How We Built LoanLens: AI Loan Document Processing
A case study on using LandingAI ADE and AOD to extract borrower documents, flag fraud, and speed the first pass of underwriting review.

TL;DR
- LoanLens automates the first pass of underwriting across six borrower documents: bank statements, credit reports, pay stubs, tax returns, identity documents, and utility bills.
- LandingAI is the core enabler. ADE handles schema-driven extraction and traceable outputs; AOD adds a visual signal for document tampering checks.
- LoanLens combines extraction, KPI calculation, fraud detection, scoring, decisioning, and case-scoped RAG in one workflow.
- It shows a realistic path from manual review pain to a system architecture teams can evaluate and extend.
In one sentence: LoanLens uses LandingAI ADE to extract structured fields from six borrower documents, LandingAI AOD to flag visual document tampering, and a case-scoped RAG layer to answer reviewer questions — producing an underwriting verdict in one automated pipeline.
Manual loan review breaks down on the same expensive, repetitive work: extracting names, income, balances, addresses, and identity details from a stack of borrower documents, then checking whether those facts agree with one another. In mortgage lending alone, origination cost reached $12,579 per loan in Q1 2025 (MBA), and personnel make up 67% of total origination costs (Freddie Mac). Fraud pressure is rising too: Point Predictive estimated $9.2 billion in auto lending fraud loss exposure for 2025 (Point Predictive).
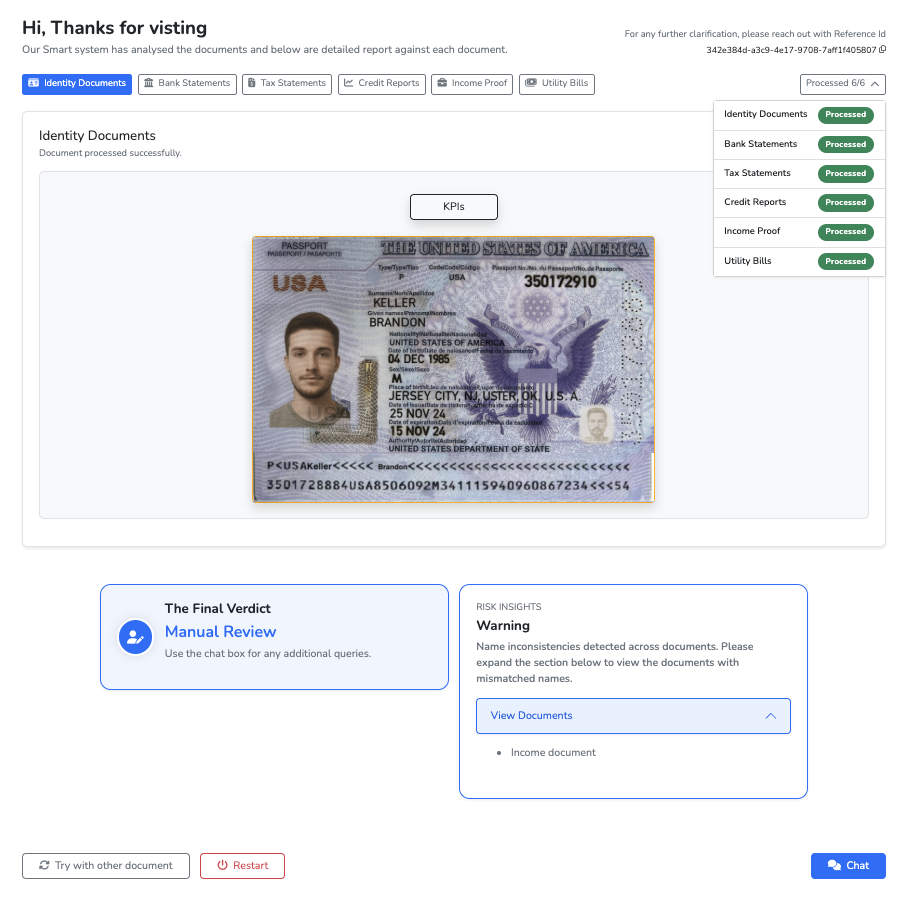
LoanLens was built with LandingAI to test a practical question: can AI handle the first pass of underwriting review in a way that is actually useful to operators, not just impressive in a demo? The system ingests six common borrower documents, uses LandingAI ADE to extract structured fields, uses LandingAI AOD to inspect passport layout, computes KPIs, flags inconsistencies, produces an approval or manual-review recommendation, and then creates a case-scoped RAG assistant for follow-up questions.
The value was not just text extraction. The real value was turning messy borrower files into structured, traceable evidence that could feed fraud checks, scoring logic, summaries, and reviewer workflows.
Why Is Manual Loan Review Still So Expensive?
What made this problem interesting to us was how ordinary it is. Underwriting teams are not usually blocked by one impossible modeling task. They are slowed down by repeated document comparison:
- Does the borrower name on the bank statement match the passport and credit report?
- Does the pay stub line up with deposits and tax data?
- Does the address stay consistent across identity and residency documents?
- Are there signs that an image was manipulated or that fields do not belong together?
That work is operationally important, but it is also exactly the kind of work that burns analyst time and invites inconsistency. At the same time, adoption is still early. In Fannie Mae's 2023 lender survey, only 7% of mortgage lenders said they had deployed AI and machine learning, even though 73% cited operational efficiency as the primary reason to adopt it.

That gap is what we wanted to make concrete. Instead of talking about AI in underwriting in abstract terms, we wanted to build a working system around one real pain point: document-heavy first-pass review.
Why Did We Choose LandingAI ADE Over Basic OCR?
LandingAI was part of the platform we built on. What changed during the build was our level of conviction. After using it in a document-heavy underwriting workflow, we came away feeling that we would choose it again for this kind of problem.
We did not need a generic model that could vaguely describe a PDF. We needed something better suited to operations:
- Schema-driven extraction: We wanted to tell the system exactly which fields mattered on each document type and receive typed outputs back.
- Traceability: Reviewers need to understand where extracted values came from, especially when a decision or a fraud flag is involved.
- Visual inspection: Some document problems are not purely textual. Layout, spacing, and component placement matter.
LandingAI ADE (Agentic Document Extraction) let us approach extraction as a schema problem instead of a template problem. For each borrower document, we could define the fields we cared about with Pydantic models and use those models to guide extraction.
LandingAI AOD (Agentic Object Detection) gave the system a second signal beyond text. In the passport flow, we used it to detect specific visual components and support a simple tampering heuristic based on document geometry.
In our experience, that combination performed better than the other products and approaches we had come across for this kind of document-heavy workflow. The useful part was not merely "the model can read the document." It was "the system can produce outputs that downstream underwriting logic can trust, inspect, and reason over."
How Does AI Loan Document Processing Work in LoanLens?
From the reviewer's point of view, the workflow is straightforward:
- Upload the borrower's six-document package.
- Extract structured fields with LandingAI ADE.
- Compute document-specific KPIs.
- Run fraud checks across text and images.
- Score the case and assign approved, manual_review, or rejected.
- Build a case-scoped RAG assistant so an underwriter can ask follow-up questions against that file only.
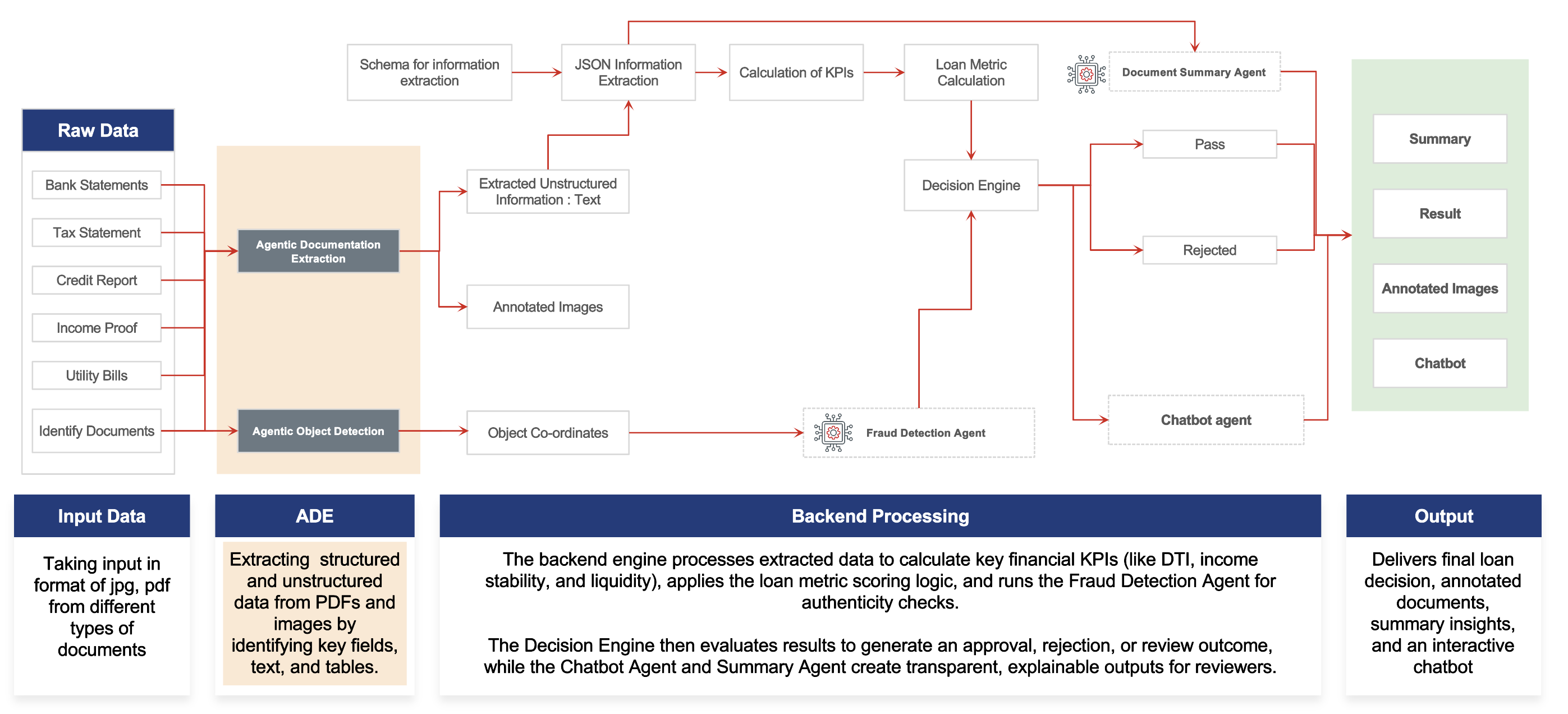
Under the hood, uploaded files are stored under backend/resources/<case_id>/<document_type>/, and the system persists outputs to the filesystem rather than a database. We made that tradeoff deliberately because it kept the system easy to run, inspect, and debug locally.
| Document | Example extracted fields | Example downstream use |
| Bank statement | account_holder_name, transactions_table | liquidity, debit-credit mix, transaction behavior |
| Credit report | vantage_score_3_0, delinquencies, accounts | credit quality and delinquency risk |
| Pay stub | gross_earnings_current, gross_earnings_ytd, net_pay_current | income recency and stability |
| Tax return (1040) | total_income, adjusted_gross_income, taxable_income | income normalization and cross-checks |
| Identity document | full_name, passport_number, expiry_date | identity verification and document validity |
| Utility bill | customer_name, billing history | residency and consistency checks |
What Makes the LandingAI Integration Actually Useful?
The strongest lesson from this project is that extraction alone is not enough. The workflow only became useful when the extracted outputs were clean enough to support later stages.
1. Schema-Driven Extraction With ADE
Each document type in LoanLens has its own Pydantic schema in schemas.py. Those schemas are not just validators after the fact. They are the contract that tells the extraction layer what matters.
- bank statements focus on account identity and transaction structure
- credit reports focus on score, delinquencies, and liabilities
- pay stubs focus on payroll and recency
- tax returns focus on income normalization
ADE returns three forms of output that the rest of the system uses differently:
- structured JSON for KPI logic and scoring
- markdown for summaries and header-aware retrieval
- parsed text for fallback search and chunking
That traceable output format was important. In underwriting, a field is more valuable when the reviewer can see where it came from and how it moved through the pipeline.
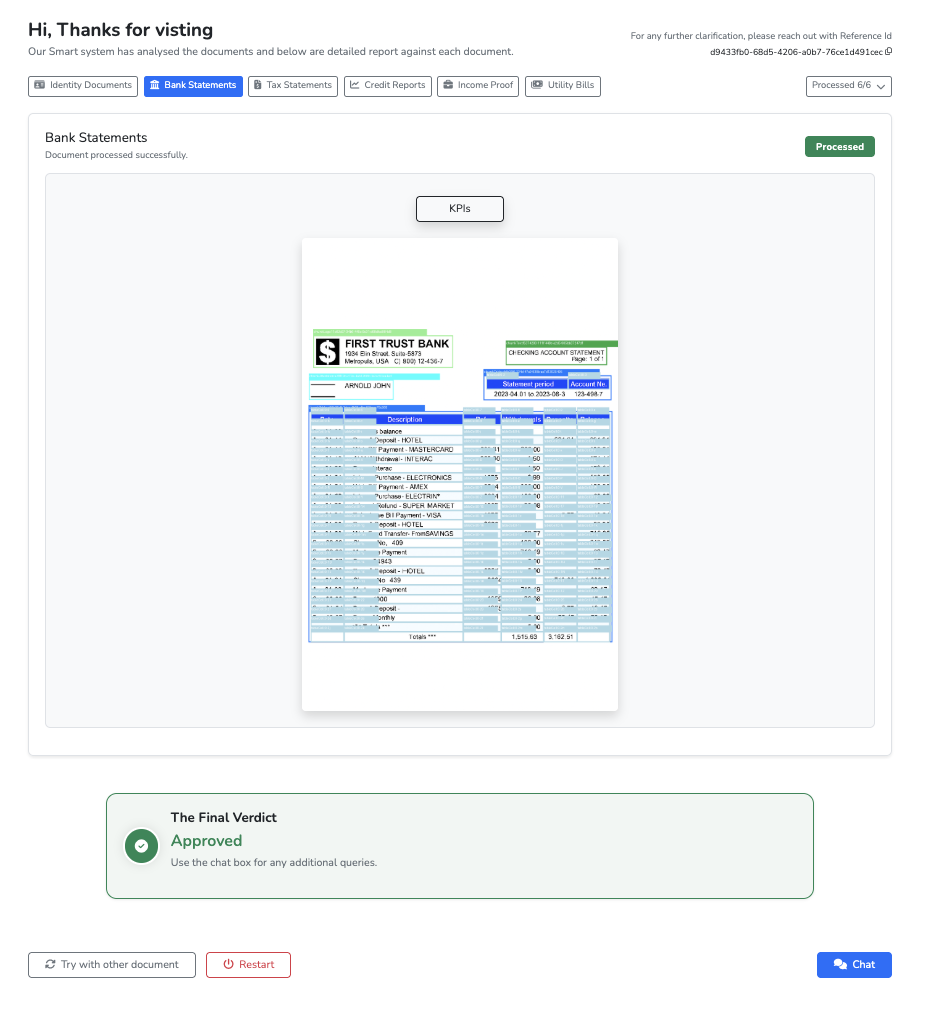
2. Fraud Checks That Go Beyond OCR
Once the documents were structured, we added two fraud layers.
The first is a cross-document name consistency check. FraudDetectionEngine collects borrower-name fields from all six document types, vectorizes them with TF-IDF, and flags mismatches when cosine similarity falls below 0.95. It is simple, but it surfaces a real operational problem: mixed identities across otherwise plausible-looking files.
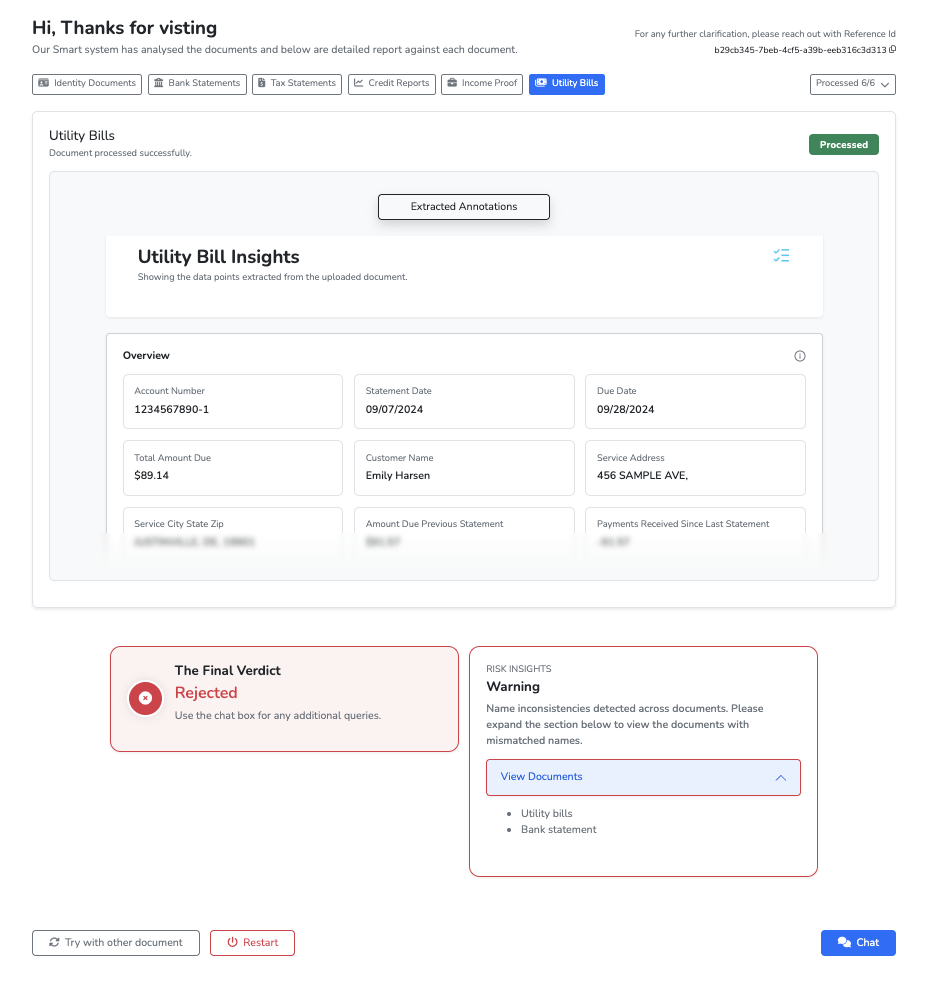
The second is a passport tampering check built on LandingAI AOD. PassportFraudDetector asks AOD to find three visual components on the passport:
- the MRZ
- the photo
- the eagle
It keeps the largest detected box for each component, then PassportFraudAnalyzer compares the normalized distances between them against stored reference geometry. In other words, the check is not "does this look vaguely passport-like?" It is "do these core components sit in the places we would expect on a normal document?"
That second layer is where AOD made the system feel materially different. It added a visual signal that pure text extraction would not catch.
3. Scoring And Decisioning That A Reviewer Can Inspect
After extraction and fraud checks, the system scores the case with LoanUnderwritingScorerSimple. The scoring model is intentionally simple and inspectable:
- credit: 23%
- debt-to-income: 23%
- income recency: 20%
- delinquency risk: 18%
- liquidity: 9%
Here is what that weighting looks like:

Smaller weights cover income consistency, employment stability, and residency stability. Final thresholds are also straightforward:
- 60+: approved
- 40-59: manual review
- below 40: rejected
Fraud overrides sit above the score. A serious image-fraud signal can reject a case immediately, while text-based inconsistencies push the file into manual review.
We like this part of the system because it stays honest. The logic is not hidden behind a single magic classification score. A reviewer can inspect which signals contributed to the decision and why.
4. Case-Scoped RAG For Underwriters
Once a case has been processed, reviewers still need to ask follow-up questions. That is where the RAG layer comes in.
LoanLens creates a separate FAISS index per case, chunks content into 800-character segments with 160-character overlap, embeds them with all-MiniLM-L6-v2, and answers through Amazon Nova Pro with a 12,000-character context budget. The key detail is that retrieval stays scoped to the current borrower file.
That constraint matters. A reviewer should not get a plausible answer pulled from another case or from general model knowledge. If the current case does not support the answer, the assistant returns a grounded no-answer response tied to the provided documents.
This part of the system is less about chat for its own sake and more about reducing reviewer friction after the underwriting decision has already been assembled.
What Did We Learn While Building LoanLens?
Building LoanLens clarified several production-level lessons.
Manual review pain is mostly reconciliation pain
The hard part is rarely one field on one file. The hard part is stitching borrower facts together across six documents and noticing when they stop agreeing.
Traceability matters almost as much as extraction quality
Even a strong extraction result becomes harder to trust if the reviewer cannot connect it back to the document. ADE's structured outputs and traceable document representations made the rest of the workflow more credible.
A lightweight architecture is useful early
Because the system persists data to the filesystem and builds per-case FAISS indices, it is easy to clone and run without setting up a full platform. That speed mattered during the build, and it also made the system easier to explain afterward.
The strongest value of LandingAI is operational, not cosmetic
This is the main point we would emphasize to anyone evaluating tools for document-heavy workflows. The win is not that you can say AI is in the pipeline. The win is that you can turn inconsistent, multi-format documents into signals that downstream business logic can actually use.
What Would a Production Version Require?
LoanLens is a working system and the path toward full production deployment has clear next steps. Naming them makes the architecture more useful to teams evaluating a similar build.
- move scoring weights and policy rules out of code and into configuration
- benchmark extraction and fraud performance against labeled review data
- add stronger audit controls, authentication, and case access boundaries
- replace local filesystem persistence with more production-ready storage and workflow orchestration
- add reviewer feedback loops to tune thresholds and reduce false positives
The economics make this worth pursuing. Freddie Mac has cited up to 40% cost savings for a fully digitized mortgage process, while the MBA reported $12,579 as the average cost to originate a mortgage in Q1 2025 (Freddie Mac, MBA). If a lender can automate document extraction, reduce reconciliation work, and route edge cases into cleaner manual review queues, the operational upside is real across mortgage, auto, personal, and small-business lending.
LandingAI is most useful in this kind of workflow when the work starts with messy business documents, the output has to be structured enough for downstream logic, reviewers need traceability rather than text blobs, and visual layout and tampering checks matter alongside extraction. That is why LoanLens shows more than a proof of concept — it shows how LandingAI can sit inside an actual decision workflow, not just at the edges of one.
Key takeaways:
- AI loan document processing becomes useful when it reduces reconciliation work, not just when it reads text from PDFs.
- LandingAI ADE was the backbone of this build because schema-driven extraction made the rest of the system possible.
- LandingAI AOD added a valuable second signal for document fraud checks that text-only pipelines would miss.
- The implementation is lightweight by design, but the architectural pattern is relevant to real underwriting operations.
The full source code is on GitHub and the end-to-end demo is on YouTube. If you are evaluating document-heavy workflows, the first question to ask is not "can AI read this file?" It is "can AI turn this file into structured, reviewable evidence that a workflow can act on?" That is where LandingAI proved useful in this build.
FAQ
What problem does AI loan document processing solve in underwriting?
It reduces the manual work of extracting, comparing, and reconciling borrower facts across multiple files. Instead of making underwriters re-check names, income, balances, addresses, and identity details by hand, the system structures those facts early and surfaces mismatches before full manual review.
Why use LandingAI instead of basic OCR for loan underwriting automation?
Because the job is not just reading text. In this build, LandingAI ADE produced schema-aligned outputs that downstream scoring and fraud logic could use, while LandingAI AOD added a visual inspection signal for tampering checks. That combination was materially more useful than plain OCR text alone.
What does LoanLens do end to end?
It ingests six borrower document types, extracts structured data with LandingAI ADE, computes KPIs, runs fraud checks, scores the case, and assigns an underwriting recommendation. It then creates a case-scoped RAG assistant so reviewers can ask follow-up questions against that borrower file only.
How does fraud detection work in LoanLens?
It uses two layers. One checks cross-document name consistency with TF-IDF and cosine similarity to catch identity mismatches. The other uses LandingAI AOD to detect key passport components and compare their geometry against expected layout patterns, which helps surface visual tampering that text extraction would miss.