How to Build a Financial Knowledge Graph with LandingAI
TL;DR
This article documents ArthaNethra (Sanskrit: Artha = wealth, Nethra = eye), a hackathon prototype built by Devi Eswar and Mohan Priya around a practical enterprise pain point: financial investigation workflows break down when the important relationships are spread across flat documents. Analysts can read the files, but they still have to assemble the structure manually.
The prototype tests one idea: use LandingAI ADE as the document processing intelligence layer, normalize the extracted output into a knowledge graph, and then layer on search, risk detection, and an evidence-grounded chatbot. The goal is not polished product marketing. The goal is to show a concrete implementation pattern that enterprise teams and developers can learn from.
The value of the build is not "AI for AI's sake." It is showing how a document pipeline can move from raw PDFs to connected, inspectable structures quickly enough for due diligence, compliance, and internal investigation workflows.
Why Do Financial Investigation Workflows Break Down at Scale?
Financial institutions spend over $206.1B annually on financial crime compliance (LexisNexis Risk Solutions, True Cost of Financial Crime Compliance Global Study, 2023). A significant share of that cost sits in manual review, evidence gathering, and reconciliation across documents.
The workflow looks the same everywhere. An analyst receives a stack of PDFs. Loan agreements, invoices, tax filings, credit reports, identity documents, bank statements. They open each one, extract the relevant numbers, type them into a spreadsheet, and try to piece together relationships between entities. Who owns what subsidiary? Which loans lack collateral? Where do payment flows loop back on themselves?
This process breaks down at scale. Fifty documents might contain thousands of entities and hundreds of relationships. No human can hold that graph in their head. So connections get missed. Risks go unnoticed. And 83% of private equity respondents say their due diligence practices remain outdated, still relying on these manual processes (Accenture Research, It's Time to Rethink Private Equity Due Diligence, 2024). Tier-1 banks face the same workload on KYC and onboarding.
The core problem isn't reading speed. It's that flat documents hide their relationships. This prototype treats that as the real technical problem to solve: how do you turn isolated documents into a structure that is queryable, evidence-linked, and useful to analysts?
Citation capsule: Financial institutions spend $206.1B annually on financial crime compliance (LexisNexis Risk Solutions, 2023; n=1,181 professionals). Yet 83% of private equity respondents say due diligence still relies on manual processes (Accenture, 2024). The friction is not analysis. It is assembly across documents — and assembly is what graphs do.
What Does a Financial Knowledge Graph Make Easier?
The value proposition here is straightforward: some enterprise questions are relationship questions, not keyword questions. If the workflow depends on understanding ownership, guarantees, counterparties, document references, and risk exposure across files, a graph-oriented structure is more useful than a pile of search hits.
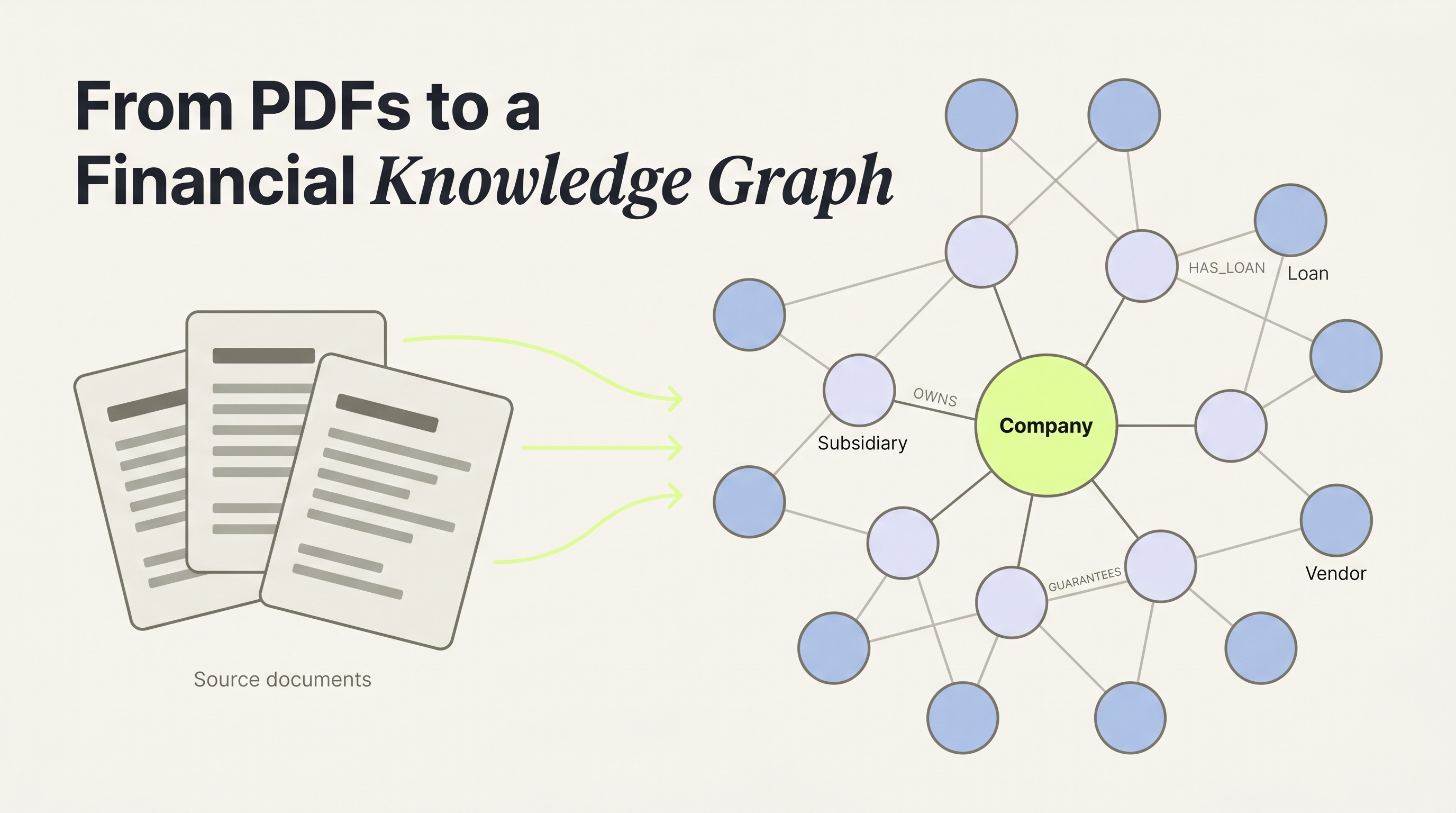
A traditional search finds documents containing a term. A financial knowledge graph finds entities connected through typed relationships across every document in the case. "Show me all subsidiaries with loans over $10M that lack collateral" is a graph query. It's not a search.
ArthaNethra's graph model defines 10 entity types: Company, Subsidiary, Loan, Invoice, Metric, Clause, Instrument, Vendor, Person, and Location. Each entity carries properties (interest rates, amounts, dates), source metadata for traceability, and can carry an embedding vector for semantic search.
Relationships use 26 canonical types. Financial: HAS_LOAN, FINANCED_BY, OWNS, SUBSIDIARY_OF, GUARANTEES, INVESTED_IN, OWES. Operational: PARTY_TO, SUPPLIES_TO, PROVIDES_SERVICE_FOR, RECEIVES_SERVICE_FROM, PARTNERS_WITH. Governance: REGULATED_BY, REPORTS_TO, WORKS_FOR. Cross-references: MENTIONED_IN, REFERENCES, REPORTS_ON. Structural: CONTAINS, LOCATED_IN, ISSUED_BY, ACQUIRED.
This structure means an investigator can start at any node and traverse the graph to find patterns: circular payment flows, unsecured concentration risk, related-party transactions buried across different document types.

Source: MarketsandMarkets, 2024 — BFSI is the largest adoption vertical.
Citation capsule: ArthaNethra models financial documents as a knowledge graph with 10 entity types — Company, Subsidiary, Loan, Invoice, Metric, Clause, Instrument, Vendor, Person, Location — connected through 26 canonical relationships. Search finds documents. A typed graph finds patterns: circular payment flows, unsecured concentration risk, related-party transactions buried across document types.
How Does the ArthaNethra Pipeline Work?
The hackathon build explores a five-stage workflow. The main implementation question was whether LandingAI could serve as the document processing layer, and whether the resulting output could be normalized into graph structures that enterprise users and internal developers would actually find useful.
- Upload. Documents go to
/api/v1/ingest. The service accepts uploaded financial files, assigns each one a unique ID and storage path, and routes it into the extraction pipeline. - Extract. LandingAI's ADE parses each document into structured markdown — converting heterogeneous financial files into a normalized intermediate format. ArthaNethra generates extraction schemas deterministically by analyzing markdown structure (HTML tables, pipe-delimited tables, general layout). Files over 15MB route through async jobs with exponential backoff retry logic.
- Normalize. Specialized parsers handle each document type. Invoices produce Invoice, Vendor, Company, and Metric entities (the same pattern used in accounts-payable automation). Loans produce Loan, Company or Person, Clause, and Metric entities. Narrative documents (10-Ks, 10-Qs, MD&A sections) use Claude 3.5 Haiku with regex patterns, falling back to Claude Sonnet 4.5 when needed.
- Index. Entities and embeddings go into Weaviate for semantic search via a sentence-transformers (
all-mpnet-base-v2) sidecar. Relationships go into Neo4j for graph traversal. Document markdown is chunked into overlapping 500-word segments with 100-word overlap. - Risk Detect. Four rule-based checks (high rates, high debt ratios, negative cash flow, approaching maturity) plus LLM-based anomaly detection.
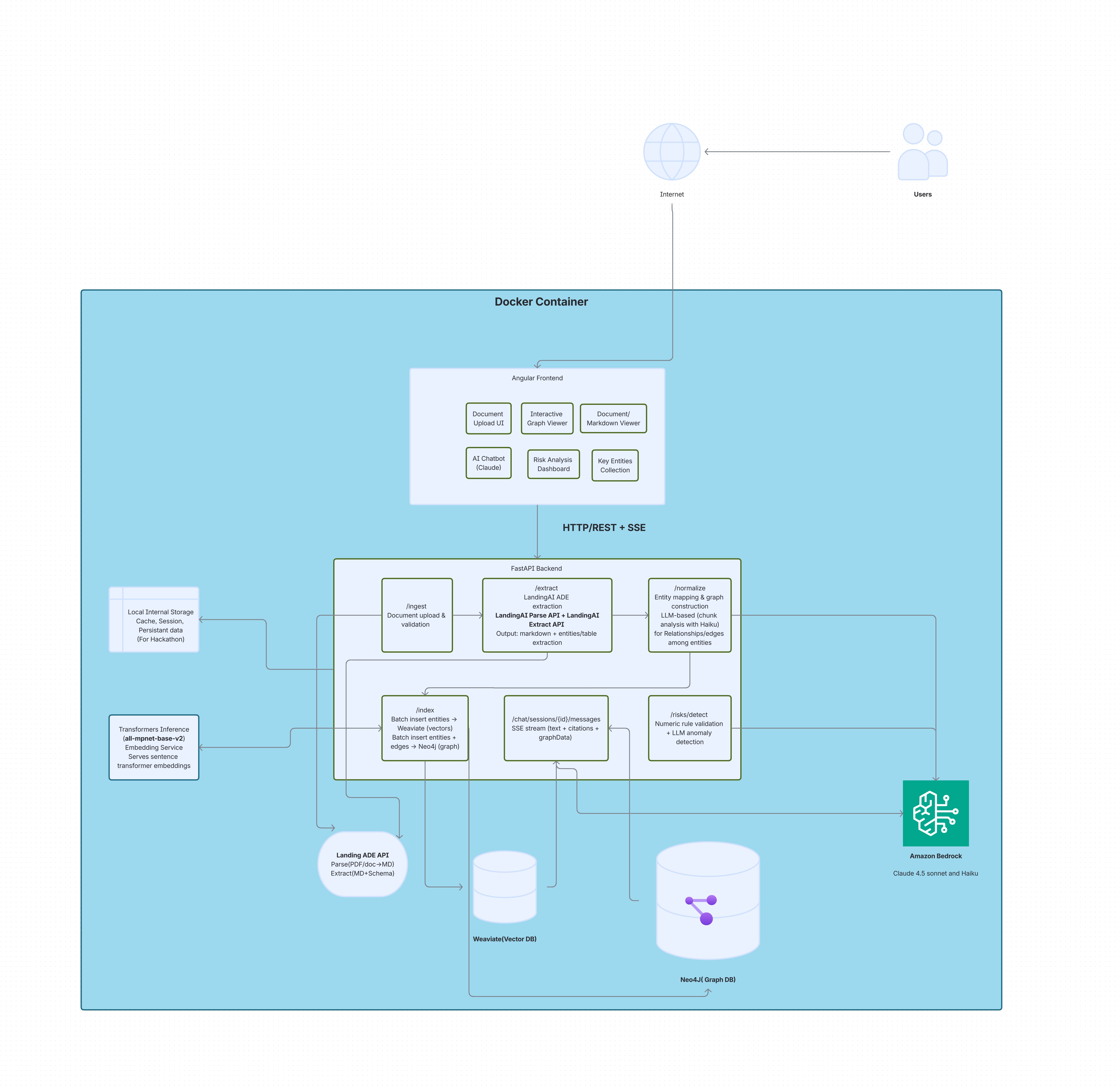
Citation capsule: ArthaNethra's five-stage pipeline uses LandingAI ADE as the document processing intelligence layer: Upload → Extract (ADE) → Normalize → Index → Risk Detect. Files over 15MB route through async extraction with exponential backoff. Deterministic parsers handle invoices, loans, and contracts; narrative documents (10-Ks, MD&A) use Claude 3.5 Haiku.
How Does ArthaNethra Build the Graph?
From an implementation perspective, the hard part is not storing nodes and edges. The hard part is getting from messy source documents to a graph shape that an analyst can trust. This prototype uses a hybrid path: deterministic parsers where document structure is repetitive, and model-based extraction where relationships need interpretation. The same hybrid pattern works well in reinsurance and complex insurance documents.
The normalization service routes each document through the right parser based on type. Invoices, loans, and contracts each have deterministic parsers that produce core entities without LLM calls. The invoice parser, for example, reads line items, totals, dates, and party names, then creates an Invoice plus related Vendor, Company, and Metric entities that can later be connected through typed edges.
For narrative documents (annual reports, disclosures, MD&A), the system combines regex patterns with Claude 3.5 Haiku, falling back to Sonnet 4.5 when the cheaper model is unavailable. Regex catches organizations, monetary amounts, dates, and person names. The LLM handles semantic relationships pattern matching misses: "Company X guaranteed the obligations of Subsidiary Y" becomes a GUARANTEES edge.
Relationship detection works in chunks of 20 entities at a time. A synonym mapping layer normalizes 40+ relationship aliases into 26 canonical types. "OWNER_OF," "PARENT_COMPANY," and "PARENT_OF" all resolve to OWNS. "LOANED_BY," "BORROWS_FROM," and "CREDIT_PROVIDER" resolve to FINANCED_BY. This prevents duplicate relationship types from cluttering the graph.
Entities retain citation metadata pointing back to the document evidence used during extraction, often including page or section details. Nothing is asserted without evidence.
Citation capsule: ArthaNethra normalizes 40+ relationship aliases into 26 canonical types — "OWNER_OF," "PARENT_COMPANY," and "PARENT_OF" all resolve to OWNS; "LOANED_BY" and "BORROWS_FROM" both resolve to FINANCED_BY. Every entity retains citation metadata pointing back to source documents, including page or section, so analysts can verify any node against primary evidence.
What Does Graph-Based Risk Detection Look Like?
For enterprise workflows, risk analysis usually needs two layers. The first is explicit, deterministic checks for known thresholds and policy rules. The second is a more flexible pass for anomalies harder to codify. This prototype combines both.
Four rule-based checks run first:
- Rate risk: interest rates above 8%
- Leverage risk: debt ratios above 0.6
- Liquidity risk: negative operating cash flow
- Refinancing risk: maturity dates within 365 days
Each check produces a Risk object with severity (low, medium, high, critical), the threshold that triggered it, the actual measured value, and a recommended mitigation. An LLM-based anomaly pass then scans the entity graph for patterns the rules don't cover — missing covenants on large loans, unusual payment terms, concentration risk where a single counterparty appears across multiple relationship types.
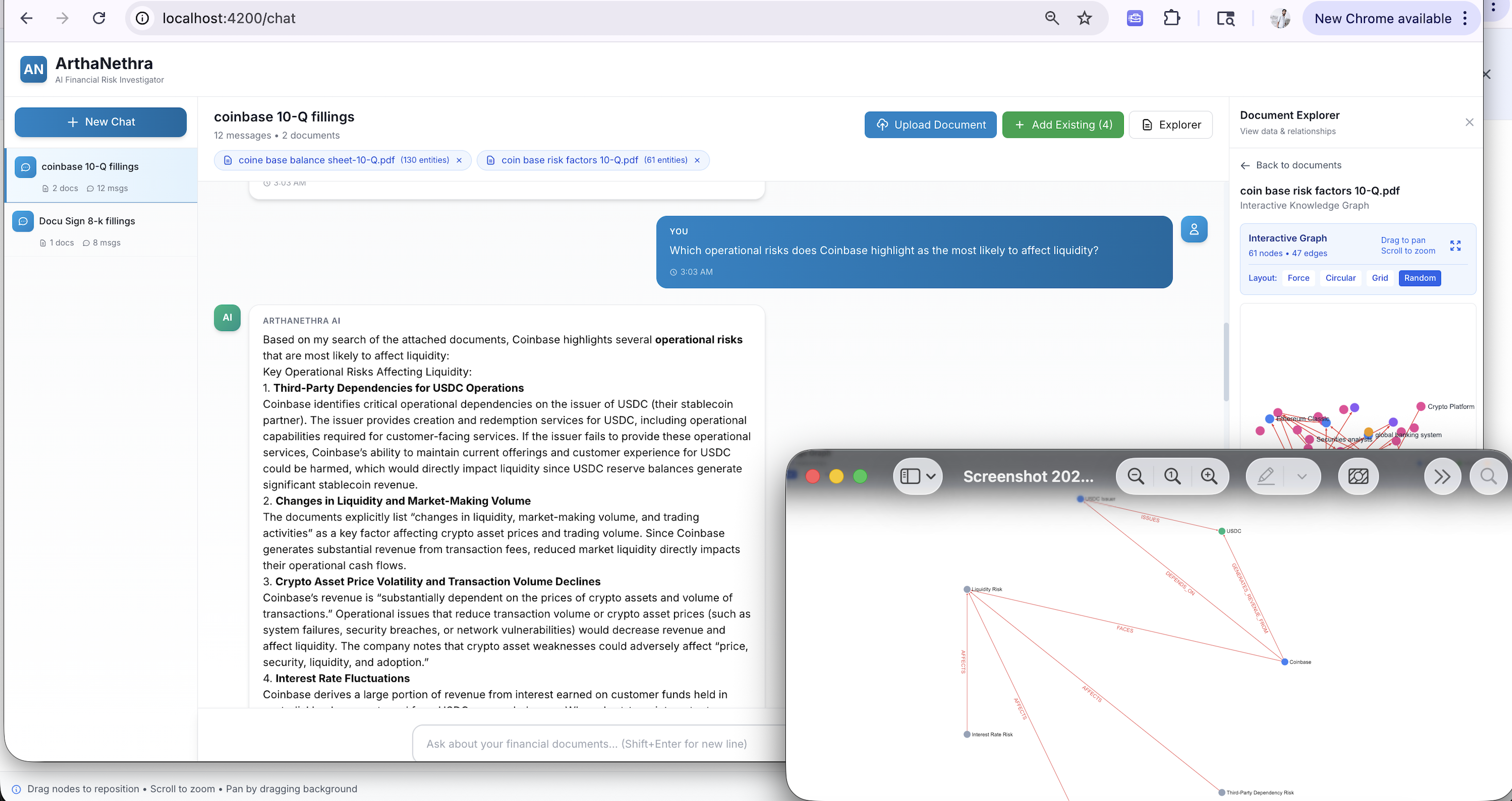
What makes this useful in practice is the graph visualization. Each risk carries a graph_data payload: a subgraph of the specific entities and relationships involved. The frontend renders this as an interactive Sigma.js visualization with four layout options (force-directed, circular, grid, random), edge tooltips, and search within the risk subgraph. Alongside the graph, an ECharts donut chart shows risk distribution by severity. An analyst doesn't just see "High leverage risk." They see which subsidiary, which loan, which counterparty, and the path connecting them.
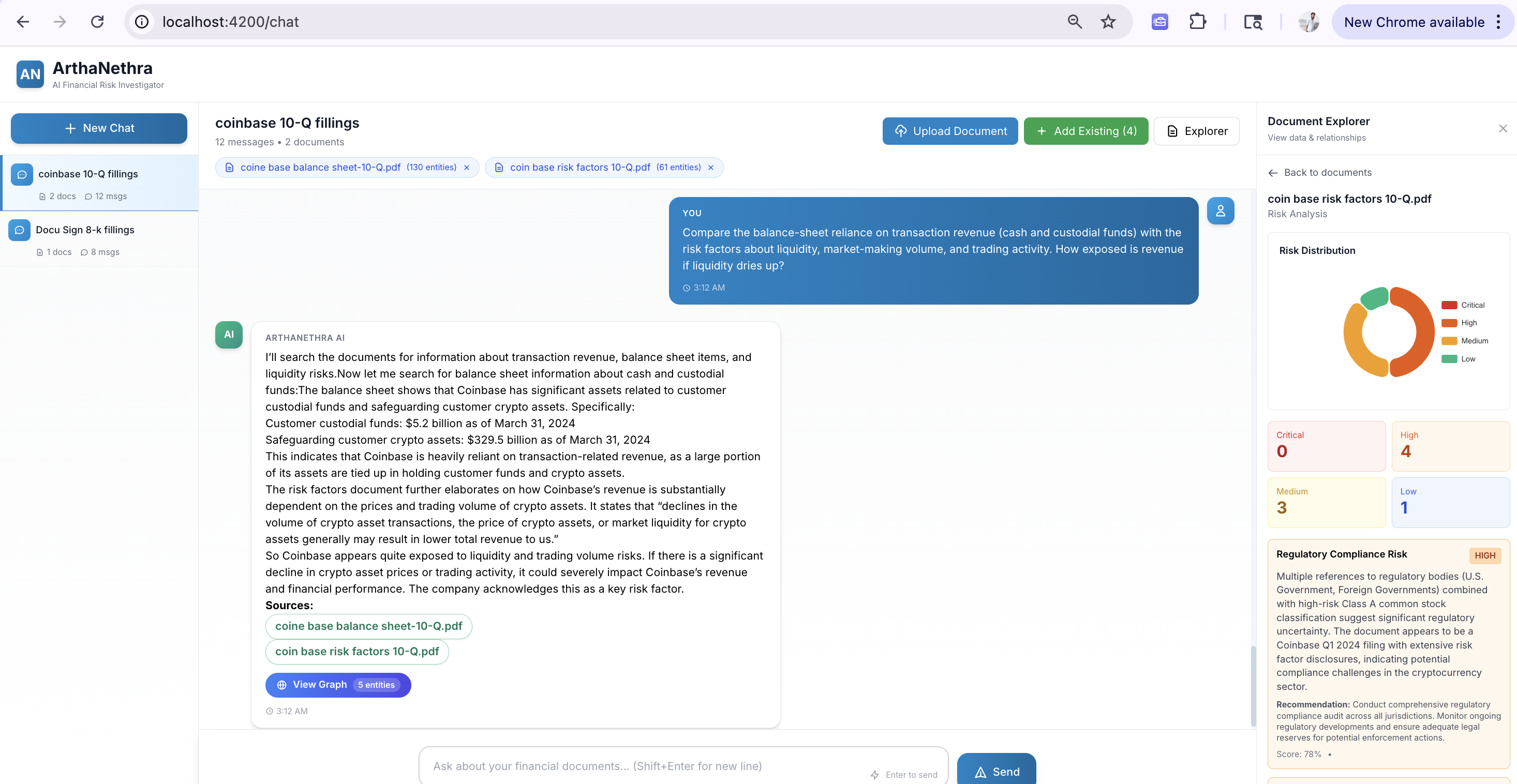
According to LexisNexis Risk Solutions data, false positive rates in AML transaction monitoring average 90-91% across banks, generating massive volumes of manual review that produce no actionable findings (LexisNexis Risk Solutions, 2023). Graph-based risk detection attacks this problem at the source: instead of flagging individual transactions, it flags structural patterns across the full entity network.
Citation capsule: AML transaction monitoring generates 90-91% false positive rates across banks (LexisNexis Risk Solutions, 2023). ArthaNethra runs four threshold rules — rate >8%, leverage >0.6, negative cash flow, maturity within 365 days — then adds an LLM anomaly pass. Graph-based detection targets structural patterns rather than individual transactions.

Source: LexisNexis Risk Solutions, 2023 — n=1,181 financial crime compliance professionals.
How Does Graph-Augmented Chat Work?
For enterprise users, chat is only useful if it is grounded in attached documents and returns evidence they can inspect. Otherwise it becomes a demo feature rather than a workflow tool. This prototype treats chat as an interface over retrieval, graph traversal, and citation handling — not a standalone answer engine. Analysts work in named sessions where they can attach and detach specific documents, maintaining cross-document context across 10-Ks, contracts, invoices, and filings simultaneously.
ArthaNethra's chatbot uses a tool-calling loop. Claude Sonnet 4.5 receives the user's question along with a graph context summary: entity type counts, the first 10 entities as named samples, and metadata for all attached documents. The system prompt enforces a mandatory document search rule: the model must call document_search before answering any question, treating the attached documents as the authoritative source of truth.
The model calls these tools iteratively until it has enough evidence to answer:
- document_search() — searches indexed document chunks for supporting evidence (mandatory first call)
- graph_query() — retrieves structured entities with optional property filters (e.g.,
accounts_payable > 500000) - metric_compute() — backed by a dedicated
AnalyticsServicesupporting 7+ metric types: property thresholds, property comparisons, grouped aggregation, sequential drop detection, liquidity analysis, debt risk, and loan maturity - graph_traverse() — follows typed relationships from a starting entity with configurable depth (1-3 hops) and direction
- graph_path() — finds shortest paths between two entities (e.g., "how are Company X and Vendor Y connected?")
- graph_pattern() — finds entities matching complex structural patterns
- doc_lookup() — retrieves document evidence for a specific page or section request
Cost control matters here. Chat uses Claude Sonnet 4.5 as the primary reasoner with exponential backoff retries (up to 3 retries per model) and automatic fallback to Claude 3 Haiku when throttled. For narrative extraction, Claude 3.5 Haiku is the cheaper default (~10× less expensive than Sonnet). Responses stream to the frontend via Server-Sent Events. When the response includes graph data, the frontend renders an interactive graph alongside the text — the answer is a navigable structure, not just words.
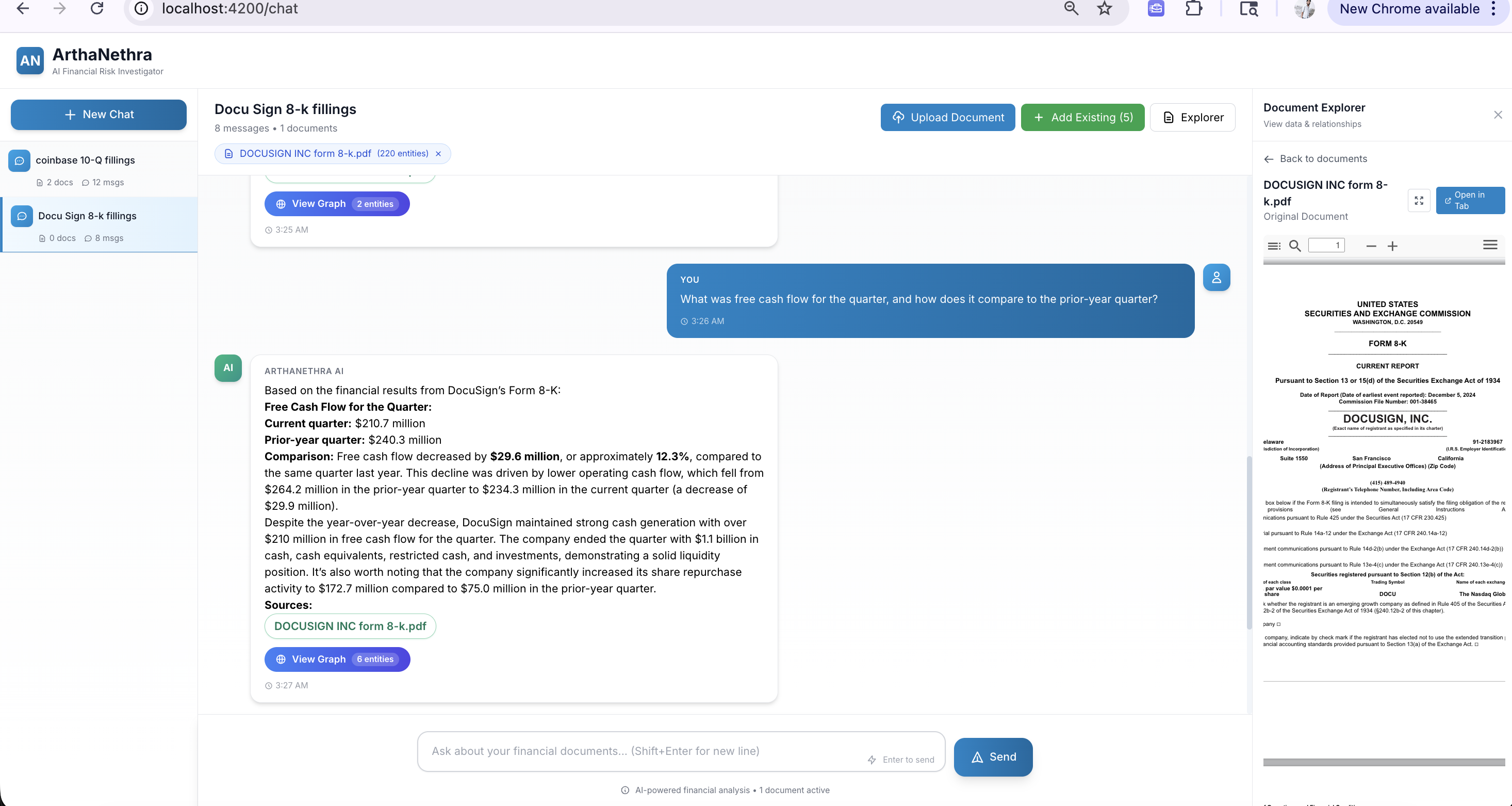
Citation capsule: ArthaNethra's chatbot enforces a document-search-first protocol: Claude Sonnet 4.5 must call
document_search()before answering any question. Seven additional tools —graph_traverse(),graph_path(),graph_pattern(),metric_compute()— allow multi-hop reasoning. Responses stream via Server-Sent Events with interactive Sigma.js graph visualizations and citations linking to the source PDF page.
Why Does the Dual-Database Architecture Matter?
ArthaNethra uses two databases because semantic search and graph traversal are fundamentally different operations. Using one engine for both forces compromises. Using both means each query type runs on the engine built for it.
Weaviate handles "find me documents about covenant violations" — semantic similarity over a vector index — with a dedicated sentence-transformers (all-mpnet-base-v2) sidecar running as a separate container for vectorization. Neo4j handles "show me all paths between Company X and Vendor Y through subsidiaries and loans" — graph traversal — with APOC procedures enabled.
This separation matters for cost, too. Structured documents (invoices, loan agreements, contracts) don't need an LLM for extraction. Deterministic parsers are faster, cheaper, and more predictable. The LLM handles what rules can't: narrative text, complex relationship inference, anomaly detection across entity patterns. Compare this against a pure LLM-only document extraction approach and the cost difference is significant.
LandingAI ADE solves the first hard problem: converting varied financial documents into structured output the rest of the system can use. For developers, that means less time building brittle OCR and parsing logic from scratch. For enterprise teams, it means a clearer path from raw documents to downstream investigation workflows.
Citation capsule: ArthaNethra uses dual-database storage. Weaviate with a sentence-transformers (
all-mpnet-base-v2) sidecar handles semantic search ("find documents about covenant violations"). Neo4j with APOC handles graph traversal ("show all paths between Company X and Vendor Y"). The knowledge graph market reaches $6.94B by 2030, with BFSI as the largest vertical (MarketsandMarkets, 2024).
What Makes This Useful for Enterprise Teams?
Three properties make this architecture useful in production-style workflows, even though the build itself is a hackathon prototype:
Citation-first design. Entities, risks, and chat answers retain links back to the source document, with page and section metadata where available. In enterprise settings, this isn't optional. If the workflow ends in audit, escalation, or analyst review, every answer needs an evidence trail. The frontend includes an integrated PDF viewer (ngx-extended-pdf-viewer) that opens directly to the cited page when an analyst clicks a citation.
Unified chat-first interface. The Angular 19 frontend consolidates the entire workflow into a single chat-first view. Document upload, entity exploration, graph visualization, risk analysis, PDF evidence, and AI chat all live in one component. The interface includes speech-to-text for voice input, text-to-speech for AI responses, entity flagging to filter the graph view, and fullscreen graph exploration modes. Risk distributions render as ECharts donut and bar charts alongside the Sigma.js graph.
One-command deployment. After environment variables are configured, five Docker containers (Weaviate, the all-mpnet-base-v2 transformer sidecar, Neo4j with APOC, FastAPI backend, Angular frontend) run from a single docker-compose up -d. Application state (documents, graphs, entities, chat sessions, risks) persists via a JSON-based persistence service to a Docker volume, so data survives container restarts without requiring a full RDBMS.
What we've seen: The biggest friction in financial investigation isn't analysis. It's assembly. Analysts spend most of their time building the picture, not interpreting it. A financial knowledge graph pre-assembles the picture from source documents, so analysts can start at the interpretation layer from the first minute.
Key Takeaways
- ArthaNethra is a hackathon prototype, not a finished enterprise product. Its value is as a working reference for how to turn flat financial documents into a graph-oriented investigation workflow, with a concrete tech stack (Angular 19, FastAPI, Neo4j, Weaviate, LandingAI ADE, AWS Bedrock) running from a single
docker-compose up -d. - LandingAI ADE works as the document processing intelligence layer — it gives the rest of the system a structured starting point instead of forcing developers to begin from raw PDFs. From there, deterministic parsers, LLM-based relationship detection, and a dual-database graph architecture turn that structured output into something analysts can traverse, query, and interrogate through natural language.
- Enterprise document workflows benefit from clear separation of responsibilities: parsing, normalization, graph storage, risk logic, and evidence-backed interaction. Every answer, every risk, every graph node traces back to a source document with page-level citations.
Try It and Talk to Us
Explore the build. Devi Eswar and Mohan Priya shipped the full prototype: source code on GitHub, the demo video, and a live deployment you can try.
Talk to LandingAI. Scoping a treaty intake or contract management workflow? Feel free to email us to discuss applying the same extraction pattern to your documents.
Frequently Asked Questions
What types of financial documents does ArthaNethra process?
The prototype works on the document families reflected in the repo: 10-Ks, 10-Qs, 8-Ks, loan agreements, invoices, contracts, receipts, emails, and general forms or tabular documents that ADE can parse into structured markdown. A DocumentTypeDetector classifies each upload and routes it to the right parser. Invoices, loans, and contracts each have dedicated deterministic parsers. Narrative filings (MD&A sections, risk disclosures) go through the narrative parser. The result is typed entities and relationships regardless of document format.
How does a financial knowledge graph differ from a traditional database?
A relational database stores records in tables. A financial knowledge graph stores entities as nodes and their relationships as typed edges, making it possible to traverse connections across documents. With 26 relationship types (OWNS, SUBSIDIARY_OF, GUARANTEES, HAS_LOAN, and more), the graph answers questions about structure that SQL queries handle poorly. BFSI is the largest vertical for knowledge graph adoption (MarketsandMarkets, 2024).
Can the system scale to hundreds of documents?
At the prototype level, the architecture is designed in that direction: Weaviate is built for large vector indexes (with a dedicated transformer sidecar for embedding generation), files over 15MB route through async extraction jobs with exponential backoff retry logic, and relationship detection is chunked 20 entities at a time to keep model costs bounded. Multi-document chat sessions maintain context across any combination of attached documents. Production scale would still need validation, observability, and hardening beyond the hackathon build.
What AI models power the extraction and reasoning?
LandingAI's ADE handles document parsing and structured extraction. Deterministic parsers handle structured invoices, loans, and contracts without any LLM calls. Claude 3.5 Haiku powers narrative extraction (organizations, monetary amounts, dates, relationships from prose), running at roughly 10× lower cost than Sonnet. Claude Sonnet 4.5 handles chat reasoning, risk analysis, and tool-calling workflows, with automatic fallback to Claude 3 Haiku when throttled. Weaviate's vectorization uses all-mpnet-base-v2 via a dedicated transformer sidecar.