Long Extraction Schemas Solved
How we solved common failure points as documents get more complex and extraction schemas get longer

TL;DR
Production document extraction systems fail predictably. They fail when the files get long, the schema gets large, tables span pages, field labels shift across suppliers, and nobody can verify where a value came from.
The Agentic Extract APIs in Agentic Document Extraction (ADE) are built for that production reality. Each API works at a different phase in the pipeline:
- Build time: Use the Schema Building API to generate or refine a master schema from representative documents.
- Inference time: Use the ADE Extract API to apply the schema to a document. The API returns structured data with chunk reference IDs linking every extracted value back to the parsed document.
There's no need to manually split documents or maintain brittle templates. You also get a clear audit trail when something needs verification.
The Problem: Why Extraction Breaks in Production
A procurement team processes invoices from 30 suppliers. Each one has different formatting — different field names, different table layouts, different date formats. One labels a column "Payment Terms," another calls it "Net 30," another buries it in a footnote. The extraction returns data, but the pipeline still breaks because every supplier is a special case.
The Agentic Extract APIs in ADE are designed for that reality.
Agentic Extraction Capabilities
The Agentic Extract APIs are built for the complex documents that would otherwise break extraction in production. They preserve the full structure, handle vendor variation, and process at scale without the code stitching and manual workarounds that most pipelines require.
- Infinite Schema (10+ Levels Deep)
The ADE Extract API returns a full document hierarchy as nested JSON — invoices, contracts, financials with all sub-structures intact. No data loss from deep structures. - Master Schema
The schema building API ingests multiple documents and produces one unified schema that handles field and layout variation from day one. One schema, all document variation. - Cross-Page Table Reconstruction
The ADE Extract API reconstructs multi-page tables as one array with headers, rows, and columns intact. - Long document support
One API call processes the full document — no splitting, no stitching. Full document, single call. Learn more. - Schema Drift Detection
Run the schema building API against updated documents to surface new or changed fields before they reach your pipeline. Version forward, not debug backward. Catch breaks before production. Learn more. - Semantic Field Matching
The ADE Extract API matches on meaning, such as "Payment Terms" and "Net 30", resolving to a single, consistent field in your schema regardless of what your vendors call it.
One Workflow, Two Phases
The API handles schema building and extraction as two separate steps. You define the schema once, then extract against it repeatedly.
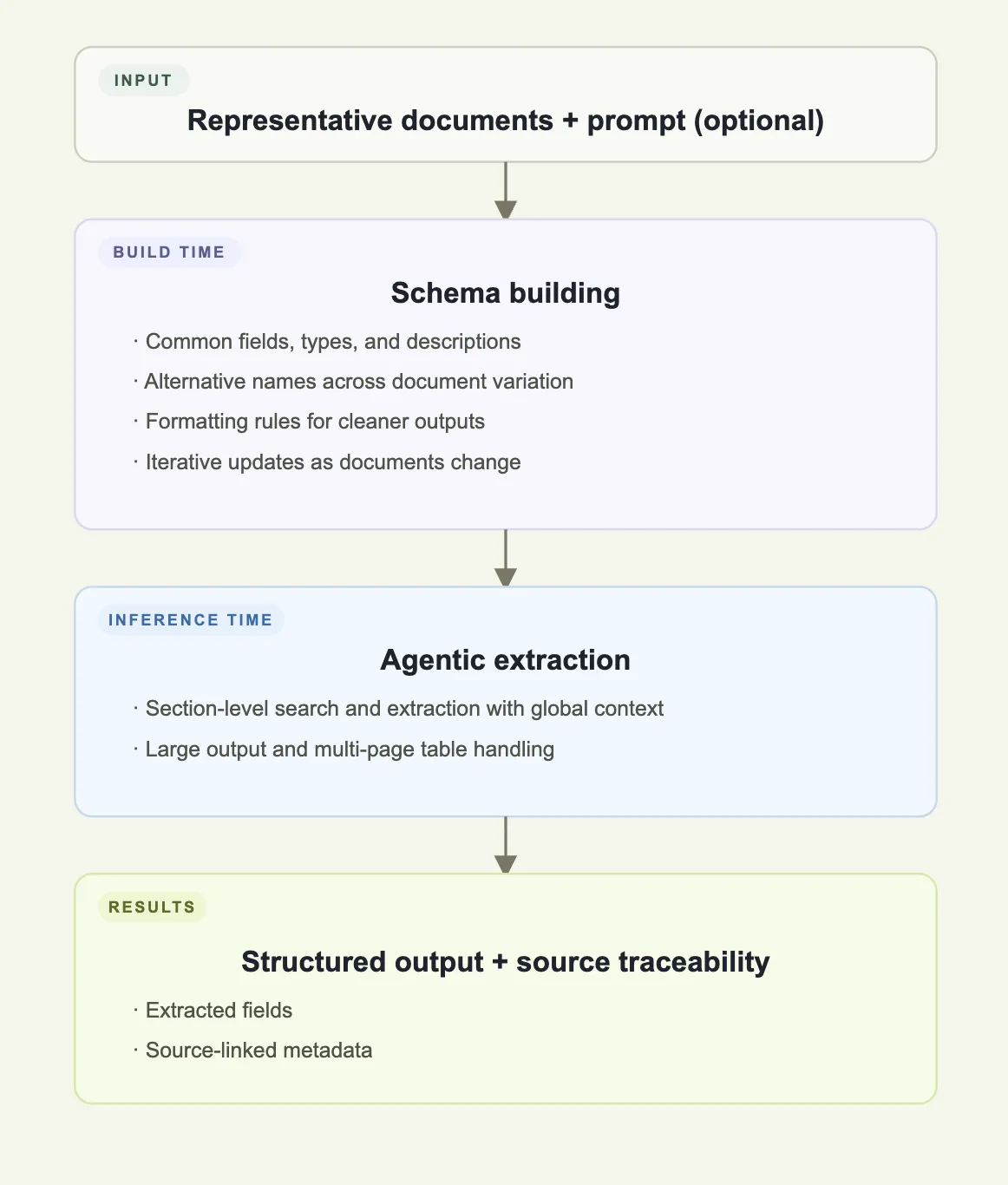
Here are the APIs for an extraction workflow, from representative documents to schema building, and extraction:
| Phase | Endpoint | What you send | What you get back |
|---|---|---|---|
| Build time | POST /v1/ade/extract/build-schema | Parsed documents, a prompt, an existing schema, or any combination | An extraction schema and metadata |
| Inference time | POST /v1/ade/extract | One parsed Markdown document and a schema | The extracted key-value pairs and metadata |
Example: A Procurement Team Processing 30 Suppliers
Here's an example of how one workflow plays out end-to-end.
Build time. A procurement team feeds a representative batch of invoices into the ADE Build Extract Schema API. The schema builder generates a master schema across all 30 suppliers, mapping variations like "Payment Terms," "Net Days," and unlabeled footnotes to unified fields through alternative labels. The API sets formatting guidance so dates, currencies, and quantities normalize, regardless of how each supplier formats them.
Inference time. New invoices arrive. A 40-page contract with line items spanning five pages returns as one unified table.
Six months later. A new supplier shows up. The team feeds the following into the ADE Build Extract Schema API: the new invoices, their existing schema, and a prompt to identify what changed. The API proposes updates. They review, approve, and version. The pipeline keeps running.
Try Your Documents Today
Try out your document on va.landing.ai for quick validation and testing.
Start Building With the API
Resources
- API Docs — Full endpoint reference
- Discord community — Community support
- Demo — 2-min Playground walkthrough