Reasoning models are good at thinking over text but documents aren’t just text. PDFs are visual artifacts—tables, columns, captions, footnotes—and flattening them erases structure and invites errors. This post shows how Model Context Protocol (MCP) lets an agent discover and call LandingAI’s Agentic Document Extraction (ADE) for layout-aware parsing. The result is grounded data—values with page indexes and bounding boxes—from local, governed sources. With MCP + ADE, you get reliable, auditable document workflows that let reasoning models actually reason over what’s on the page.
What you’ll learn from this post:
- The broader vision behind MCP – How Model Context Protocol transforms AI agents from simple text processors into capable systems that can discover, connect to, and orchestrate external tools and resources in enterprise environments.
- Why LLMs alone fall short for document processing – The fundamental limitations of base language models when dealing with structured documents like PDFs, and why flattening visual artifacts leads to errors and hallucinations.
- MCP architecture and how it works – The three-component system (host app, client library, and server) that enables agents to dynamically discover capabilities through tools, resources, and prompts rather than hardcoded logic.
- Real-world document intelligence challenges – How traditional AI assistants struggle with complex document layouts, multi-page author lists, and precise numerical extraction from research papers and technical documents.
- ADE + MCP solution in action – A complete workflow showing how layout-aware parsing with page coordinates and bounding boxes delivers grounded, auditable data extraction that reasoning models can actually trust.
- Building composable, enterprise-grade workflows – How MCP’s pluggable architecture enables modular document processing pipelines that can scale across teams while maintaining accuracy and governance standards.
Model Context Protocol (MCP): why it’s a big deal and how it actually works
In the last few months, you might have heard people talking about enhancing desktop applications with agentic functionality—but if you want to write agentic AI applications at work like a pro, you need a broader vision. I’ll explain how it works. (And no, the “USB-C of AI applications” analogy isn’t helpful—it didn’t help me, and it probably won’t help you.)
How LLMs work— and where they fall short for actions
From the outside, an LLM is simple: you send a prompt, you get a response. Two problems:
- The response is just words. If words are all you need, great.
- If you want to do something—cause real effects in the world—the AI must be able to take actions (invoke tools). It also needs more up-to-date or simply broader information than the base model contains.
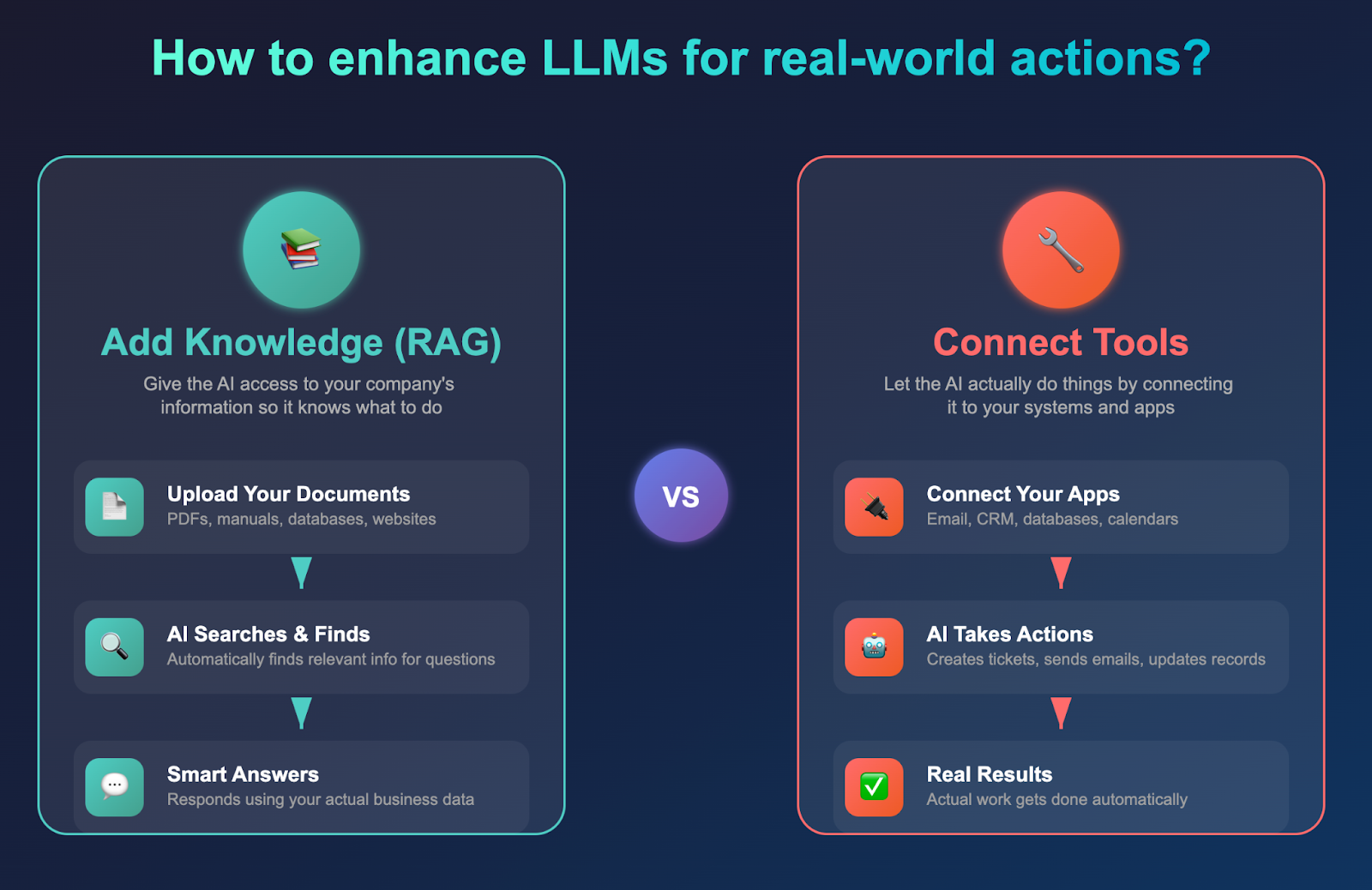
That base model is an API on the internet. You might wrap it with Retrieval-Augmented Generation (RAG). Some say RAG is yesterday’s news; in enterprise contexts you may well use it—and there’s nothing wrong with that—to bring enterprise data into the model’s context.
RAG or not, there will be other resources you must bring into scope for the model: files, binaries, databases—data “out in the world” that the agent needs to be aware of. These things are not present in the base model.
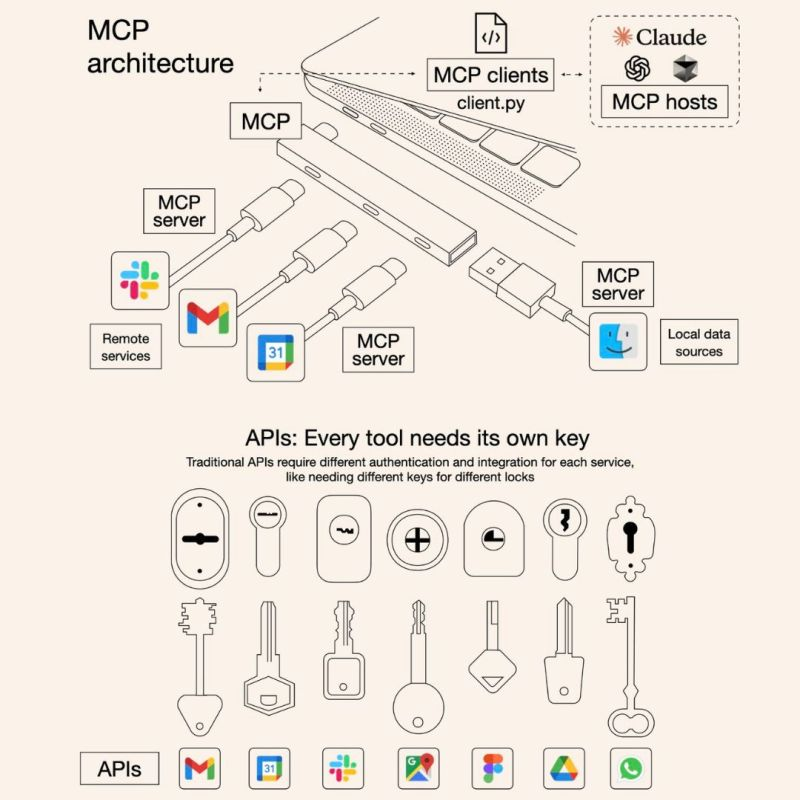
MCP architecture: host app, client library, and server
What we’re building is an agent that includes an MCP host application component to interact with MCP servers
Outside the host, we stand up (or reuse) an MCP server. Inside that server live tools, resources, and prompts—the capabilities the server exposes and describes to the outside world.
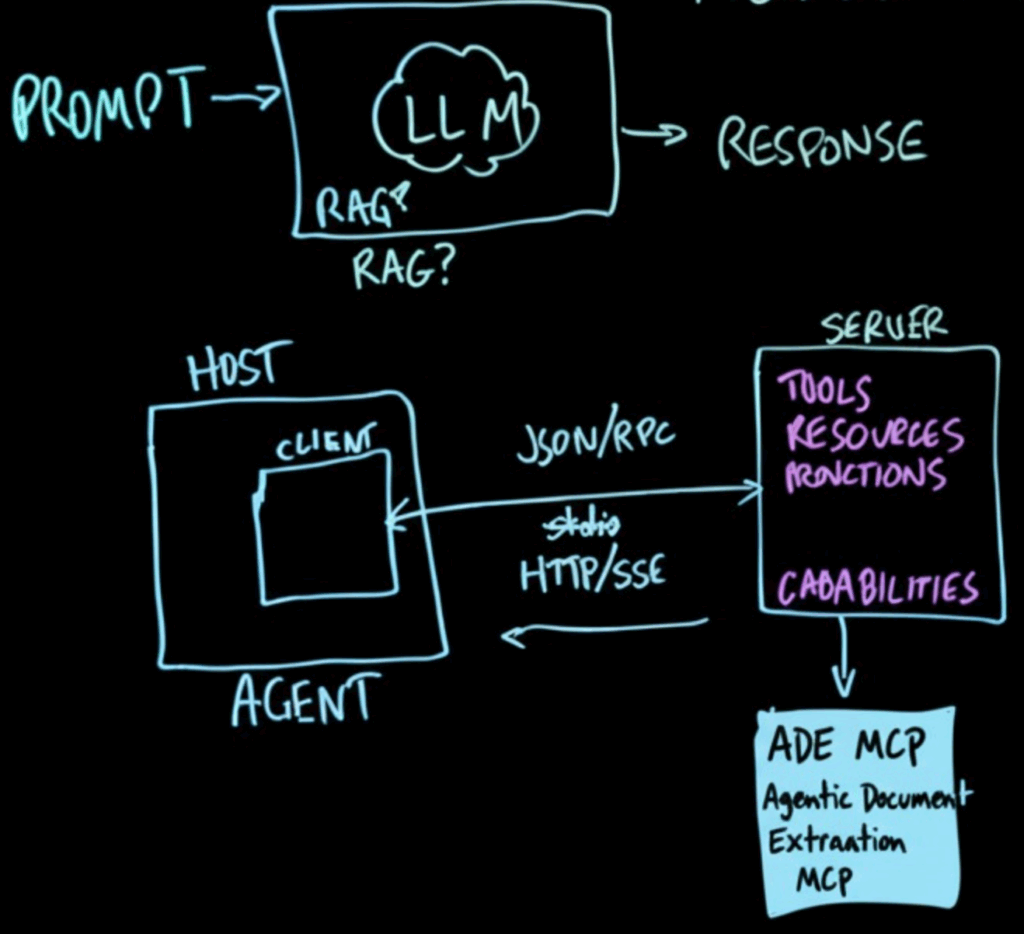
At its core, MCP is just a way for a client (like an AI app) and a server (your custom tool or service) to talk in a predictable, structured way.
- The server is like a little program that listens on an address
Think of it like a shop with a street address: it has a URL and a port number where others can reach it. - It speaks a standard “language” of endpoints
The server follows the MCP playbook — ‘P’ for protocol (similar to how websites follow web standards). It offers a menu of what it can do, such as which tools it has, what resources are available, and what ‘prompts’ you can ask it to run. - Two ways to connect
- For something running locally (like Claude Desktop talking to your laptop), they can connect through stdio — basically direct pipe-to-pipe communication.
- For more web-like setups, they can connect over HTTP with Server-Sent Events (SSE) — think of it as a steady live feed of messages over the web.
- For something running locally (like Claude Desktop talking to your laptop), they can connect through stdio — basically direct pipe-to-pipe communication.
- Conversations happen in JSON-RPC messages
The client and server exchange little JSON packets that say things like “here’s who I am,” “here’s what I want,” or “here’s the result.” At the start, there’s a quick handshake so they agree on how to talk. - It’s two-way
Not only can the client ask the server for things, but the server can also send asynchronous notifications back — basically, “Hey, something just happened you should know about,” without waiting for the client to ask.
Inside the Server, MCP organizes everything into a clear set of capabilities. These include tools (functions the server can run, like extracting tables or verifying numbers), resources (files, datasets, or folders the server can access and expose, such as ~/papers/), and prompts/functions (higher-level tasks packaged for reuse, like “list authors” or “summarize results”). Together, this capability list works like a menu: when the client connects, it immediately knows what the server can do and how to use it, without custom coding or hardwiring logic into the agent.
The ADE MCP block is a concrete example of such a server. Unlike a plain LLM that only sees flattened text, ADE is layout-aware — it knows about page numbers, bounding boxes, tables, and fields. Its tools let an agent extract tables, pull specific metrics (mAP, FID, latency), capture author lists across multiple pages, and even verify individual numbers by pointing to the exact cell in the PDF. This ensures outputs are grounded, traceable, and reliable. In other words, ADE provides high accuracy extractions from documents even with complex layouts, while MCP makes it seamlessly discoverable and usable inside larger workflows.
A Real-World Scenario: Catching Up with VLM Evolution
Imagine you want to quickly catch up with the rapid evolution of vision-language models (VLMs) — reviewing more than 20 major models, from YOLOv1 all the way to Stable Diffusion. Each paper introduces new techniques, architectures, and benchmarks, often buried in dense prose and tiny performance tables.
Naturally, you might turn to an AI assistant to help you summarize and compare them. At first glance, the assistant does reasonably well with prose — explaining the big picture of each model. But when it comes to the numbers that really matter for benchmarking, the cracks show. A single misread decimal or misplaced value can completely distort a performance comparison. In practice, you’re forced to go back and manually cross-check every table cell to ensure accuracy.
The problem becomes even clearer when you look at document structures. For example:
- In the seminal Attention Is All You Need paper, the authors are listed cleanly under the title, making extraction straightforward.
- But in the more recent DeepSeek-R1 paper, where contributors span multiple dense pages, the model fails entirely — unable to navigate the complex formatting and find out who the major authors are.
This highlights a fundamental limitation: LLMs treat documents as flattened streams of text. That works well for linear prose, but not for structured content like tables, charts, or long contributor lists. Without understanding the visual layout of a document, the model is prone to hallucination — filling in gaps or misinterpreting data.
On top of that, the workflow itself is clunky. You’d need to manually download PDFs, upload them into a chat interface (with 10 file limits), and repeat the process over and over. For anyone working at enterprise scale, this is neither efficient nor sustainable.
How ADE MCP Solves These Limitations
With MCP, the missing capabilities aren’t left to chance — they’re packaged as tools behind a server, and the AI agent can call on them exactly when needed. Here’s how that changes the game:
- Extracting numbers from tables
Instead of flattening a PDF and hoping the AI guesses correctly, ADE provides layout-aware extraction. Every value comes with its page number and bounding box (page_index + bbox), so you know where in the table it came from. - Normalizing benchmarks and units
Metrics like AP@[.5:.95], percentages, or milliseconds often appear in inconsistent formats. With schema-guided fields and unit reconciliation, MCP ensures these numbers are standardized before comparison. - Capturing full author lists
Multi-page contributor sections no longer confuse the model. Span-aware extraction reads the document in the right order, ensuring nothing gets skipped or scrambled. - Direct access to PDFs
No more dragging-and-dropping files ten at a time. MCP can point the assistant to an allowlisted folder of resources — so it reads documents directly, without upload limits. - Verifying suspicious numbers
If a value looks off, the assistant can use a verify-by-bbox tool to double-check the exact cell on the page. This adds a layer of trust and auditability to the workflow.
In short: you could flatten PDFs and hope the LLM makes the right guesses. But with MCP, these capabilities are formalized into a server that the AI host can discover and invoke on demand — ensuring accuracy, consistency, and scalability.
Example workflow: prompt → capabilities → resources → tools
1. The User Prompt
👉 Example: “Compare mAP, FID, and latency scores across 20+ papers (YOLOv1 → Stable Diffusion) from these PDFs.”
A plain LLM would stumble here: “I see words, but I can’t reliably read the numbers, labels, or table structures.”
2. The Host Asks “What Can You Do?”
The host app knows about the MCP server (from a small config file). It asks the server what it’s capable of.
The server replies with a capabilities list, like a menu:
- Resources: ~/papers/ (the folder of PDFs it’s allowed to read)
- Tools:
- ade.extract_tables → pull structured tables
- ade.extract_fields → extract specific metrics like AP@[.5:.95], FID, latency
- ade.list_authors → capture contributor lists
- ade.verify_number → double-check numbers on the page
- ade.extract_tables → pull structured tables
3. The Model Makes a Plan – Enhanced Reasoning
The host passes the user’s request + the server’s capabilities to the model.
The model reasons and replies with a plan:
“Use ~/papers/. Call ade.extract_tables on the ‘Results/Comparison/Ablation’ sections; extract AP@[.5:.95], FID, Top-1, and latency fields; normalize the units; and re-check any suspicious values with ade.verify_number.”
4. The Host Executes Safely
The host app (not the LLM itself) decides whether to run the plan.
- If approved, it calls the MCP server to extract the tables and numbers.
- The server responds with structured, grounded data (values + page coordinates).
The host then attaches this grounded data to the next model prompt:
“Here’s the user’s goal. Here’s the verified data I pulled. What’s the next step?”
5. The Model Refines the Output
With the grounded data in hand, the model can:
- Normalize units (e.g., ms vs seconds)
- Resolve row/column ambiguities
- Match datasets (COCO test-dev vs val)
- Check for outliers
- Trigger follow-up verify-by-bbox calls if needed
Finally, it produces a clean comparison table.
✨ The takeaway:
Instead of hoping an LLM “guesses” correctly from flattened PDFs, MCP turns the workflow into a structured loop of ask → plan → execute → verify. That’s how you get reliable, enterprise-grade results.

Why This Matters: Pluggable, Discoverable, Composable
Traditional agents often have parsing logic baked in. That makes them heavy, rigid, and hard to extend. With MCP, you don’t hard-code everything — instead, you register servers.
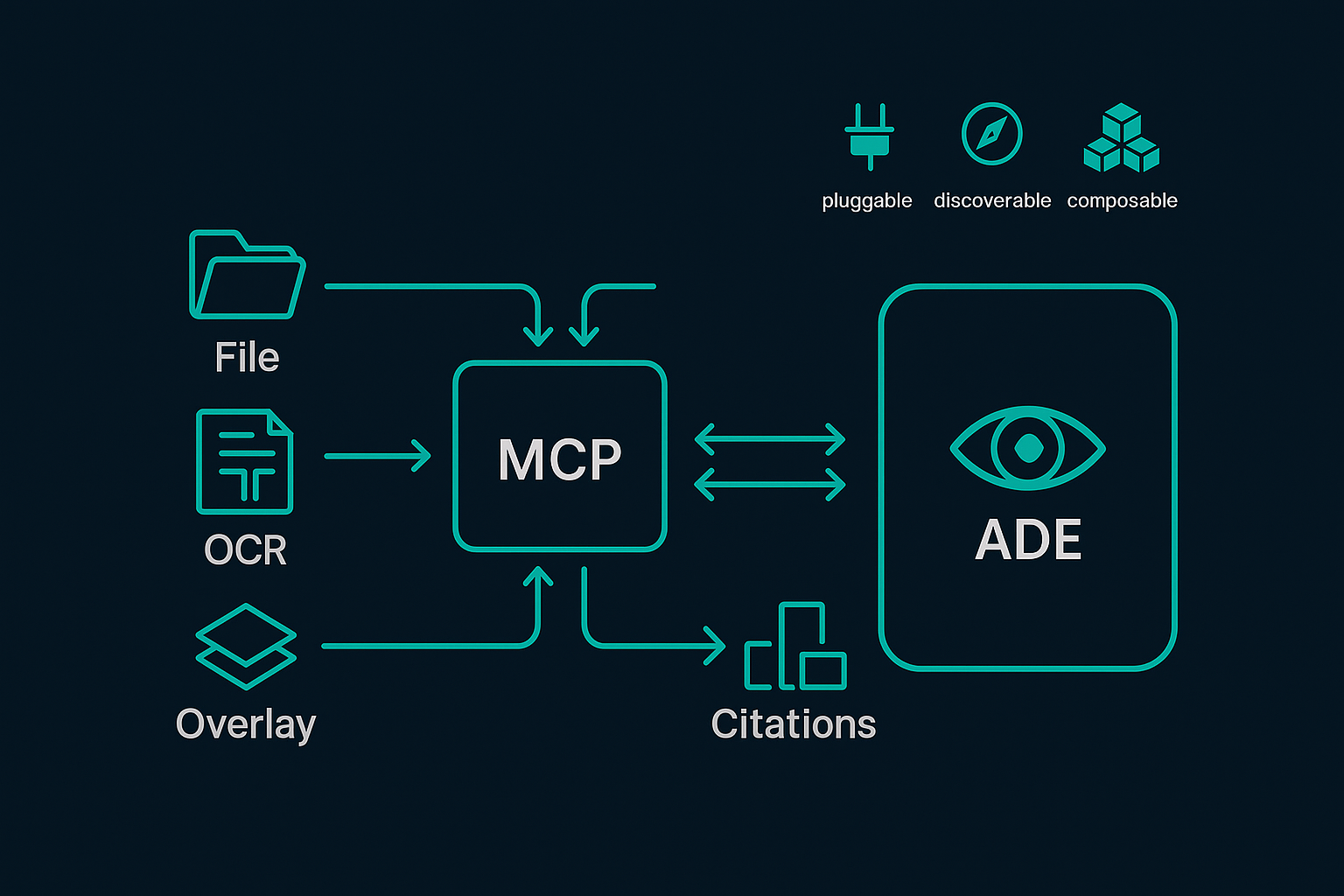
The agent itself stays lightweight. Its capabilities stay modular and discoverable: add a server, and the agent can immediately see what it can do and how to use it.
Even better, these servers are composable: one server can call another. That makes it easy to build pipelines where each piece does one job well. For example:
- File Access ↔ ADE
A File System server exposes ~/papers/ as resources. The ADE server reads directly from those PDFs — no uploads, no limits. - Preprocessing ↔ ADE
A PDF/OCR server can render page images or process scanned docs. ADE calls it first, then runs table/field extraction on the cleaned text. - Grounding Artifacts ↔ ADE
An Overlay/Rendering server uses ADE’s page_index + bbox output to draw boxes on a PNG — perfect for advisor reviews or audits. - Normalization/Exports ↔ ADE
A Metrics/ETL server takes ADE’s grounded values, normalizes units (%, ms, AP@[.5:.95]), and writes them to a warehouse or CSV. - Citations/Metadata ↔ ADE
A Bibliography server (BibTeX, Zotero, etc.) links extracted metrics back to their citations using ADE’s source_id.
The net effect: you can swap or add any component (OCR engine, overlay renderer, exporter) without rewriting the agent. ADE provides the document vision, and MCP makes the entire chain plug-and-play.
Conclusion
You not only learned what MCP is, but also saw how it empowers reasoning models to connect to tools, take actions, and reason better—leading to true agentic AI. In the context of document understanding, the Model Context Protocol (MCP) provides the bridge for agents to connect with external tools and resources in a structured, discoverable way. LandingAI’s Agentic Document Extraction (ADE) extends this by handling the hardest part of document intelligence: parsing complex layouts—with tables and figures—while grounding every value to its exact location. Together, MCP and ADE enable enterprises to move beyond flattened text and brittle guesses, delivering document workflows that are accurate, auditable, and modular.