



This article first appeared in IndustryWeek.
As manufacturers begin to integrate AI solutions into production lines, data scarcity has emerged as a major challenge. Unlike consumer Internet companies, which have data from billions of users to train powerful AI models, collecting massive training sets in manufacturing is often not feasible.
For example, in automotive manufacturing, where lean Six Sigma practices have been widely adopted, most OEMs and Tier One suppliers strive to have fewer than three to four defects per million parts. The rarity of these defects makes it challenging to have sufficient defect data to train visual inspection models.
In a recent MAPI survey, 58% of research respondents reported that the most significant barrier to deployment of AI solutions pertained to a lack of data resources.
Technologies to circumvent the small data problem
Big data has enabled AI in consumer internet companies. Can manufacturing also make AI work with small data? In fact, recent advances in AI are making this possible. Manufacturers can use the following techniques and technologies to circumvent the small data problem to help their AI projects go live even with only dozens or fewer examples:
Synthetic data generation is used to synthesize novel images that are difficult to collect in real life. Recent advances in techniques such as GANs, variational autoencoders, domain randomization and data augmentation can be used to do this.
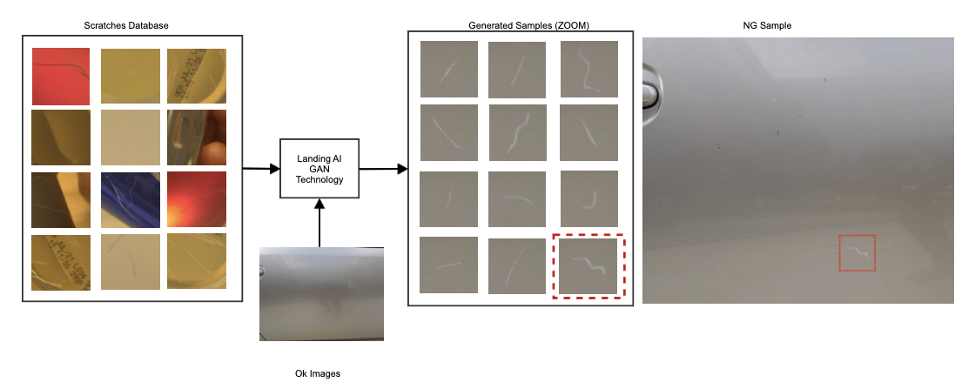
These images show synthetically generated surface scratch data using LandingAI’s proprietary AI technologies. These scratches were transferred from a scratch database and then layered on a clean metal surface. Using synthetic data, manufacturers can train powerful visual inspection models for tasks like defect detection even with a very small number of defect datasets.
Transfer learning is a technique that enables AI to learn from a related task where there is ample data available and then uses this knowledge to help solve the small data task. For example, an AI learns to find dents from 1,000 pictures of dents collected from a variety of products and data sources. It can then transfer this knowledge to detect dents in a specific novel product with only a few pictures of dents.
Self-supervised learning: Similar to transfer-learning. but the obtained knowledge is acquired by solving a slightly different task and then adapted to small data problem. For example, you can take a lot of OK images and create a puzzle-like grid to be sorted by a base model. Solving this dummy problem will force the model to acquire domain knowledge that can be used as starting point in the small data task.
In few-shot learning, the small-data problem is reformulated to help the AI system to learn an easier, less data hungry inspection task while achieving the same goal. In this scenario, AI is given thousands of easier inspection tasks, where each task has only 10 (or another similarly small number) examples. This forces the AI to learn to spot the most important patterns since it only has a small dataset. After that, when you expose this AI to the problem you care about, which has only a similar number of examples, its performance will benefit from it having seen thousands of similar small data tasks.
One-shot learning is a special case of few-shot learning where the number of examples per class it has to learn from is one instead of a few (as in the example above).
In anomaly detection, the AI sees zero examples of defect and only examples of OK images. The algorithm learns to flag anything that deviates significantly from the OK images as a potential problem.
Hand-coded knowledge is an example in which an AI team interviews the inspection engineers and tries to encode as much of their institutional knowledge as possible into a system. Modern machine learning has been trending toward systems that rely on data rather than on human institutional knowledge, but when data isn’t available, skilled AI teams can engineer machine learning systems that leverage this knowledge.
Human-in-the-loop describes situations where any of the techniques listed above can be used to build an initial, perhaps somewhat higher error system. But the AI is smart enough to know when it is confident in a label or not and knows to show it to a human expert and defer to their judgement in the latter case. Each time it does so, it also gets to learn from the human, so that it increases accuracy and confidence in its output over time.
By using a combination of these approaches, manufacturers can build and deploy effective visual inspection models trained on as few as 10 examples. Building systems with small data is important for breaking over millions of use cases in which only small datasets are available. For manufacturers, this minimizes the time, engineering effort, and data required to go live and create practical value from AI.


