Overview: What You’ll Learn
- Building chat-apps using Agentic Document Extraction Python library
- Features of Agentic Document Extraction Python library
- Parse PDFs at scale with a single function call—no manual chunking required
- Speed up your existing “Chat with PDF” setup through built-in concurrency
- Pinpoint every chunk’s bounding box for highlight overlays or snippet extraction
- Explore advanced options (visual debugging, parallel processing, cropping)
- Decide when you’d still prefer raw REST calls in specialized scenarios
Complete code for the tutorial is available on GitHub — follow along and run the example app yourself👨🏼💻.
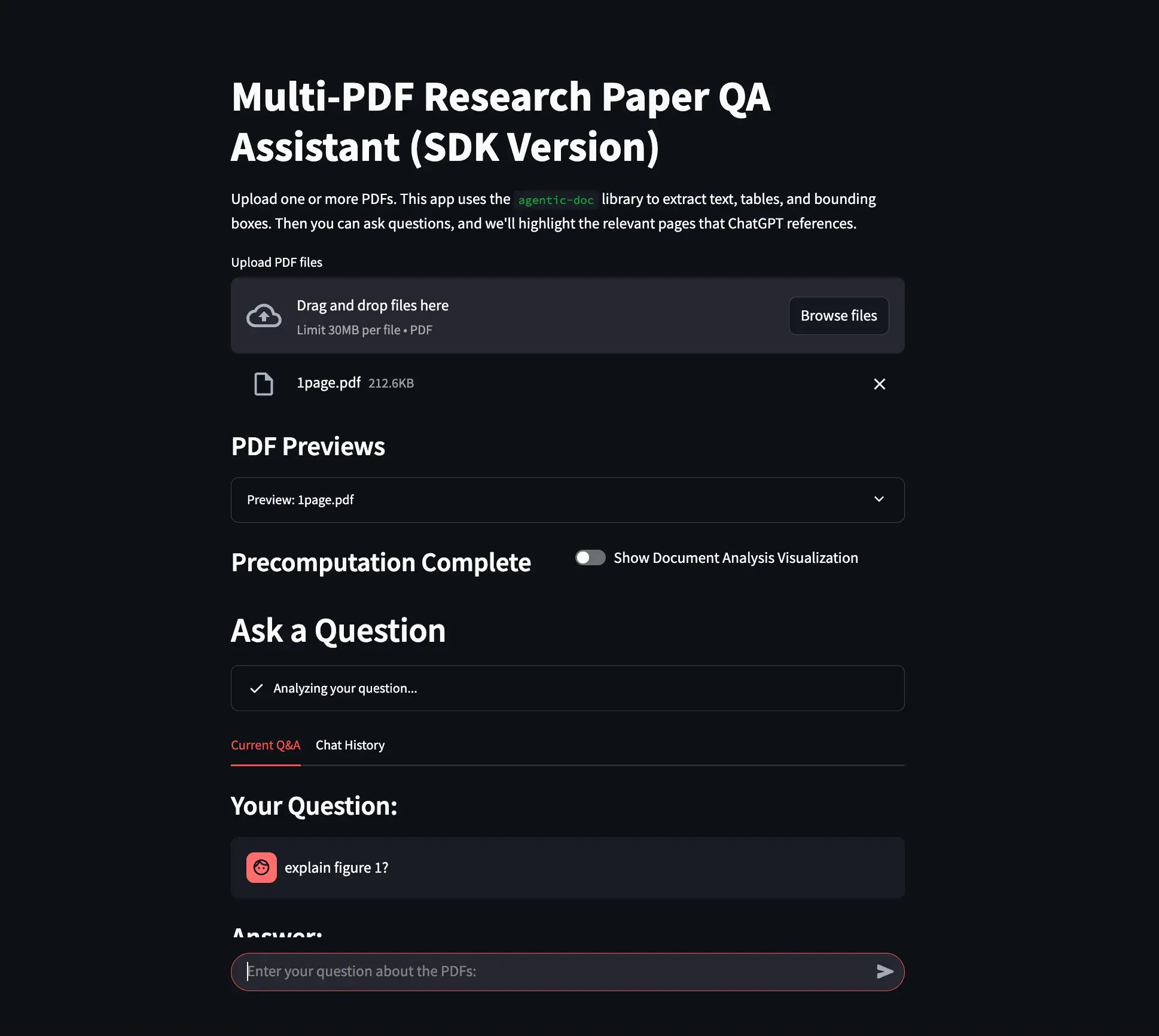
Figure 1: A simple “Chat with PDF” app. The user has uploaded a PDF and the Agentic Document Extraction Python library has precomputed structured data for each page.
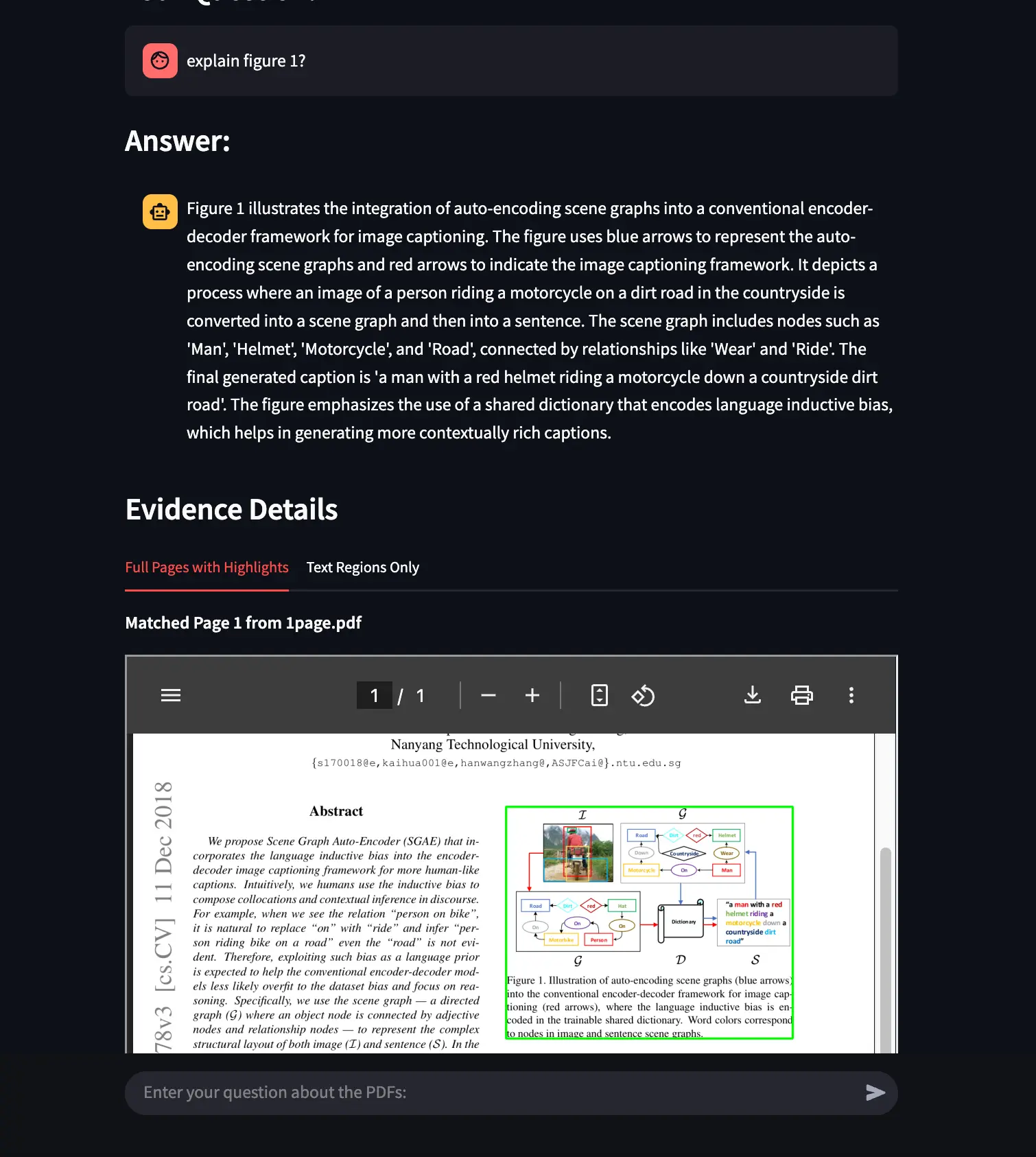
Figure 2: The app’s response to a question, with visually grounded answers. The relevant excerpt on the PDF is highlighted, and the answer is cited with its page reference.

Figure 3: The app also displays the reasoning (chain-of-thought) used to generate the answer, giving transparency into how the conclusion was reached.
1. Introduction
In our previous blog post, we built a “Multi-PDF Chat with Research Papers” application by calling the Agentic Document Extraction API directly with REST. We manually:
- Split PDFs into chunks
- Managed concurrency and retries
- Stitched partial JSON responses
- Calculated bounding-box transformations
While this taught us the fundamentals, it was also quite labor-intensive—especially for large or numerous PDFs. Today, we’ll see how we upgraded the same application with the official Agentic Document Extraction Python library, which elegantly wraps this functionality (and more) in just a few function calls. We removed hundreds of lines of “infrastructure” code, gained extra features like bounding-box snippet images and visual debugging, and now parse multi-hundred-page PDFs with minimal effort.
2. Features of Agentic Document Extraction Python Library
- Automatic Large File Handling
- Instead of manually chunking a 200-page PDF, you just call
parse_documents([pdf_file]). The library splits, merges, and returns a single, consolidated result.
- Instead of manually chunking a 200-page PDF, you just call
- Built-In Parallelism
- Tune concurrency by setting
BATCH_SIZE×MAX_WORKERSvia.env. No manualThreadPoolExecutoror concurrency loops needed.
- Tune concurrency by setting
- Structured Chunks with Groundings
- Each chunk includes bounding box references (
grounding) that pinpoint the exact location of the extracted text. Perfect for highlight overlays.
- Each chunk includes bounding box references (
- Retry & Error Handling
- Automatic exponential backoff for 429 (rate limit) or 5xx responses—no custom logic required. If a page can’t be parsed, it’s returned as an “error chunk” instead of crashing your app.
- Extras:
- Cropping bounding box regions to disk (
grounding_save_dir). - Visualizing chunk bounding boxes in annotated images (
viz_parsed_document). - Parsing multiple files or even remote URLs in a single function call.
- Cropping bounding box regions to disk (
In other words, the library frees us from having to babysit the PDF → JSON pipeline, so we can focus on building features instead of writing boiler plate code.
3. Upgrading Our “Chat with PDF” App
3.1 Before: Manual REST
Recall that we originally:
- Split each PDF into multiple 2-page buffers to fit the REST endpoint’s limit.
- Parallelized calls with a custom thread pool.
- Reconstructed partial JSON results for each chunk.
- Transformed bounding box coordinates from PDF to image space.
This worked, but it was cumbersome—especially for 50+ page documents.
3.2 After: One-Call Parsing
Here’s the core of our new approach, replacing all of that chunking logic:
from agentic_doc.parse import parse_documents
def parse_pdf_with_agentic(file_stream):
"""
Uses the agentic-doc SDK to parse a PDF in memory.
Returns a page-based map of {page_number: [chunks]} for further processing.
"""
# parse_documents() can handle file-like objects or file paths/URLs
results = parse_documents([file_stream])
parsed_doc = results[0]
page_map = {}
for chunk in parsed_doc.chunks:
for grounding in chunk.grounding:
# grounding.page is 0-based, let's use 1-based indexing
page_idx = grounding.page + 1
page_map.setdefault(page_idx, [])
# Convert (l, t, r, b) → (x, y, width, height)
box = grounding.box
x1, y1 = box.l, box.t
w, h = box.r - box.l, box.b - box.t
page_map[page_idx].append({
"bboxes": [[x1, y1, w, h]],
"captions": [chunk.text], # the extracted text
# You can store chunk.chunk_type or chunk.chunk_id if needed
})
return page_map
That’s it. No explicit concurrency, no partial chunk merges—the library handles all that under the hood.
4. Working with the SDK’s Advanced Features
4.1 Parallelism & Error Handling
- Parallelism is set via environment variables:
BATCH_SIZE=4 # parse up to 4 files at once
MAX_WORKERS=5 # each file gets up to 5 parallel requests
Retries for rate-limits or network errors are automatic. Configure them in .env:
MAX_RETRIES=80
MAX_RETRY_WAIT_TIME=30
RETRY_LOGGING_STYLE=inline_block
If the library can’t parse certain pages, you’ll get chunk_type=error in the result. This means you can skip or handle them gracefully in your app.
4.2 Cropping Groundings to Disk
If you want small PNG images of each chunk’s bounding box, just specify grounding_save_dir:
results = parse_documents(
[pdf_file],
grounding_save_dir="my_crops"
)
for chunk in results[0].chunks:
for grounding in chunk.grounding:
if grounding.image_path:
print("Saved snippet to:", grounding.image_path)
Now each bounding box region is extracted as a separate image. This is super helpful for debugging table extraction or verifying text alignment.
4.3 Visualization
Instead of manually writing bounding-box overlay code, you can generate annotated pages with one function:
from agentic_doc.utils import viz_parsed_document
from agentic_doc.config import VisualizationConfig, ChunkType
images = viz_parsed_document(
"some_doc.pdf",
results[0], # The ParsedDocument
output_dir= "viz_output",
viz_config=VisualizationConfig(
thickness=2,
font_scale=0.8,
# Color certain chunk types differently
color_map={
ChunkType.TITLE: (255, 0, 0), # red
ChunkType.TABLE: (0, 255, 0), # green
}
)
)
You’ll get one annotated image per PDF page, with color-coded boxes and chunk labels. Perfect for visually confirming the extraction accuracy.
4.4 Batch Parsing
Need to parse many PDFs in a batch? Use parse_and_save_documents(), which:
- Processes each file in parallel (up to your
BATCH_SIZE). - Writes the results to JSON on disk, automatically naming them.
from agentic_doc.parse import parse_and_save_documents
pdf_list = ["doc1.pdf", "doc2.pdf", "https://example.com/doc3.pdf"]
json_paths = parse_and_save_documents(pdf_list, result_save_dir="parsed_results/")
print("Saved JSON to:", json_paths)
5. Integrating with Our “Chat with PDF” Flow
We still do the same question-answer approach:
- Extract PDF text + bounding box data with
agentic-doc. - Feed this structured JSON to GPT, instructing it to return “best chunks” that support its answer.
- Highlight those bounding boxes on each page.
But now we’ve eliminated all the custom chunk management code—the library has done it for us. This dramatically reduces the chance of subtle concurrency bugs or partial merges failing.
6. When Might I Still Use Raw REST?
While the SDK is recommended for nearly all Python-based projects, there are a few cases where you might still prefer direct REST calls:
- Non-Python Ecosystem: If your app is written in Node.js, Go, or another language, you won’t have the Python SDK.
- Ultra-Lightweight Environments: For extremely resource-constrained serverless functions (where you can’t install additional libraries), a simple
requests.post()might suffice. - Custom Experimental Endpoints: If you need to try brand-new or experimental parameters not yet exposed by the SDK. In that scenario, you might manually call the endpoint with the advanced parameter set.
That said, for any Python project—especially if you value concurrency and ease of code maintenance—the SDK is a clear winner.
7. Results and Performance Gains
In our tests, replacing the old REST approach in the same “Chat with PDF” app:
- Shrank our “PDF parsing” code by ~70%.
- Reduced parse time for large PDFs (100+ pages) by up to 50% due to built-in concurrency that’s smarter about partial merges and retry.
- Improved reliability. With automatic backoff and consistent error reporting (including error chunks), we saw far fewer “failed parse” issues.
We also love the built-in grounding_save_dir option for debugging tricky layout documents. Whenever a user complains “it missed this figure,” we quickly check the snippet images to see how it was interpreted.
8. Conclusion & Next Steps
With a single library, you can parse visually complex documents, produce visually grounded answers, and free yourself from the overhead of raw REST calls. We hope this saves you a bunch of headaches and a lot of time while developing your applications. If you have questions or feedback, feel free to reach out—happy to help! Also, be a part of the best Visual AI discord community and hangout with us there.
Important Resources
Sign up for the platform: Landing AI Platform
Example App GitHub Repo: Full source code for the Streamlit QA app
Agentic Document Extraction Python Library Docs: Repository that contains python library code
Get your API key: Steps to get your LandingAI API key
Rest API doc: Documentation for REST API