
In this tutorial, we introduce a workflow that helps you obtain accurate structured information from unstructured lab reports. Your report with complex formats gets zero shot parsed into a hierarchical rich JSON with visual cues and layout information intact plus enriched with visual grounding data. Then we run a schema-guided extraction to extract specific data fields. This workflow will enable you to perform further analysis or ship downstream to dashboards and databases. We will use the agentic_doc Python library, which wraps Landing AI’s Agentic Document Extraction (ADE) API. ADE is designed for visually complex documents and returns not only text but also layout-aware structure and coordinates for visual grounding. That means you can verify that each extracted value really came from the right place in the PDF.
Clinical and diagnostic labs often share results as PDFs or images. Those files are easy for humans to read but difficult for AI systems to process. Teams often copy values like “Haemoglobin” or “RBC count” into spreadsheets by hand, which is slow and error prone. In this tutorial, we will take such a report and convert it into structured data.
Here is the complex lab report we will be working on:
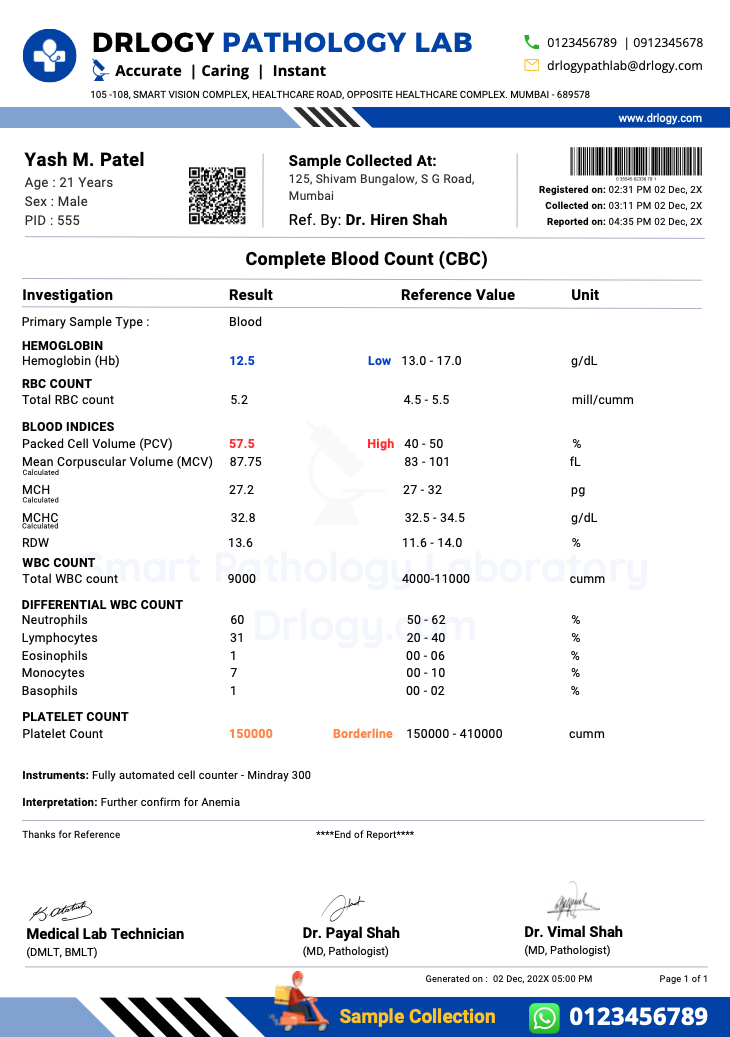 sample CBC lab report PDF
sample CBC lab report PDF
The document contains both structured and unstructured information, including patient details, reference ranges, highlighted values, tables, and annotations. We will transform this into clean, machine-readable tables while preserving accuracy and context.
The workflow is simple:
Parse one or more documents
Define the exact fields you want with a Pydantic schema
Run schema-guided extraction
Inspect where each field came from
Save results to CSV
We will use the agentic_doc Python library, which wraps Landing AI’s Agentic Document Extraction (ADE) API. ADE is designed for visually complex documents and returns not only text but also layout-aware structure and coordinates for visual grounding. That means you can verify that each extracted value really came from the right place in the PDF.
What you will build
By the end, you will have a Colab notebook that:
Parses PDFs or images of CBC lab reports
Extracts a custom set of fields such as patient name, lab name, hemoglobin, and RBC count
Shows which page and bounding box each value came from
Saves a clean CSV you can load into any analytics pipeline
Prerequisites
A Google Colab environment or local Python setup
Your Landing AI Vision Agent API key (from the ADE Playground settings)
Example PDFs or images of lab reports (
.pdf,.png,.jpg,.jpeg)
Install dependencies:
pip install agentic-doc pillowSet the API key in Colab:
from getpass import getpass
import os
os.environ["VISION_AGENT_API_KEY"] = getpass("Enter your API key: ")The agentic_doc library handles the heavy lifting and exposes a parse() function that parses documents, saves visual groundings, and can return rich Python objects for inspection.
Step 1: Organize inputs and outputs
Create folders for inputs and results so runs stay tidy and reproducible.
import os
from pathlib import Path
base_dir = Path(os.getcwd())
# Define folders
input_folder = base_dir / "input_folder" # Drop PDFs/images here
results_folder = base_dir / "results_folder" # JSON, CSV
groundings_folder = base_dir / "groundings_folder" # Visual crops
# Create folders if they don’t exist
for p in [input_folder, results_folder, groundings_folder]:
p.mkdir(parents=True, exist_ok=True)Collect only supported files:
file_paths = [
str(p) for p in input_folder.iterdir()
if p.suffix.lower() in [".pdf", ".png", ".jpg", ".jpeg"]
]Step 2: Parse documents
Call parse() to transform documents into structured outputs with optional visual groundings and metadata.
from agentic_doc.parse import parse
parse_result = parse(
documents=file_paths,
result_save_dir=str(results_folder),
grounding_save_dir=str(groundings_folder),
include_marginalia=True,
include_metadata_in_markdown=True,
)Under the hood, the API identifies elements like text, tables, and forms and returns a hierarchical representation with page and coordinate references. This goes beyond basic OCR to capture layout context and relationships.
Tip: You can also centralize options with [ParseConfig](https://docs.landing.ai/ade/ade-parseconfig) for cleaner code as projects grow.
Step 3: Define a Pydantic schema for the fields you care about
Schema-first extraction keeps results consistent across different templates and layouts. You decide exactly which fields should appear in the output row.
For example, in this medical lab report we will be extracting patient name, patient age, sample type, referring doctor, lab name, hemoglobin value, hemoglobin status, RBC count value, and RBC count unit. By defining these in a Pydantic schema, you ensure every document is parsed into the same structured format, even if the layouts differ.
from typing import Optional
from pydantic import BaseModel, Field
class CBCLabReport(BaseModel):
# Patient Information
patient_name: str = Field(description="Full name of the patient")
patient_age: str = Field(description="Age of the patient with units (e.g., '21 Years')")
# Sample and Report Information
referring_doctor: str = Field(description="Name of the referring doctor (Ref. By)")
sample_type: str = Field(description="Primary sample type (e.g., Blood)")
# Laboratory Information
lab_name: str = Field(description="Name of the pathology laboratory")
pathologist_name: str = Field(description="Name and qualification of the pathologist")
# Hemoglobin
hemoglobin_value: float = Field(description="Hemoglobin (Hb) value")
hemoglobin_status: Optional[str] = Field(description="Status if abnormal (Low/High)")
# RBC Count
rbc_count_value: float = Field(description="Total RBC count value")
rbc_count_unit: str = Field(description="Unit for RBC count")Now pass the schema to parse() to run field extraction:
result_fe = parse(
documents=file_paths,
grounding_save_dir=str(groundings_folder),
extraction_model=CBCLabReport
)If your organization later needs more fields, extend the schema and rerun. The API aligns extraction to your structure without template rules or model training.
Step 4: Inspect results and verify where values came from
Each parsed document includes:
“markdown” a human-readable summary
“chunks” elemental units such as text blocks, figures, tables
“extraction” a Pydantic object with your field values
“extraction_metadata” references to the chunks that yielded each field
doc = result_fe[0]
print("Document Type:", doc.doc_type)
print("Result Path:", str(doc.result_path))
print("Markdown preview:", doc.markdown[:120])
# Count chunks and peek at a few
print("Total chunks:", len(doc.chunks))
print("First chunk type:", doc.chunks[0].chunk_type.value)
print("First chunk text sample:", doc.chunks[0].text[:120].replace("\n", " "))
# Field values
print("Patient:", doc.extraction.patient_name)
print("Hemoglobin:", doc.extraction.hemoglobin_value, doc.extraction.hemoglobin_status or "")
# Where did those values come from?
print("Patient references:", doc.extraction_metadata.patient_name.chunk_references)
print("Hemoglobin references:", doc.extraction_metadata.hemoglobin_value.chunk_references)Those chunk references include page and bounding box data. You can even draw overlays to visualize groundings for quality checks and debugging.
Step 5: Convert to a table and save as CSV
Turn the extracted objects into a dataframe for analytics or integration.
import pandas as pd
from pathlib import Path
records = []
for i, d in enumerate(result_fe):
body = d.extraction
meta = d.extraction_metadata
records.append({
"document_name": Path(file_paths[i]).name,
"patient_name": body.patient_name,
"patient_age": body.patient_age,
"referring_doctor": body.referring_doctor,
"sample_type": body.sample_type,
"lab_name": body.lab_name,
"pathologist_name": body.pathologist_name,
"hemoglobin_value": body.hemoglobin_value,
"hemoglobin_status": body.hemoglobin_status,
"rbc_count_value": body.rbc_count_value,
"rbc_count_unit": body.rbc_count_unit,
# Provenance for auditing
"patient_name_ref": meta.patient_name.chunk_references,
"hemoglobin_value_ref": meta.hemoglobin_value.chunk_references,
"rbc_count_value_ref": meta.rbc_count_value.chunk_references,
})
df = pd.DataFrame(records)
csv_path = results_folder / "cbc_output.csv"
df.to_csv(csv_path, index=False)
print("Saved:", csv_path)Now you have a clean dataframe that includes both values and provenance.
Conclusion
This approach works because you’re not locked into brittle templates. Instead, you define a schema that captures the business entities you care about, while the parser understands layout, tables, and visual context.
The same pattern generalizes to other domains, as demonstrated in recent applications such as:
To explore more recipes and production setups, the ADE documentation provides full end-to-end workflow examples.
What’s Next
Explore the new credit-based pricing plans plans here
Brand new series – Will It Extract?