial lending's biggest time sinks. A single memo can take 40 hours of manual work: copy-paste, spreadsheet spreading, and SharePoint hunting, all before any real judgment happens. That's time spent on data assembly, not credit analysis.
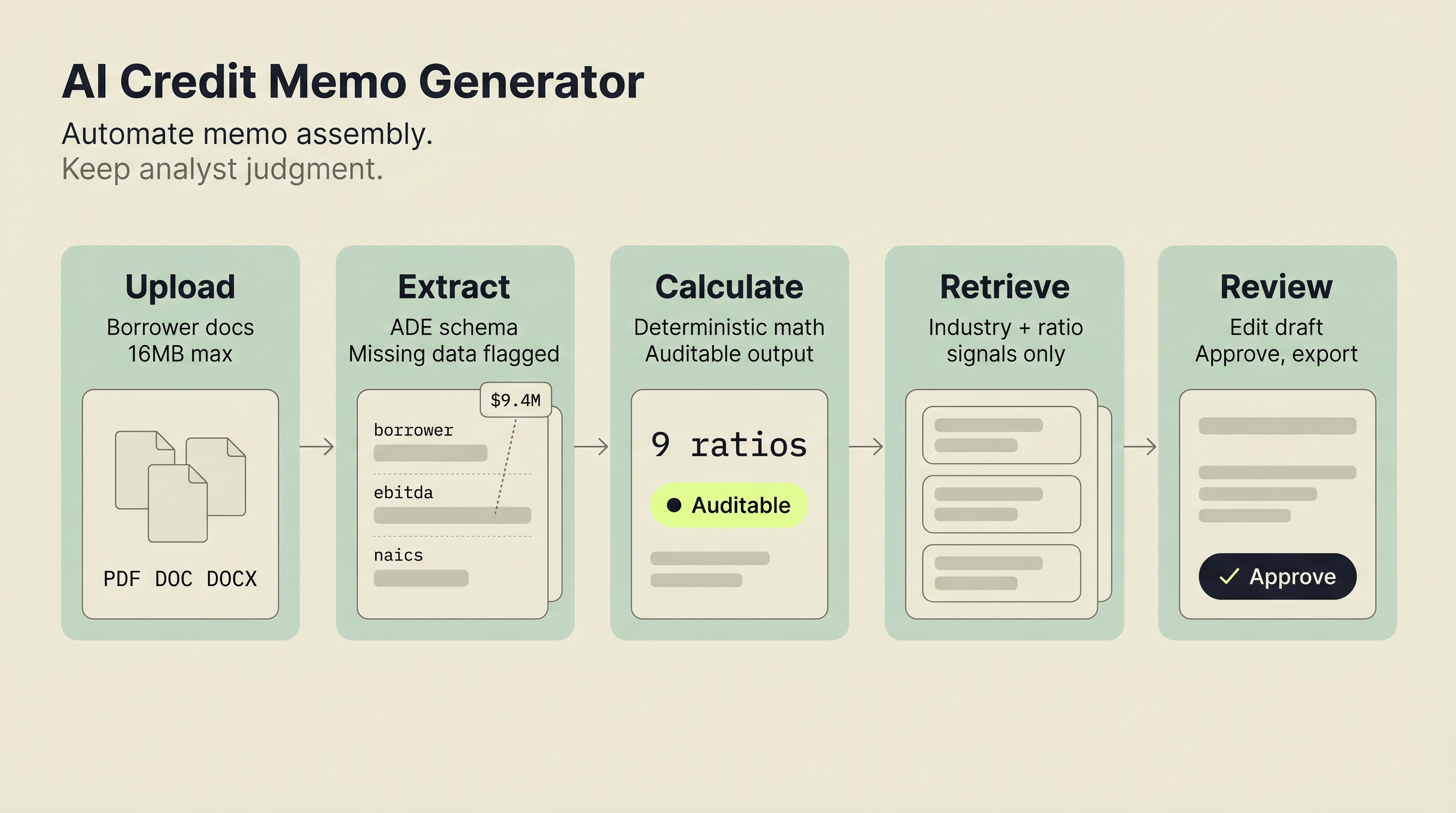
In this prototype, the workflow chains four stages into one pipeline: document extraction, financial ratio calculation, retrieval-augmented context lookup, and LLM-based narrative drafting. The analyst still reviews everything. The difference is that they edit a draft instead of building one from scratch.
LandingAI's Agentic Document Extraction (ADE) extracts structured data from uploaded documents. A Python engine computes 9 standard credit ratios. PostgreSQL with pgvector handles retrieval across a demo knowledge base built from synthetic credit memos. AWS Bedrock Claude Haiku drafts the narrative following a single prototype bank memo structure. Watch the full demo or read on for implementation details. Siva built the full system, called Ernie, as a hackathon prototype.
Why Does Credit Memo Preparation Take So Long?
Picture a credit analyst's Monday morning. They open a prior approved memo, copy the structure, then spend the next several hours hunting through file systems for the borrower's financials. They manually spread numbers into Excel. They calculate ratios by hand or with basic macros. Then they write narrative sections by recycling language from similar deals, adjusting details one field at a time.
Each step introduces delay. Each manual entry introduces potential error. The bottleneck isn't analysis skill. It's data assembly: locating, reformatting, and transcribing financial data before any judgment can happen.
So why does the average credit memo still get built this way? Because the hardest part is not generating prose. It's turning scattered PDFs and Word files into structured values that downstream systems can actually use. Three technologies make this workflow ready for prototyping today: document extraction APIs that read financial statements into structured data, retrieval-augmented generation that surfaces relevant precedent, and large language models that draft narrative sections within template constraints. None of these replace the underwriter. They reduce the manual assembly work around the underwriter.
What Does the Prototype Actually Show?
Before getting into the details, here is the practical takeaway: if enterprises or developers want to test AI in underwriting-like workflows, they should start at the document layer. Once extracted fields are reliable, deterministic calculations, retrieval, and drafting become much easier to evaluate.
The prototype completed a document-to-draft workflow in roughly 40 seconds on supported file types, compared to the hours analysts typically spend on data assembly alone. More importantly, it isolated exactly where the pipeline is fragile: when source documents are missing required fields, the extraction schema flags them explicitly rather than allowing incomplete data to silently propagate through ratio calculation and drafting. That visibility is itself a useful output for any team scoping an enterprise pilot.
For context on how similar document-heavy workflows decompose across industries, the accounts payable automation and intelligent document processing in retail banking use cases follow the same extraction-first pattern and are worth reviewing alongside this prototype.
How Does the Prototype Work?
The prototype runs four stages in sequence. The full flow takes roughly 40 seconds from document upload to draft memo on supported files. The point of the demo is not to claim production readiness. It's to show that the underwriting bottleneck can be decomposed into testable steps, and that the first high-value step is document processing.
Here's what each stage does:
Stage 1: Document Extraction. Upload a PDF or Word file. An extraction API reads it and returns structured data: revenue, net income, total assets, current liabilities, and 12+ other financial fields.
Stage 2: Ratio Calculation. A deterministic engine computes 9 standard credit ratios. No AI here. Pure math with defined formulas and industry-standard thresholds.
Stage 3: RAG Context Retrieval. The system queries a vector database seeded with synthetic credit memo examples. It pulls industry-relevant language, risk factors, and structural patterns that can inform the current deal.
Stage 4: LLM Narrative Drafting. A language model receives the extracted data, calculated ratios, and retrieved context. It drafts a credit memo following the prototype's memo structure.
Key design choice: The downstream stages are independently testable and replaceable. The ratio engine, RAG database, and LLM are separate modules after document extraction completes. If RAG is unavailable, Ernie falls back to template-only prompting. If Bedrock is unavailable or errors, it returns a mock/template memo instead of crashing. In a hackathon setting, this modularity makes iteration faster. In an enterprise setting, it makes future hardening easier.
What this prototype demonstrates is narrower and more useful than a sweeping "AI replaced underwriting" claim. It shows that once document extraction, ratio calculation, retrieval, and drafting are separated, teams can identify exactly which step is causing friction and where a platform like LandingAI adds the most value.
What Happens During Document Extraction?
Document extraction converts unstructured financial files into machine-readable data in seconds. For this prototype, that is the core pain point to solve first. If teams cannot trust the extracted values, the rest of the pipeline does not matter.
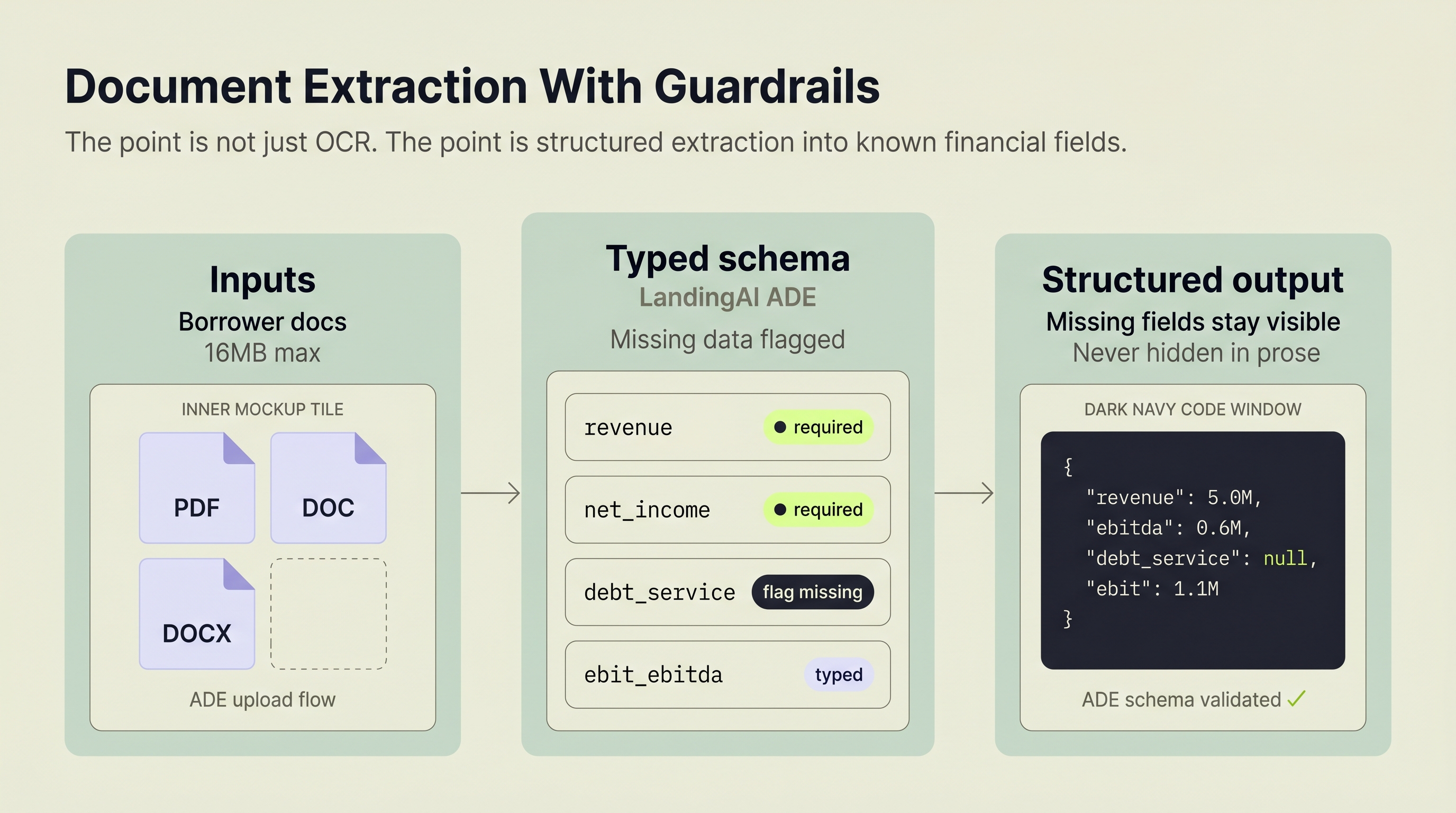
Ernie uses LandingAI's Agentic Document Extraction (ADE) API with a Pydantic schema defining exactly what to extract. The schema includes 16+ financial fields: revenue, net income, operating income, EBIT, EBITDA, total debt, total assets, current assets, current liabilities, inventory, accounts receivable, interest expense, and more.
For enterprises and developers evaluating LandingAI in DPI-style workflows, this is the useful lesson: extraction is not just a convenience feature. It's the handoff that determines whether downstream analytics, retrieval, and generation are trustworthy or brittle. The same principle applies across document-heavy workflows, as explored in why document extraction breaks at scale.
Why does a schema matter? Without one, an extraction API returns whatever it finds. With a typed schema, the system knows what's missing. If the uploaded document doesn't contain a debt service figure, the ratio engine flags it rather than silently computing garbage.
Implementation detail: Ernie accepts PDF, DOC, and DOCX formats up to 16MB. Each upload is saved temporarily and processed through the ADE API. In the current backend, the file is removed after successful processing; production hardening should also guarantee cleanup on failure paths. The extracted data feeds directly into the ratio calculation engine with zero manual reformatting.
This single automation step addresses the largest time sink in commercial underwriting, freeing analysts to focus on credit judgment instead of data entry.
How Does the System Calculate Credit Ratios?
Automated ratio calculation eliminates the spreadsheet errors that undermine manual underwriting. The prototype separates ratio computation from the LLM layer entirely. This stage exists to keep the narrative layer honest.

Ernie computes 9 standard credit analysis ratios:
- Debt Service Coverage Ratio (DSCR): Net Operating Income / Total Debt Service. Healthy: ≥ 1.25
- Total Debt to EBITDA: Total Debt / EBITDA. Healthy: ≤ 2.0
- Current Ratio: Current Assets / Current Liabilities. Healthy: ≥ 2.0
- Quick Ratio: (Current Assets - Inventory) / Current Liabilities. Healthy: ≥ 1.0
- Net Income Margin: (Net Income / Sales) x 100. Healthy: ≥ 10%
- Interest Coverage: EBIT / Interest Expense. Healthy: ≥ 3.0
- Leverage Ratio: Total Debt / Total Assets. Healthy: ≤ 0.3
- Working Capital: Current Assets - Current Liabilities. Healthy: positive
- Days Sales Outstanding: (Accounts Receivable / Total Credit Sales) x 365. Healthy: ≤ 45 days
No AI touches this stage. The formulas are deterministic. Given the same inputs, the same outputs appear every time.
Why keep ratios separate from the LLM? Trust. A language model can hallucinate a number. A Python function can't. By calculating ratios in a dedicated engine and passing them as structured inputs, the system guarantees the numbers are correct even if the narrative needs editing.
What Does RAG Add to Credit Memo Generation?
Retrieval-augmented generation injects relevant context from a curated knowledge base into the drafting process. In this hackathon build, the RAG layer is best understood as a quality aid, not an enterprise knowledge system. It helps the memo read less generically by pulling in examples that are closer to the current financial profile.
Without RAG, an LLM generates credit memos from its general training data. The output reads like generic financial writing. With RAG, the system retrieves relevant chunks from a curated knowledge base, then passes those chunks as context alongside the extracted financial data. The difference is specificity.
How Ernie implements RAG: 50 synthetic credit memos are chunked into 75 searchable segments, embedded using Sentence Transformers
all-mpnet-base-v2(768-dimensional vectors), and stored in PostgreSQL with the pgvector extension. HNSW indexing delivers sub-100ms semantic retrieval. When generating a new memo, the system retrieves up to 3 relevant chunks using borrower industry plus ratio-derived signals such as debt service coverage, liquidity, and leverage.
What happens when the borrower is in manufacturing? The RAG layer pulls manufacturing-specific language, risk factors, and structural patterns, not boilerplate text recycled from a real estate deal.
RAG also makes the system easier to extend. If an enterprise chose to build on this prototype, approved memos and policy materials could be added to the knowledge base over time without retraining any models. The RAG market reached $1.85 billion in 2025 with a projected 49% CAGR (Precedence Research, 2025), which reflects how quickly enterprise teams are adopting retrieval-augmented patterns across document-intensive workflows.
How Does the LLM Draft the Final Memo?
The language model receives structured inputs, not a vague prompt. In this prototype, the LLM is the last step, not the first bet. That ordering matters. The draft only becomes useful because the extraction, calculation, and retrieval stages have already reduced ambiguity.
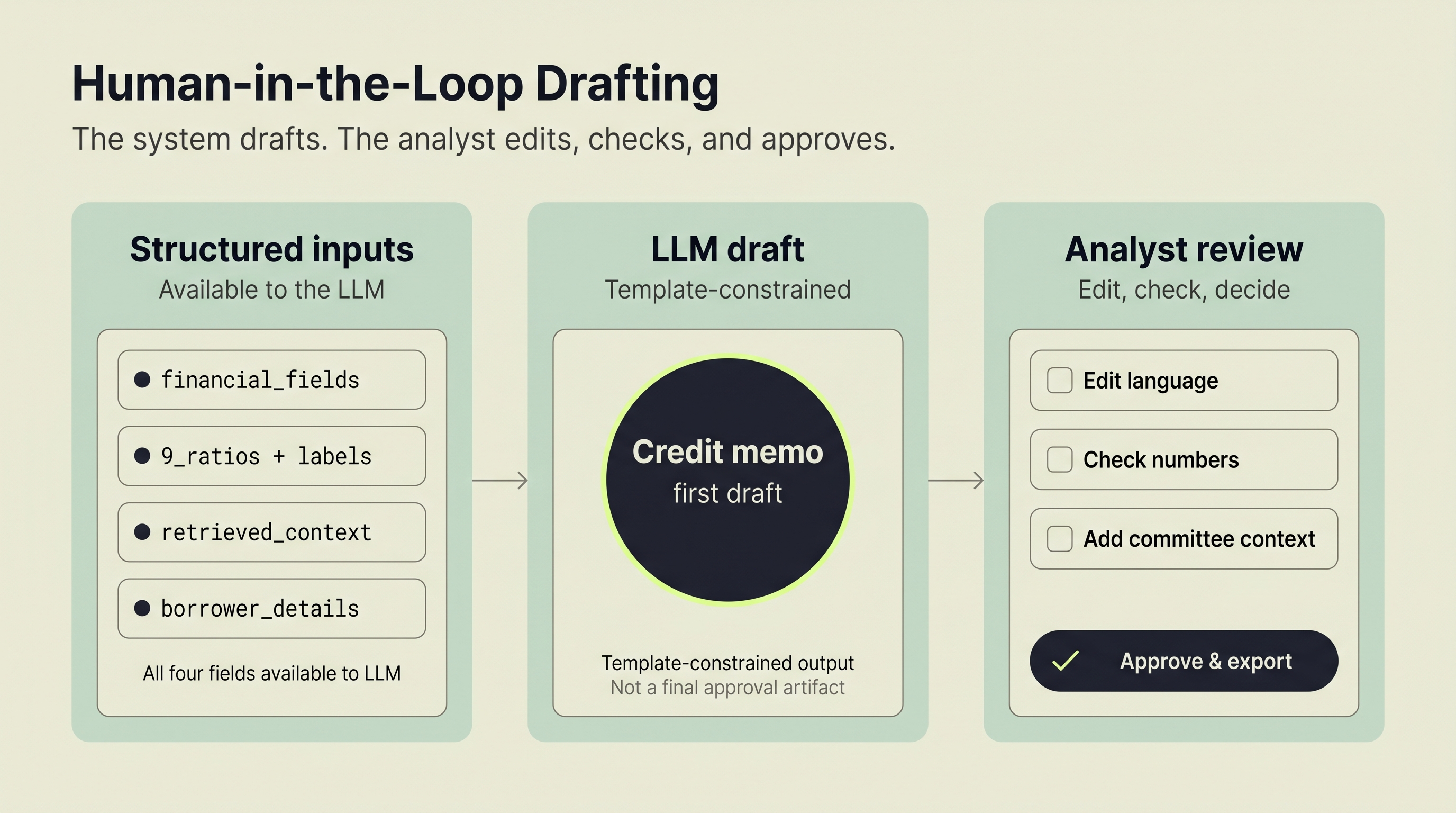
Ernie sends AWS Bedrock Claude Haiku four inputs: extracted financial data, calculated ratios with interpretations, RAG-retrieved context chunks, and borrower information. The model generates narrative sections following the "5 Cs of Credit" framework: Character, Capacity, Capital, Collateral, and Conditions.
This isn't an open-ended prompt. The template constrains the output structure. The model fills sections, not pages. Each section references specific numbers from the ratio engine and specific context from the RAG retrieval.
Design decision: Ernie works without Bedrock connected. If AWS credentials aren't configured, it returns a placeholder memo instead of crashing. This fallback means extraction and ratio calculation still deliver value when the LLM layer is unavailable. In a hackathon, that kept the build moving. In an enterprise pilot, the same pattern helps teams isolate failures and evaluate partial value.
The output is a draft. Analysts edit it in a built-in memo editor, adjust language for their credit committee's preferences, and download the result as a Word document. The AI assembles. The human applies judgment.
What Can Enterprises and Developers Take From This?
This prototype is useful beyond credit memos. It gives credit and ops teams a practical way to pinpoint where manual document work is slowing the pipeline, and gives builders a clear starting point for fixing it:
- Where is time lost to manual document reading, copying, and normalization?
- Which downstream decisions depend on structured fields rather than free-form text?
- What can be kept deterministic instead of pushed into an LLM?
- Where does a document-processing layer like LandingAI ADE have the most impact?
For developers, Ernie shows a sensible prototype order of operations:
- Start with extraction and schema validation.
- Add deterministic calculations for trust-sensitive fields.
- Use retrieval to improve specificity.
- Put the LLM at the end, where it drafts from structured context instead of inventing structure.
For enterprise teams, the LandingAI takeaway is not "buy an AI memo writer." It's that document-processing is often the bottleneck hiding underneath the visible workflow. If PDFs, Word files, and scanned financials are still entering the process manually, a DPI-style extraction layer is often the first thing worth piloting, particularly for banks and financial services teams where document volume is high and error consequences are significant.
SBA 7(a) loan underwriting is the backbone and a major source of income for regional banks. A typical credit analyst processes about 10 loan applications per month, documenting and generating credit memos for review and approval. If that analyst can process 50 loans a month using a tool like Ernie, that's almost 500 additional loans for the bank and about $1.4 million in additional net interest income (profit, not margin) for a bank like Huntington. That's a significant ROI for a small investment, and it helps credit analysts perform like underwriting superstars.
Community banks with growing small business clientele are 49% more likely to invest in AI for operational efficiency than their counterparts (BNY, 2025). A significant adoption gap still persists between the largest banks and smaller institutions (ABA Banking Journal, 2025), which is exactly why lightweight prototypes like this are helpful: they make the first viable pilot easier to identify.
What Does the Prototype Prove?
Credit memo generation follows a pattern that is prototype-ready for automation. Not the judgment calls. The assembly work around them.
The pipeline runs four stages: extract financial data from uploaded documents, calculate credit ratios with deterministic formulas, retrieve relevant context from a curated knowledge base, and draft narrative using an LLM constrained by a fixed memo structure.
What makes this practical today:
- Document extraction APIs read PDFs and Word files into structured data
- Deterministic ratio engines eliminate spreadsheet errors
- RAG grounds LLM output in curated memo examples, not generic training data alone
- The analyst stays in the loop, editing drafts instead of building them from scratch
Ernie proves the pattern works with a modest tech stack: Flask, React, LandingAI ADE, PostgreSQL with pgvector, and AWS Bedrock. The source code is on GitHub and the 4-minute demo walks through the full pipeline in action.
For enterprises and builders exploring similar workflows, the practical question is not how to fully automate underwriting. It is which painful document-heavy step to tackle first, and what that unlocks downstream. This prototype argues that extraction is the right starting point.
Explore the Build
Siva shipped the full prototype. You can review the source code on GitHub, watch the 4-minute demo, or try the live deployment yourself.
Scoping a credit memo or underwriting automation workflow? Email us to discuss applying the same extraction pattern to your documents.
Frequently Asked Questions
Does an AI credit memo generator replace human underwriters?
No. In this prototype, the system automates data assembly, not credit judgment. It extracts financial data, calculates ratios, and drafts narrative sections. The underwriter reviews, edits, and approves the final memo.
What document formats can AI extraction handle?
Ernie accepts PDF, DOC, and DOCX files up to 16MB. LandingAI's ADE API processes these formats and returns structured data using a typed Pydantic schema with 16+ financial fields. Automating this step addresses the single largest time sink in commercial underwriting, compressing hours of manual data entry down to seconds.
How accurate are AI-calculated financial ratios?
The ratios are deterministic, not AI-generated. A Python calculation engine applies standard formulas to extracted data. Given the same inputs, it produces identical outputs every time. Separating ratio calculation from the LLM means the numbers in the memo are always reproducible and auditable. The model cannot hallucinate a financial figure.
What is RAG and why does it matter for credit memos?
RAG (retrieval-augmented generation) retrieves relevant examples from a knowledge base before the LLM generates text. For credit memos, that means the output can reflect patterns from curated memo examples instead of generic language alone. The RAG market reached $1.85 billion in 2025 with a projected 49% CAGR (Precedence Research, 2025).
How long does AI-assisted credit memo generation take?
In this prototype, Ernie processes a document through extraction, ratio calculation, and memo generation in approximately 40 seconds. Processing time varies with document complexity, model availability, and whether retrieval is enabled.